 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Coarse to Nuanced: Cross-Modal Alignment of Fine-Grained Linguistic Cues and Visual Salient Regions for Dynamic Emotion Recognition
Jul 16, 2025Dynamic Facial Expression Recognition (DFER) aims to identify human emotions from temporally evolving facial movements and plays a critical role in affective computing. While recent vision-language approaches have introduced semantic textual descriptions to guide expression recognition, existing methods still face two key limitations: they often underutilize the subtle emotional cues embedded in generated text, and they have yet to incorporate sufficiently effective mechanisms for filtering out facial dynamics that are irrelevant to emotional expression. To address these gaps, We propose GRACE, Granular Representation Alignment for Cross-modal Emotion recognition that integrates dynamic motion modeling, semantic text refinement, and token-level cross-modal alignment to facilitate the precise localization of emotionally salient spatiotemporal features. Our method constructs emotion-aware textual descriptions via a Coarse-to-fine Affective Text Enhancement (CATE) module and highlights expression-relevant facial motion through a motion-difference weighting mechanism. These refined semantic and visual signals are aligned at the token level using entropy-regularized optimal transport. Experiments on three benchmark datasets demonstrate that our method significantly improves recognition performance, particularly in challenging settings with ambiguous or imbalanced emotion classes, establishing new state-of-the-art (SOTA) results in terms of both UAR and WAR.
CORECODE: A Common Sense Annotated Dialogue Dataset with Benchmark Tasks for Chinese Large Language Models
Dec 20, 2023



As an indispensable ingredient of intelligence, commonsense reasoning is crucial for large language models (LLMs) in real-world scenarios. In this paper, we propose CORECODE, a dataset that contains abundant commonsense knowledge manually annotated on dyadic dialogues, to evaluate the commonsense reasoning and commonsense conflict detection capabilities of Chinese LLMs. We categorize commonsense knowledge in everyday conversations into three dimensions: entity, event, and social interaction. For easy and consistent annotation, we standardize the form of commonsense knowledge annotation in open-domain dialogues as "domain: slot = value". A total of 9 domains and 37 slots are defined to capture diverse commonsense knowledge. With these pre-defined domains and slots, we collect 76,787 commonsense knowledge annotations from 19,700 dialogues through crowdsourcing. To evaluate and enhance the commonsense reasoning capability for LLMs on the curated dataset, we establish a series of dialogue-level reasoning and detection tasks, including commonsense knowledge filling, commonsense knowledge generation, commonsense conflict phrase detection, domain identification, slot identification, and event causal inference. A wide variety of existing open-source Chinese LLMs are evaluated with these tasks on our dataset. Experimental results demonstrate that these models are not competent to predict CORECODE's plentiful reasoning content, and even ChatGPT could only achieve 0.275 and 0.084 accuracy on the domain identification and slot identification tasks under the zero-shot setting. We release the data and codes of CORECODE at https://github.com/danshi777/CORECODE to promote commonsense reasoning evaluation and study of LLMs in the context of daily conversations.
