 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Sound Event Detection with Local and Global Consistency Regularization
Paper and Code
Sep 15, 2023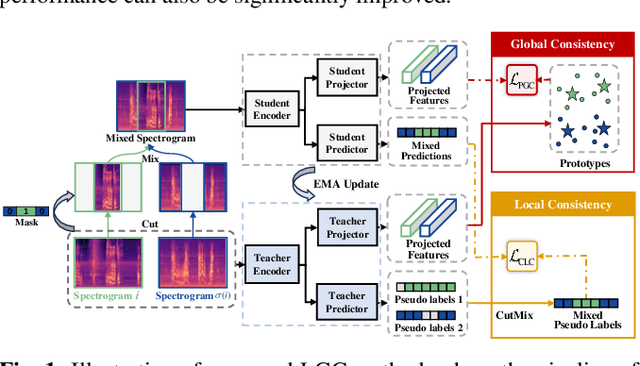
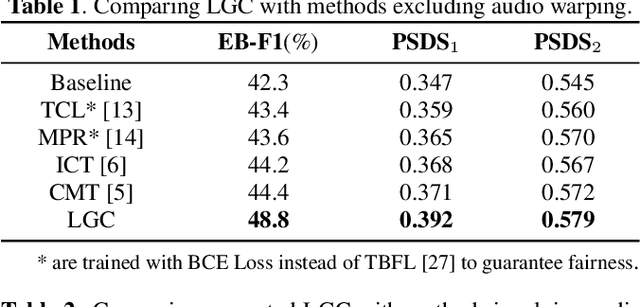
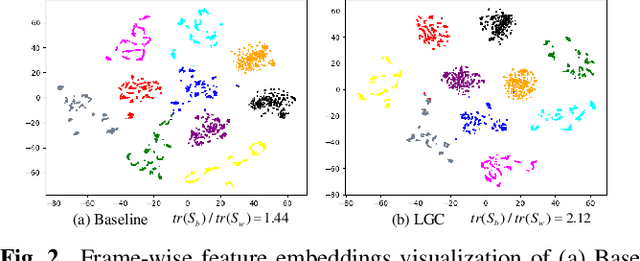
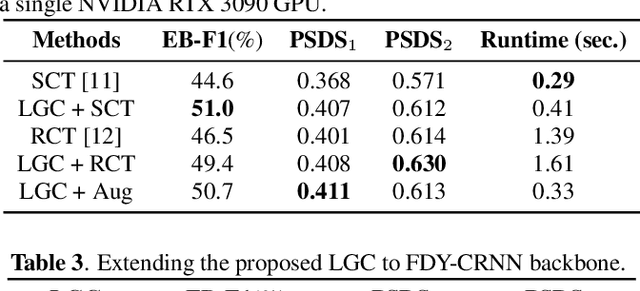
Learning meaningful frame-wise features on a partially labeled dataset is crucial to semi-supervised sound event detection. Prior works either maintain consistency on frame-level predictions or seek feature-level similarity among neighboring frames, which cannot exploit the potential of unlabeled data. In this work, we design a Local and Global Consistency (LGC) regularization scheme to enhance the model on both label- and feature-level. The audio CutMix is introduced to change the contextual information of clips. Then, the local consistency is adopted to encourage the model to leverage local features for frame-level predictions, and the global consistency is applied to force features to align with global prototypes through a specially designed contrastive loss. Experiments on the DESED dataset indicate the superiority of LGC, surpassing its respective competitors largely with the same settings as the baseline system. Besides, combining LGC with existing methods can obtain further improvements. The code will be released soon.