 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-MIL: Phenotype-Aware Multiple Instance Learning Guided by Language Prompting and Genotype-to-Phenotype Relationships
Jan 30, 2026Deep learning has been extensively researched in the analysis of pathology whole-slide images (WSIs). However, most existing methods are limited to providing prediction interpretability by locating the model's salient areas in a post-hoc manner, failing to offer more reliable and accountable explanations. In this work, we propose Phenotype-Aware Multiple Instance Learning (PA-MIL), a novel ante-hoc interpretable framework that identifies cancer-related phenotypes from WSIs and utilizes them for cancer subtyping. To facilitate PA-MIL in learning phenotype-aware features, we 1) construct a phenotype knowledge base containing cancer-related phenotypes and their associated genotypes. 2) utilize the morphological descriptions of phenotypes as language prompting to aggregate phenotype-related features. 3) devise the Genotype-to-Phenotype Neural Network (GP-NN) grounded in genotype-to-phenotype relationships, which provides multi-level guidance for PA-MIL. Experimental results on multiple datasets demonstrate that PA-MIL achieves competitive performance compared to existing MIL methods while offering improved interpretability. PA-MIL leverages phenotype saliency as evidence and, using a linear classifier, achieves competitive results compared to state-of-the-art methods. Additionally, we thoroughly analyze the genotype-phenotype relationships, as well as cohort-level and case-level interpretability, demonstrating the reliability and accountability of PA-MIL.
Large Language Models as Natural Selector for Embodied Soft Robot Design
Mar 04, 2025



Designing soft robots is a complex and iterative process that demands cross-disciplinary expertise in materials science, mechanics, and control, often relying on intuition and extensive experimentation. While Large Language Models (LLMs) have demonstrated impressive reasoning abilities, their capacity to learn and apply embodied design principles--crucial for creating functional robotic systems--remains largely unexplored. This paper introduces RoboCrafter-QA, a novel benchmark to evaluate whether LLMs can learn representations of soft robot designs that effectively bridge the gap between high-level task descriptions and low-level morphological and material choices. RoboCrafter-QA leverages the EvoGym simulator to generate a diverse set of soft robot design challenges, spanning robotic locomotion, manipulation, and balancing tasks. Our experiments with state-of-the-art multi-modal LLMs reveal that while these models exhibit promising capabilities in learning design representations, they struggle with fine-grained distinctions between designs with subtle performance differences. We further demonstrate the practical utility of LLMs for robot design initialization. Our code and benchmark will be available to encourage the community to foster this exciting research direction.
A Multimodal Object-level Contrast Learning Method for Cancer Survival Risk Prediction
Sep 03, 2024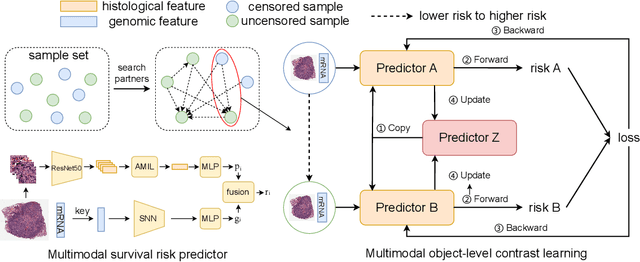
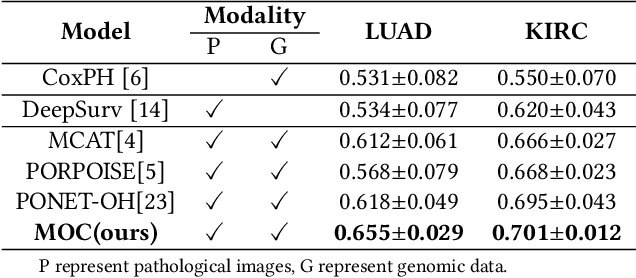
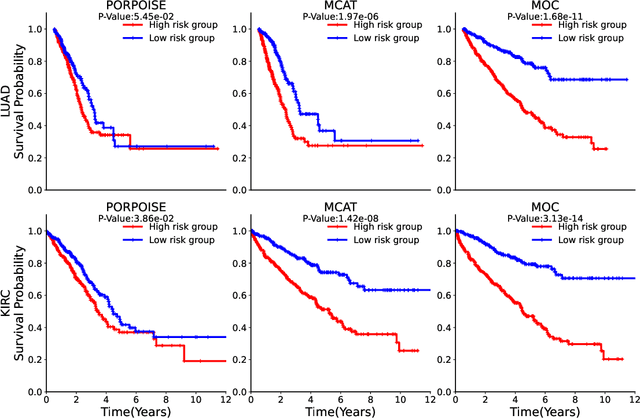