RedCore: Relative Advantage Aware Cross-modal Representation Learning for Missing Modalities with Imbalanced Missing Rates
Dec 16, 2023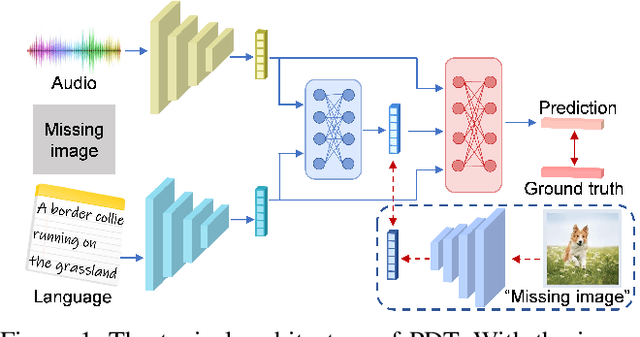
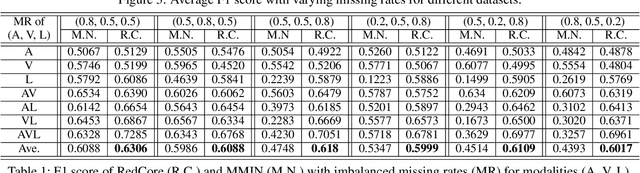
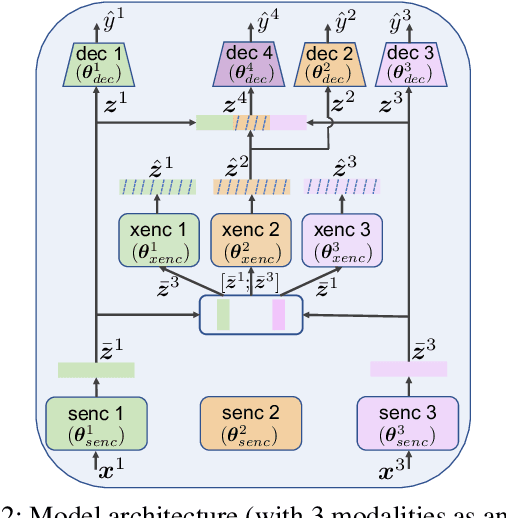
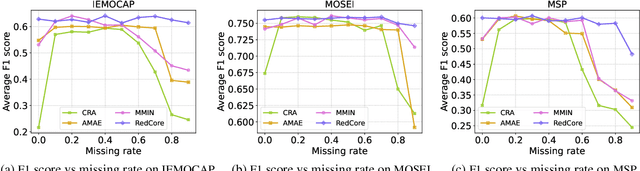
Multimodal learning is susceptible to modality missing, which poses a major obstacle for its practical applications and, thus, invigorates increasing research interest. In this paper, we investigate two challenging problems: 1) when modality missing exists in the training data, how to exploit the incomplete samples while guaranteeing that they are properly supervised? 2) when the missing rates of different modalities vary, causing or exacerbating the imbalance among modalities, how to address the imbalance and ensure all modalities are well-trained? To tackle these two challenges, we first introduce the variational information bottleneck (VIB) method for the cross-modal representation learning of missing modalities, which capitalizes on the available modalities and the labels as supervision. Then, accounting for the imbalanced missing rates, we define relative advantage to quantify the advantage of each modality over others. Accordingly, a bi-level optimization problem is formulated to adaptively regulate the supervision of all modalities during training. As a whole, the proposed approach features \textbf{Re}lative a\textbf{d}vantage aware \textbf{C}ross-m\textbf{o}dal \textbf{r}epresentation l\textbf{e}arning (abbreviated as \textbf{RedCore}) for missing modalities with imbalanced missing rates. Extensive empirical results demonstrate that RedCore outperforms competing models in that it exhibits superior robustness against either large or imbalanced missing rates.
ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
Dec 01, 2023



The advent of large language models, enabling flexibility through instruction-driven approaches, has revolutionized many traditional generative tasks, but large models for 3D data, particularly in comprehensively handling 3D shapes with other modalities, are still under-explored. By achieving instruction-based shape generations, versatile multimodal generative shape models can significantly benefit various fields like 3D virtual construction and network-aided design. In this work, we present ShapeGPT, a shape-included multi-modal framework to leverage strong pre-trained language models to address multiple shape-relevant tasks. Specifically, ShapeGPT employs a word-sentence-paragraph framework to discretize continuous shapes into shape words, further assembles these words for shape sentences, as well as integrates shape with instructional text for multi-modal paragraphs. To learn this shape-language model, we use a three-stage training scheme, including shape representation, multimodal alignment, and instruction-based generation, to align shape-language codebooks and learn the intricate correlations among these modalities. Extensive experiments demonstrate that ShapeGPT achieves comparable performance across shape-relevant tasks, including text-to-shape, shape-to-text, shape completion, and shape editing.
