 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Event Detection Transformer: An Event-based End-to-End Model for Sound Event Detection
Paper and Code
Oct 18, 2021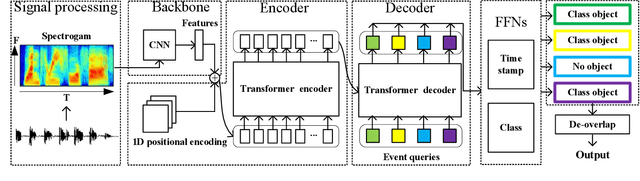

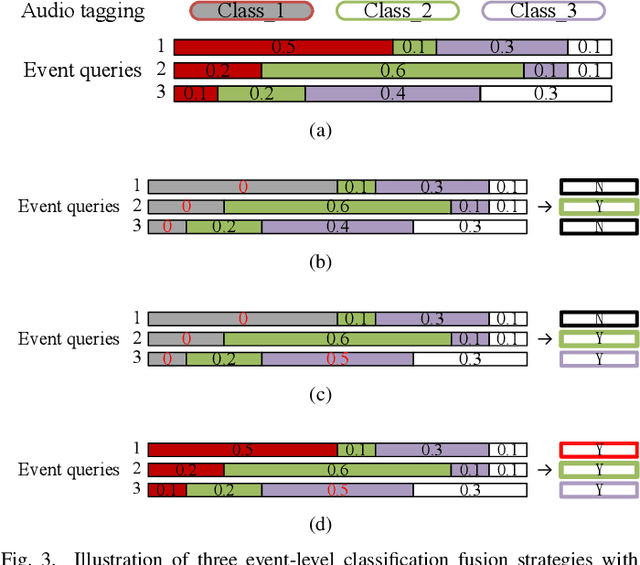

Sound event detection (SED) has gained increasing attention with its wide application in surveillance, video indexing, etc. Existing models in SED mainly generate frame-level predictions, converting it into a sequence multi-label classification problem, which inevitably brings a trade-off between event boundary detection and audio tagging when using weakly labeled data to train the model. Besides, it needs post-processing and cannot be trained in an end-to-end way. This paper firstly presents the 1D Detection Transformer (1D-DETR), inspired by Detection Transformer. Furthermore, given the characteristics of SED, the audio query and a one-to-many matching strategy for fine-tuning the model are added to 1D-DETR to form the model of Sound Event Detection Transformer (SEDT), which generates event-level predictions, end-to-end detection. Experiments are conducted on the URBAN-SED dataset and the DCASE2019 Task4 dataset, and both experiments have achieved competitive results compared with SOTA models. The application of SEDT on SED shows that it can be used as a framework for one-dimensional signal detection and may be extended to other similar tasks.