Computer-aided cancer survival risk prediction plays an important role in the timely treatment of patients. This is a challenging weakly supervised ordinal regression task associated with multiple clinical factors involved such as pathological images, genomic data and etc. In this paper, we propose a new training method, multimodal object-level contrast learning, for cancer survival risk prediction. First, we construct contrast learning pairs based on the survival risk relationship among the samples in the training sample set. Then we introduce the object-level contrast learning method to train the survival risk predictor. We further extend it to the multimodal scenario by applying cross-modal constrast. Considering the heterogeneity of pathological images and genomics data, we construct a multimodal survival risk predictor employing attention-based and self-normalizing based nerural network respectively. Finally, the survival risk predictor trained by our proposed method outperforms state-of-the-art methods on two public multimodal cancer datasets for survival risk prediction.
Advancing Multi-grained Alignment for Contrastive Language-Audio Pre-training
Aug 15, 2024



Recent advances have been witnessed in audio-language joint learning, such as CLAP, that shows much success in multi-modal understanding tasks. These models usually aggregate uni-modal local representations, namely frame or word features, into global ones, on which the contrastive loss is employed to reach coarse-grained cross-modal alignment. However, frame-level correspondence with texts may be ignored, making it ill-posed on explainability and fine-grained challenges which may also undermine performances on coarse-grained tasks. In this work, we aim to improve both coarse- and fine-grained audio-language alignment in large-scale contrastive pre-training. To unify the granularity and latent distribution of two modalities, a shared codebook is adopted to represent multi-modal global features with common bases, and each codeword is regularized to encode modality-shared semantics, bridging the gap between frame and word features. Based on it, a locality-aware block is involved to purify local patterns, and a hard-negative guided loss is devised to boost alignment. Experiments on eleven zero-shot coarse- and fine-grained tasks suggest that our model not only surpasses the baseline CLAP significantly but also yields superior or competitive results compared to current SOTA works.
SCMIL: Sparse Context-aware Multiple Instance Learning for Predicting Cancer Survival Probability Distribution in Whole Slide Images
Jun 30, 2024Cancer survival prediction is a challenging task that involves analyzing of the tumor microenvironment within Whole Slide Image (WSI). Previous methods cannot effectively capture the intricate interaction features among instances within the local area of WSI. Moreover, existing methods for cancer survival prediction based on WSI often fail to provide better clinically meaningful predictions. To overcome these challenges, we propose a Sparse Context-aware Multiple Instance Learning (SCMIL) framework for predicting cancer survival probability distributions. SCMIL innovatively segments patches into various clusters based on their morphological features and spatial location information, subsequently leveraging sparse self-attention to discern the relationships between these patches with a context-aware perspective. Considering many patches are irrelevant to the task, we introduce a learnable patch filtering module called SoftFilter, which ensures that only interactions between task-relevant patches are considered. To enhance the clinical relevance of our prediction, we propose a register-based mixture density network to forecast the survival probability distribution for individual patients. We evaluate SCMIL on two public WSI datasets from the The Cancer Genome Atlas (TCGA) specifically focusing on lung adenocarcinom (LUAD) and kidney renal clear cell carcinoma (KIRC). Our experimental results indicate that SCMIL outperforms current state-of-the-art methods for survival prediction, offering more clinically meaningful and interpretable outcomes. Our code is accessible at https://github.com/yang-ze-kang/SCMIL.
Frame Pairwise Distance Loss for Weakly-supervised Sound Event Detection
Sep 21, 2023



Weakly-supervised learning has emerged as a promising approach to leverage limited labeled data in various domains by bridging the gap between fully supervised methods and unsupervised techniques. Acquisition of strong annotations for detecting sound events is prohibitively expensive, making weakly supervised learning a more cost-effective and broadly applicable alternative. In order to enhance the recognition rate of the learning of detection of weakly-supervised sound events, we introduce a Frame Pairwise Distance (FPD) loss branch, complemented with a minimal amount of synthesized data. The corresponding sampling and label processing strategies are also proposed. Two distinct distance metrics are employed to evaluate the proposed approach. Finally, the method is validated on the standard DCASE dataset. The obtained experimental results corroborated the efficacy of this approach.
Audio-free Prompt Tuning for Language-Audio Models
Sep 15, 2023