Frame Pairwise Distance Loss for Weakly-supervised Sound Event Detection
Sep 21, 2023



Weakly-supervised learning has emerged as a promising approach to leverage limited labeled data in various domains by bridging the gap between fully supervised methods and unsupervised techniques. Acquisition of strong annotations for detecting sound events is prohibitively expensive, making weakly supervised learning a more cost-effective and broadly applicable alternative. In order to enhance the recognition rate of the learning of detection of weakly-supervised sound events, we introduce a Frame Pairwise Distance (FPD) loss branch, complemented with a minimal amount of synthesized data. The corresponding sampling and label processing strategies are also proposed. Two distinct distance metrics are employed to evaluate the proposed approach. Finally, the method is validated on the standard DCASE dataset. The obtained experimental results corroborated the efficacy of this approach.
Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
Sep 06, 2023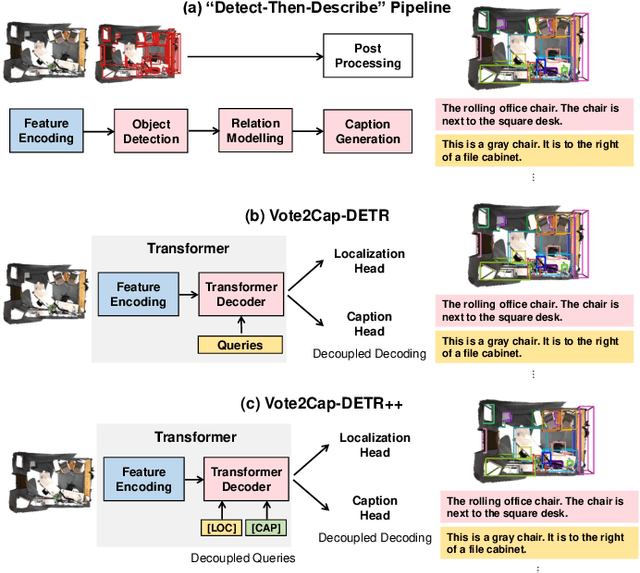
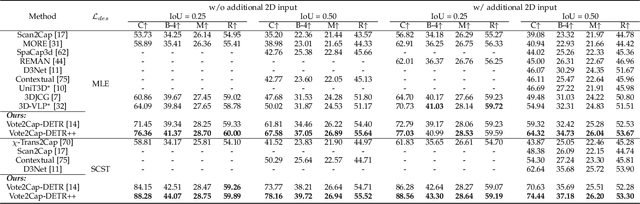
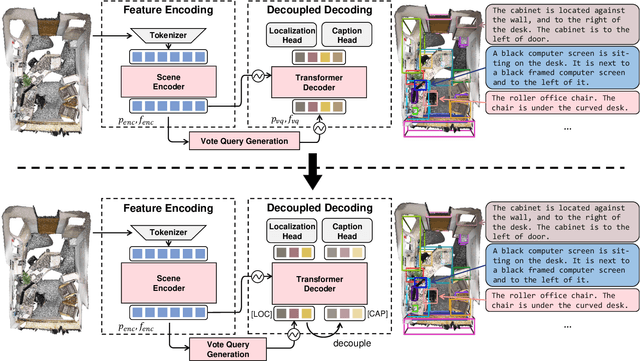
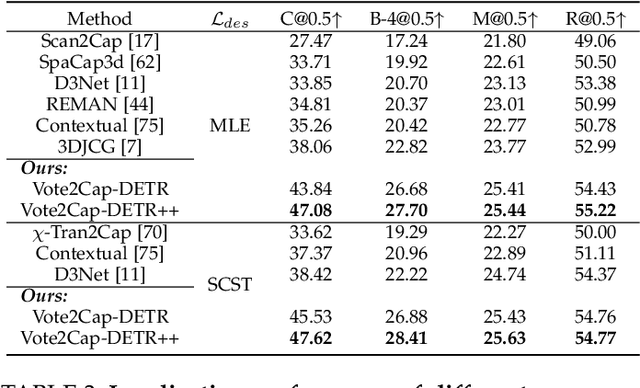
3D dense captioning requires a model to translate its understanding of an input 3D scene into several captions associated with different object regions. Existing methods adopt a sophisticated "detect-then-describe" pipeline, which builds explicit relation modules upon a 3D detector with numerous hand-crafted components. While these methods have achieved initial success, the cascade pipeline tends to accumulate errors because of duplicated and inaccurate box estimations and messy 3D scenes. In this paper, we first propose Vote2Cap-DETR, a simple-yet-effective transformer framework that decouples the decoding process of caption generation and object localization through parallel decoding. Moreover, we argue that object localization and description generation require different levels of scene understanding, which could be challenging for a shared