 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Layer Attentive Feature Upsampling for Low-latency Semantic Segmentation
Jan 03, 2026Semantic segmentation is a fundamental problem in computer vision and it requires high-resolution feature maps for dense prediction. Current coordinate-guided low-resolution feature interpolation methods, e.g., bilinear interpolation, produce coarse high-resolution features which suffer from feature misalignment and insufficient context information. Moreover, enriching semantics to high-resolution features requires a high computation burden, so that it is challenging to meet the requirement of lowlatency inference. We propose a novel Guided Attentive Interpolation (GAI) method to adaptively interpolate fine-grained high-resolution features with semantic features to tackle these issues. Guided Attentive Interpolation determines both spatial and semantic relations of pixels from features of different resolutions and then leverages these relations to interpolate high-resolution features with rich semantics. GAI can be integrated with any deep convolutional network for efficient semantic segmentation. In experiments, the GAI-based semantic segmentation networks, i.e., GAIN, can achieve78.8 mIoU with 22.3 FPS on Cityscapes and 80.6 mIoU with 64.5 on CamVid using an NVIDIA 1080Ti GPU, which are the new state-of-the-art results of low-latency semantic segmentation. Code and models are available at: https://github.com/hustvl/simpleseg.
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Dec 31, 2025World models have become crucial for autonomous driving, as they learn how scenarios evolve over time to address the long-tail challenges of the real world. However, current approaches relegate world models to limited roles: they operate within ostensibly unified architectures that still keep world prediction and motion planning as decoupled processes. To bridge this gap, we propose DriveLaW, a novel paradigm that unifies video generation and motion planning. By directly injecting the latent representation from its video generator into the planner, DriveLaW ensures inherent consistency between high-fidelity future generation and reliable trajectory planning. Specifically, DriveLaW consists of two core components: DriveLaW-Video, our powerful world model that generates high-fidelity forecasting with expressive latent representations, and DriveLaW-Act, a diffusion planner that generates consistent and reliable trajectories from the latent of DriveLaW-Video, with both components optimized by a three-stage progressive training strategy. The power of our unified paradigm is demonstrated by new state-of-the-art results across both tasks. DriveLaW not only advances video prediction significantly, surpassing best-performing work by 33.3% in FID and 1.8% in FVD, but also achieves a new record on the NAVSIM planning benchmark.
DiffusionVL: Translating Any Autoregressive Models into Diffusion Vision Language Models
Dec 24, 2025In recent multimodal research, the diffusion paradigm has emerged as a promising alternative to the autoregressive paradigm (AR), owing to its unique decoding advantages. However, due to the capability limitations of the base diffusion language model, the performance of the diffusion vision language model (dVLM) still lags significantly behind that of mainstream models. This leads to a simple yet fundamental question: Is it possible to construct dVLMs based on existing powerful AR models? In response, we propose