 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZebra-CoT: A Dataset for Interleaved Vision Language Reasoning
Jul 22, 2025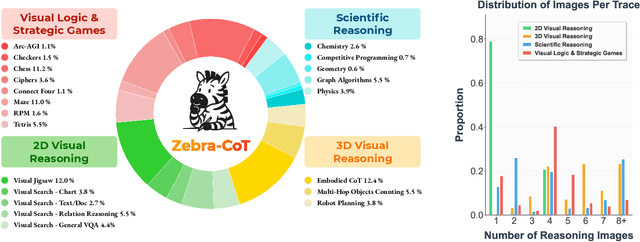

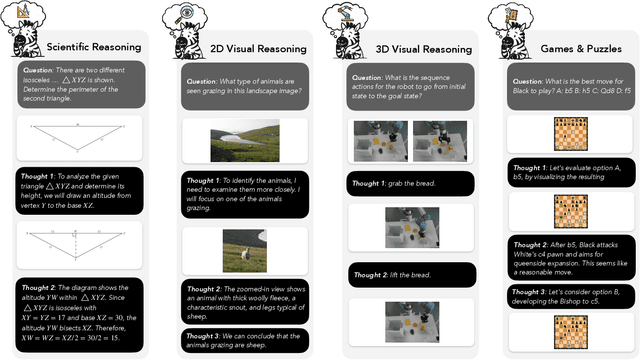

Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $\textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT's effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
LPVIMO-SAM: Tightly-coupled LiDAR/Polarization Vision/Inertial/Magnetometer/Optical Flow Odometry via Smoothing and Mapping
Apr 29, 2025We propose a tightly-coupled LiDAR/Polarization Vision/Inertial/Magnetometer/Optical Flow Odometry via Smoothing and Mapping (LPVIMO-SAM) framework, which integrates LiDAR, polarization vision, inertial measurement unit, magnetometer, and optical flow in a tightly-coupled fusion. This framework enables high-precision and highly robust real-time state estimation and map construction in challenging environments, such as LiDAR-degraded, low-texture regions, and feature-scarce areas. The LPVIMO-SAM comprises two subsystems: a Polarized Vision-Inertial System and a LiDAR/Inertial/Magnetometer/Optical Flow System. The polarized vision enhances the robustness of the Visual/Inertial odometry in low-feature and low-texture scenarios by extracting the polarization information of the scene. The magnetometer acquires the heading angle, and the optical flow obtains the speed and height to reduce the accumulated error. A magnetometer heading prior factor, an optical flow speed observation factor, and a height observation factor are designed to eliminate the cumulative errors of the LiDAR/Inertial odometry through factor graph optimization. Meanwhile, the LPVIMO-SAM can maintain stable positioning even when one of the two subsystems fails, further expanding its applicability in LiDAR-degraded, low-texture, and low-feature environments. Code is available on https://github.com/junxiaofanchen/LPVIMO-SAM.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Simultaneous Pre-compensation for Bandwidth Limitation and Fiber Dispersion in Cost-Sensitive IM/DD Transmission Systems
Apr 02, 2025