set of queries to capture. To this end, we propose an advanced version, Vote2Cap-DETR++, which decouples the queries into localization and caption queries to capture task-specific features. Additionally, we introduce the iterative spatial refinement strategy to vote queries for faster convergence and better localization performance. We also insert additional spatial information to the caption head for more accurate descriptions. Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate Vote2Cap-DETR and Vote2Cap-DETR++ surpass conventional "detect-then-describe" methods by a large margin. Codes will be made available at https://github.com/ch3cook-fdu/Vote2Cap-DETR.
Disentangling Prosody Representations with Unsupervised Speech Reconstruction
Dec 14, 2022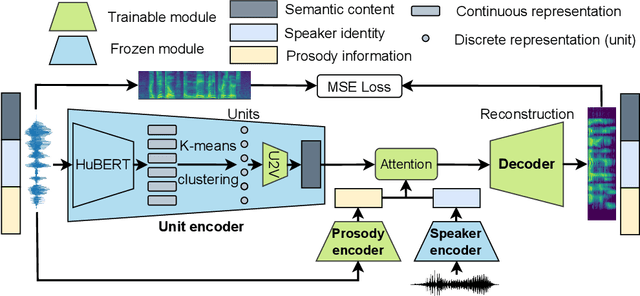

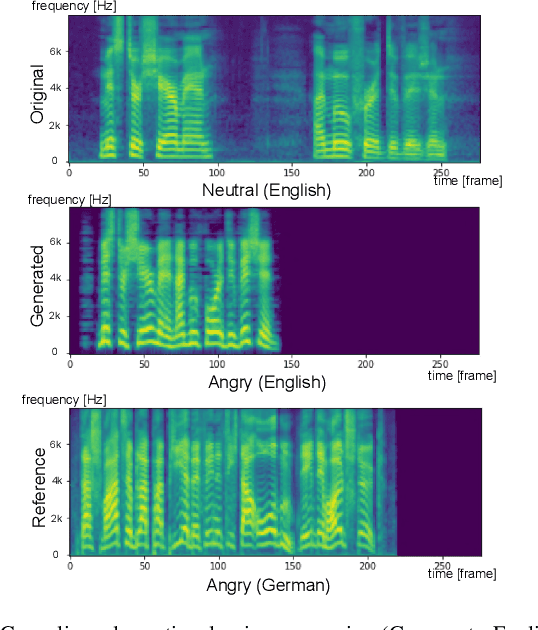
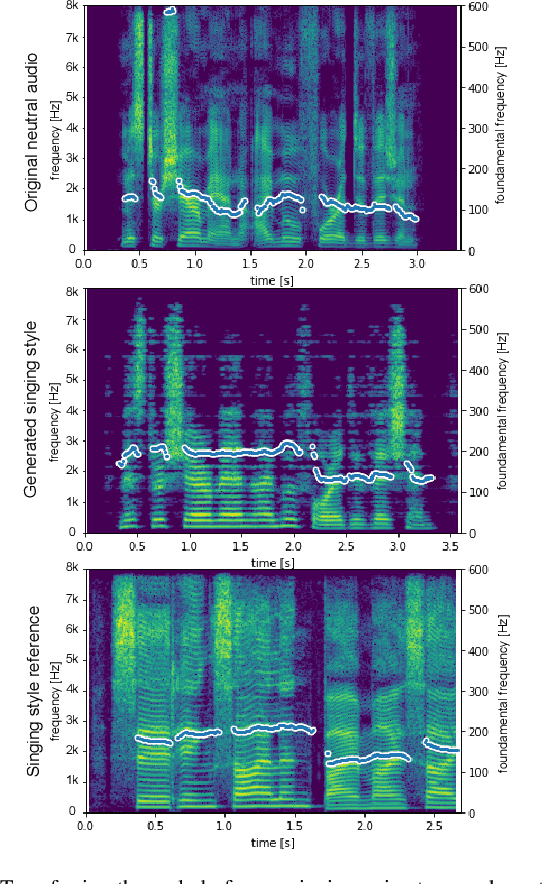
Human speech can be characterized by different components, including semantic content, speaker identity and prosodic information. Significant progress has been made in disentangling representations for semantic content and speaker identity in Automatic Speech Recognition (ASR) and speaker verification tasks respectively. However, it is still an open challenging research question to extract prosodic information because of the intrinsic association of different attributes, such as timbre and rhythm, and because of the need for unsupervised training schemes to achieve robust large-scale and speaker-independent ASR. The aim of this paper is to address the disentanglement of emotional prosody from speech based on unsupervised reconstruction. Specifically, we identify, design, implement and integrate three crucial components in our proposed speech reconstruction model Prosody2Vec: (1) a unit encoder that transforms speech signals into discrete units for semantic content, (2) a pretrained speaker verification model to generate speaker identity embeddings, and (3) a trainable prosody encoder to learn prosody representations. We first pretrain the Prosody2Vec representations