Contrastive Language-Audio Pretraining (CLAP) is pre-trained to associate audio features with human language, making it a natural zero-shot classifier to recognize unseen sound categories. To adapt CLAP to downstream tasks, prior works inevitably require labeled domain audios, which limits their scalability under data scarcity and deprives them of the capability to detect novel classes as the original CLAP. In this work, by leveraging the modality alignment in CLAP, we propose an efficient audio-free prompt tuning scheme aimed at optimizing a few prompt tokens from texts instead of audios, which regularizes the model space to avoid overfitting the seen classes as well. Based on this, a multi-grained prompt design is further explored to fuse global and local information. Experiments on several tasks demonstrate that our approach can boost the CLAP and outperform other training methods on model performance and training efficiency. While conducting zero-shot inference on unseen categories, it still shows better transferability than the vanilla CLAP. Moreover, our method is flexible enough even if only knowing the downstream class names. The code will be released soon.
Semi-supervised Sound Event Detection with Local and Global Consistency Regularization
Sep 15, 2023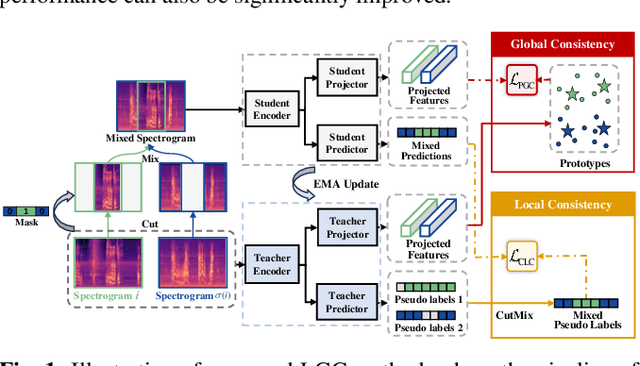
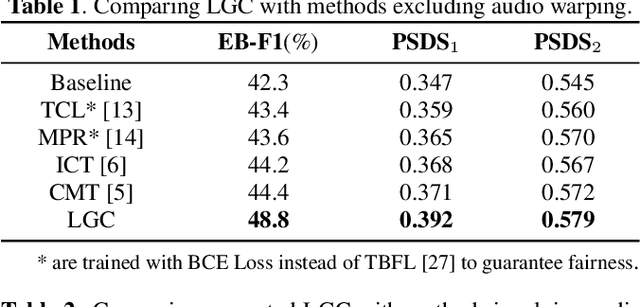
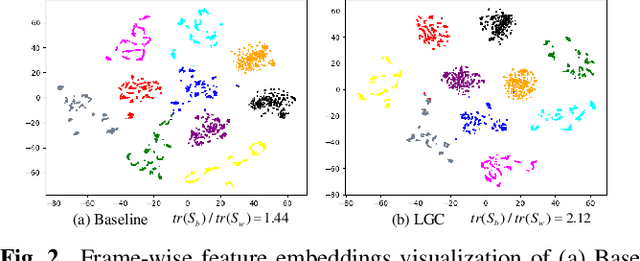
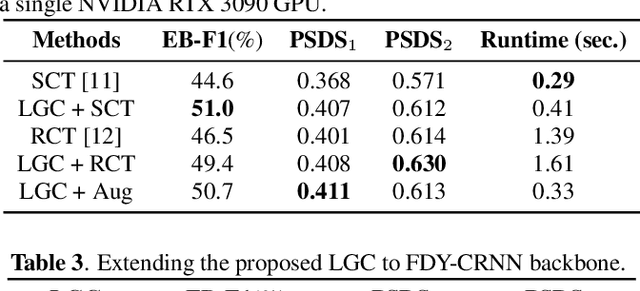
Learning meaningful frame-wise features on a partially labeled dataset is crucial to semi-supervised sound event detection. Prior works either maintain consistency on frame-level predictions or seek feature-level similarity among neighboring frames, which cannot exploit the potential of unlabeled data. In this work, we design a Local and Global Consistency (LGC) regularization scheme to enhance the model on both label- and feature-level. The audio CutMix is introduced to change the contextual information of clips. Then, the local consistency is adopted to encourage the model to leverage local features for frame-level predictions, and the global consistency is applied to force features to align with global prototypes through a specially designed contrastive loss. Experiments on the DESED dataset indicate the superiority of LGC, surpassing its respective competitors largely with the same settings as the baseline system. Besides, combining LGC with existing methods can obtain further improvements. The code will be released soon.
Audio Generation with Multiple Conditional Diffusion Model
Aug 23, 2023Text-based audio generation models have limitations as they cannot encompass all the information in audio, leading to restricted controllability when relying solely on text. To address this issue, we propose a novel model that enhances the controllability of existing pre-trained text-to-audio models by incorporating additional conditions including content (timestamp) and style (pitch contour and energy contour) as supplements to the text. This approach achieves fine-grained control over the temporal order, pitch, and energy of generated audio. To preserve the diversity of generation, we employ a trainable control condition encoder that is enhanced by a large language model and a trainable Fusion-Net to encode and fuse the additional conditions while keeping the weights of the pre-trained text-to-audio model frozen. Due to the lack of suitable datasets and evaluation metrics, we consolidate existing datasets into a new dataset comprising the audio and corresponding conditions and use a series of evaluation metrics to evaluate the controllability performance. Experimental results demonstrate that our model successfully achieves fine-grained control to accomplish controllable audio generation. Audio samples and our dataset are publicly available at https://conditionaudiogen.github.io/conditionaudiogen/
Furnishing Sound Event Detection with Language Model Abilities
Aug 22, 2023Recently, the ability of language models (LMs) has attracted increasing attention in visual cross-modality. In this paper, we further explore the generation capacity of LMs for sound event detection (SED), beyond the visual domain. Specifically, we propose an elegant method that aligns audio features and text features to accomplish sound event classification and temporal location. The framework consists of an acoustic encoder, a contrastive module that align the corresponding representations of the text and audio, and a decoupled language decoder that generates temporal and event sequences from the audio characteristic. Compared with conventional works that require complicated processing and barely utilize limited audio features, our model is more concise and comprehensive since language model directly leverage its semantic capabilities to generate the sequences. We investigate different decoupling modules to demonstrate the effectiveness for timestamps capture and event classification. Evaluation results show that the proposed method achieves accurate sequences of sound event detection.