We propose a pre-compensation scheme for bandwidth limitation and fiber dispersion (pre-BL-EDC) based on the modified Gerchberg-Saxton (GS) algorithm. Experimental results demonstrate 1.0/1.0/2.0 dB gains compared to modified GS pre-EDC for 20/28/32 Gbit/s bandwidth-limited systems.
Fuzzy Clustering for Low-Complexity Time Domain Chromatic Dispersion Compensation Scheme in Coherent Optical Fiber Communication Systems
Mar 16, 2025Chromatic dispersion compensation (CDC), implemented in either the time-domain or frequency-domain, is crucial for enhancing power efficiency in the digital signal processing of modern optical fiber communication systems. Developing low-complexity CDC schemes is essential for hardware implemention, particularly for high-speed and long-haul optical fiber communication systems. In this work, we propose a novel two-stage fuzzy clustered time-domain chromatic dispersion compensation scheme. Unlike hard decisions of CDC filter coefficients after determining the cluster centroids, our approach applies a soft fuzzy decision, allowing the coefficients to belong to multiple clusters. Experiments on a single-channel, single-polarization 20Gbaud 16-QAM 1800 km standard single-mode fiber communication system demonstrate that our approach has a complexity reduction of 53.8% and 40% compared with clustered TD-CDC and FD-CDC at a target Q-factor of 20% HD-FEC, respectively. Furthermore, the proposed method achieves the same optimal Q-factor as FD-CDC with a 27% complexity reduction.
Prompt-driven Universal Model for View-Agnostic Echocardiography Analysis
Apr 09, 2024Echocardiography segmentation for cardiac analysis is time-consuming and resource-intensive due to the variability in image quality and the necessity to process scans from various standard views. While current automated segmentation methods in echocardiography show promising performance, they are trained on specific scan views to analyze corresponding data. However, this solution has a limitation as the number of required models increases with the number of standard views. To address this, in this paper, we present a prompt-driven universal method for view-agnostic echocardiography analysis. Considering the domain shift between standard views, we first introduce a method called prompt matching, aimed at learning prompts specific to different views by matching prompts and querying input embeddings using a pre-trained vision model. Then, we utilized a pre-trained medical language model to align textual information with pixel data for accurate segmentation. Extensive experiments on three standard views showed that our approach significantly outperforms the state-of-the-art universal methods and achieves comparable or even better performances over the segmentation model trained and tested on same views.
Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
Sep 06, 2023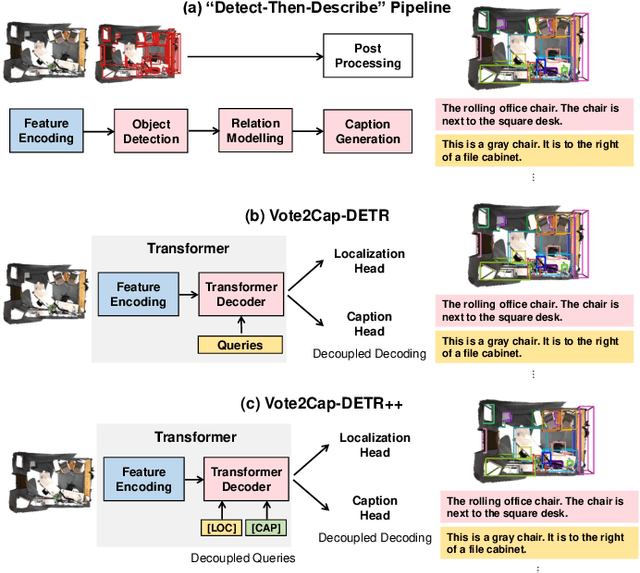
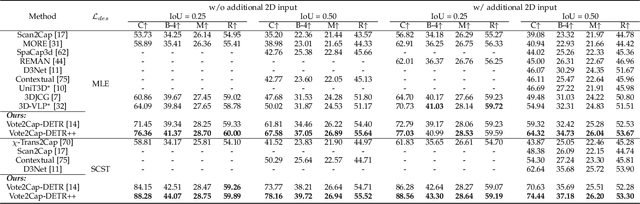
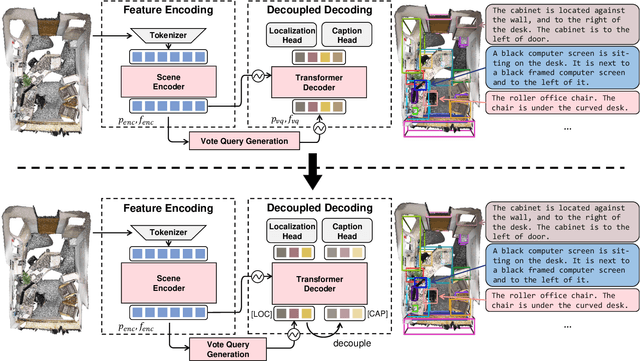
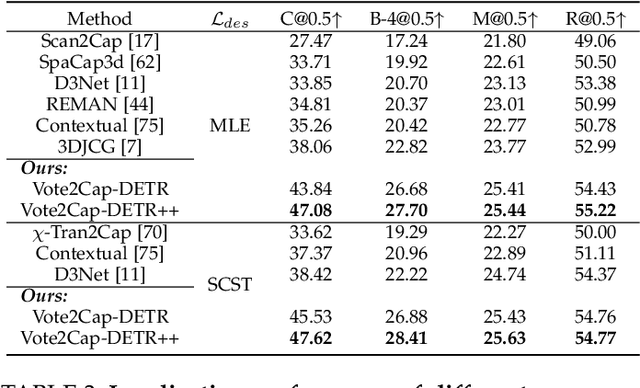
3D dense captioning requires a model to translate its understanding of an input 3D scene into several captions associated with different object regions. Existing methods adopt a sophisticated "detect-then-describe" pipeline, which builds explicit relation modules upon a 3D detector with numerous hand-crafted components. While these methods have achieved initial success, the cascade pipeline tends to accumulate errors because of duplicated and inaccurate box estimations and messy 3D scenes. In this paper, we first propose Vote2Cap-DETR, a simple-yet-effective transformer framework that decouples the decoding process of caption generation and object localization through parallel decoding. Moreover, we argue that object localization and description generation require different levels of scene understanding, which could be challenging for a shared set of queries to capture. To this end, we propose an advanced version, Vote2Cap-DETR++, which decouples the queries into localization and caption queries to capture task-specific features. Additionally, we introduce the iterative spatial refinement strategy to vote queries for faster convergence and better localization performance. We also insert additional spatial information to the caption head for more accurate descriptions. Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate Vote2Cap-DETR and Vote2Cap-DETR++ surpass conventional "detect-then-describe" methods by a large margin. Codes will be made available at https://github.com/ch3cook-fdu/Vote2Cap-DETR.
OpenInst: A Simple Query-Based Method for Open-World Instance Segmentation
Mar 28, 2023



Open-world instance segmentation has recently gained significant popularitydue to its importance in many real-world applications, such as autonomous driving, robot perception, and remote sensing. However, previous methods have either produced unsatisfactory results or relied on complex systems and paradigms. We wonder if there is a simple way to obtain state-of-the-art results. Fortunately, we have identified two observations that help us achieve the best of both worlds: 1) query-based methods demonstrate superiority over dense proposal-based methods in open-world instance segmentation, and 2) learning localization cues is sufficient for open world instance segmentation. Based on these observations, we propose a simple query-based method named OpenInst for open world instance segmentation. OpenInst leverages advanced query-based methods like QueryInst and focuses on learning localization cues. Notably, OpenInst is an extremely simple and straightforward framework without any auxiliary modules or post-processing, yet achieves state-of-the-art results on multiple benchmarks. Specifically, in the COCO$\to$UVO scenario, OpenInst achieves a mask AR of 53.3, outperforming the previous best methods by 2.0 AR with a simpler structure. We hope that OpenInst can serve as a solid baselines for future research in this area.