on unlabelled emotional speech corpora, then fine-tune the model on specific datasets to perform Speech Emotion Recognition (SER) and Emotional Voice Conversion (EVC) tasks. Both objective and subjective evaluations on the EVC task suggest that Prosody2Vec effectively captures general prosodic features that can be smoothly transferred to other emotional speech. In addition, our SER experiments on the IEMOCAP dataset reveal that the prosody features learned by Prosody2Vec are complementary and beneficial for the performance of widely used speech pretraining models and surpass the state-of-the-art methods when combining Prosody2Vec with HuBERT representations. Some audio samples can be found on our demo website.
Parameter-Efficient Tuning on Layer Normalization for Pre-trained Language Models
Dec 09, 2022



Conventional fine-tuning encounters increasing difficulties given the size of current Pre-trained Language Models, which makes parameter-efficient tuning become the focal point of frontier research. Previous methods in this field add tunable adapters into MHA or/and FFN of Transformer blocks to enable PLMs achieve transferability. However, as an important part of Transformer architecture, the power of layer normalization for parameter-efficent tuning is ignored. In this paper, we first propose LN-tuning, by tuning the gain and bias term of Layer Normalization module with only 0.03\% parameters, which is of high time-efficency and significantly superior to baselines which are less than 0.1\% tunable parameters. Further, we study the unified framework of combining LN-tuning with previous ones and we find that: (1) the unified framework of combining prefix-tuning, the adapter-based method working on MHA, and LN-tuning achieves SOTA performance. (2) unified framework which tunes MHA and LayerNorm simultaneously can get performance improvement but those which tune FFN and LayerNorm simultaneous will cause performance decrease. Ablation study validates LN-tuning is of no abundant parameters and gives a further understanding of it.
Data Augmentation with Unsupervised Speaking Style Transfer for Speech Emotion Recognition
Nov 16, 2022



Currently, the performance of Speech Emotion Recognition (SER) systems is mainly constrained by the absence of large-scale labelled corpora. Data augmentation is regarded as a promising approach, which borrows methods from Automatic Speech Recognition (ASR), for instance, perturbation on speed and pitch, or generating emotional speech utilizing generative adversarial networks. In this paper, we propose EmoAug, a novel style transfer model to augment emotion expressions, in which a semantic encoder and a paralinguistic encoder represent verbal and non-verbal information respectively. Additionally, a decoder reconstructs speech signals by conditioning on the aforementioned two information flows in an unsupervised fashion. Once training is completed, EmoAug enriches expressions of emotional speech in different prosodic attributes, such as stress, rhythm and intensity, by feeding different styles into the paralinguistic encoder. In addition, we can also generate similar numbers of samples for each class to tackle the data imbalance issue. Experimental results on the IEMOCAP dataset demonstrate that EmoAug can successfully transfer different speaking styles while retaining the speaker identity and semantic content. Furthermore, we train a SER model with data augmented by EmoAug and show that it not only surpasses the state-of-the-art supervised and self-supervised methods but also overcomes overfitting problems caused by data imbalance. Some audio samples can be found on our demo website.
Fast sensor placement by enlarging principle submatrix for large-scale linear inverse problems
Oct 07, 2021
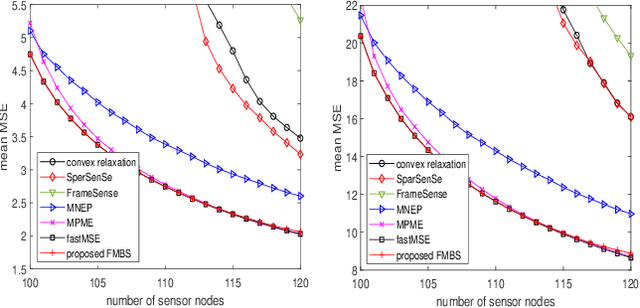
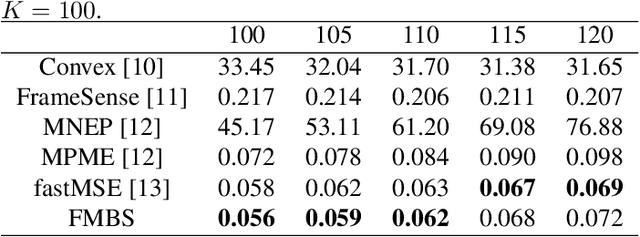
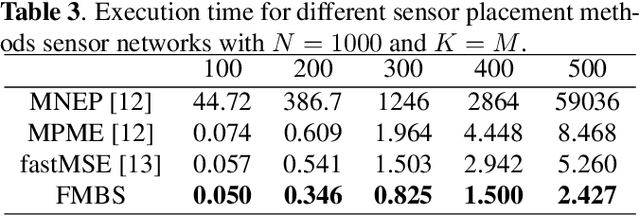
Sensor placement for linear inverse problems is the selection of locations to assign sensors so that the entire physical signal can be well recovered from partial observations. In this paper, we propose a fast sampling algorithm to place sensors. Specifically, assuming that the field signal $\mathbf{f}$ is represented by a linear model $\mathbf{f}=\pmb{\phi}\mathbf{g}$, it can be estimated from partial noisy samples via an unbiased least-squares (LS) method, whose expected mean square error (MSE) depends on chosen samples. First, we formulate an approximate MSE problem, and then prove it is equivalent to a problem related to a principle submatrix of $\pmb{\phi}\pmb{\phi}^\top$ indexed by sample set. To solve the formulated problem, we devise a fast greedy algorithm with simple matrix-vector multiplications, leveraging a matrix inverse formula. To further reduce complexity, we reuse results in the previous greedy step for warm start, so that candidates can be evaluated via lightweight vector-vector multiplications. Extensive experiments show that our proposed sensor placement method achieved the lowest sensor sampling time and the best performance compared to state-of-the-art schemes.