DiffusionVL, a dVLM family that could be translated from any powerful AR models. Through simple fine-tuning, we successfully adapt AR pre-trained models into the diffusion paradigm. This approach yields two key observations: (1) The paradigm shift from AR-based multimodal models to diffusion is remarkably effective. (2) Direct conversion of an AR language model to a dVLM is also feasible, achieving performance competitive with LLaVA-style visual-instruction-tuning. Further, we introduce a block-decoding design into dVLMs that supports arbitrary-length generation and KV cache reuse, achieving a significant inference speedup. We conduct a large number of experiments. Despite training with less than 5% of the data required by prior methods, DiffusionVL achieves a comprehensive performance improvement-a 34.4% gain on the MMMU-Pro (vision) bench and 37.5% gain on the MME (Cog.) bench-alongside a 2x inference speedup. The model and code are released at https://github.com/hustvl/DiffusionVL.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025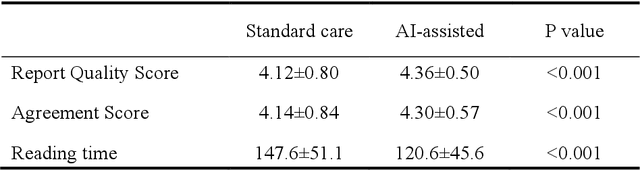
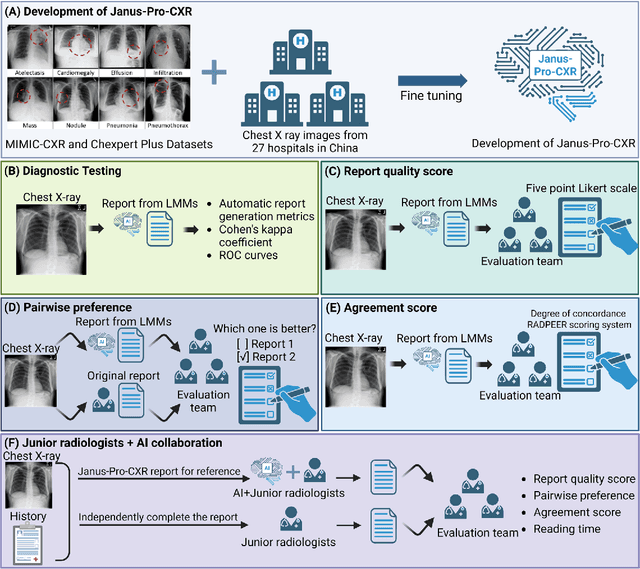
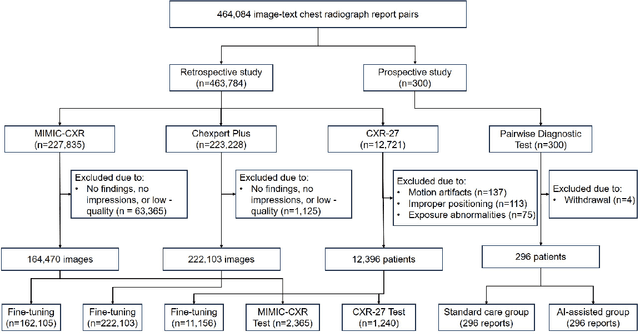
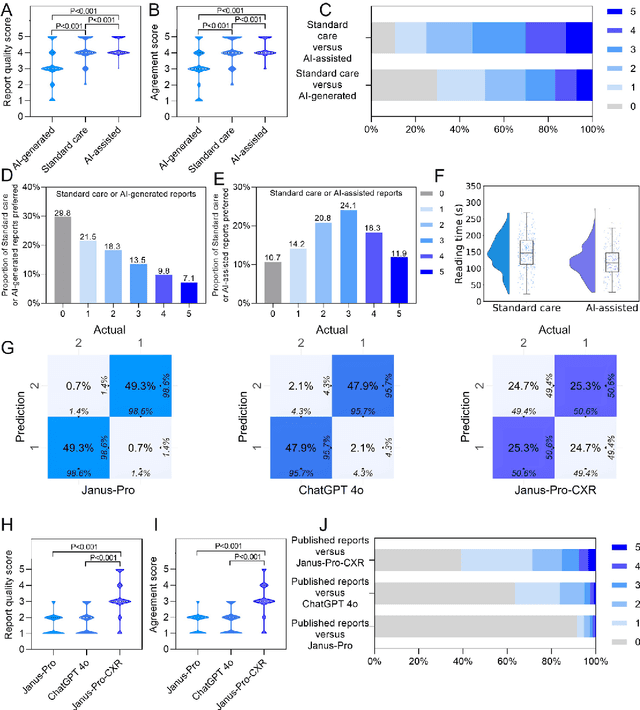
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
DeltaMIL: Gated Memory Integration for Efficient and Discriminative Whole Slide Image Analysis
Dec 22, 2025



Whole Slide Images (WSIs) are typically analyzed using multiple instance learning (MIL) methods. However, the scale and heterogeneity of WSIs generate highly redundant and dispersed information, making it difficult to identify and integrate discriminative signals. Existing MIL methods either fail to discard uninformative cues effectively or have limited ability to consolidate relevant features from multiple patches, which restricts their performance on large and heterogeneous WSIs. To address this issue, we propose DeltaMIL, a novel MIL framework that explicitly selects semantically relevant regions and integrates the discriminative information from WSIs. Our method leverages the gated delta rule to efficiently filter and integrate information through a block combining forgetting and memory mechanisms. The delta mechanism dynamically updates the memory by removing old values and inserting new ones according to their correlation with the current patch. The gating mechanism further enables rapid forgetting of irrelevant signals. Additionally, DeltaMIL integrates a complementary local pattern mixing mechanism to retain fine-grained pathological locality. Our design enhances the extraction of meaningful cues and suppresses redundant or noisy information, which improves the model's robustness and discriminative power. Experiments demonstrate that DeltaMIL achieves state-of-the-art performance. Specifically, for survival prediction, DeltaMIL improves performance by 3.69\% using ResNet-50 features and 2.36\% using UNI features. For slide-level classification, it increases accuracy by 3.09\% with ResNet-50 features and 3.75\% with UNI features. These results demonstrate the strong and consistent performance of DeltaMIL across diverse WSI tasks.
SuperCLIP: CLIP with Simple Classification Supervision
Dec 16, 2025

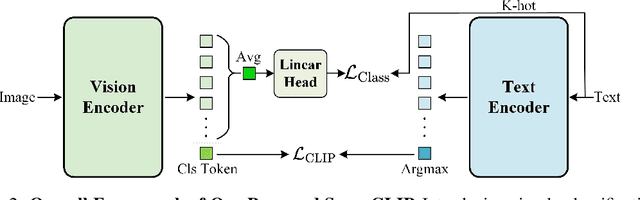
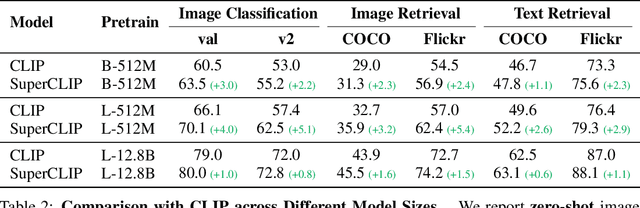
Contrastive Language-Image Pretraining (CLIP) achieves strong generalization in vision-language tasks by aligning images and texts in a shared embedding space. However, recent findings show that CLIP-like models still underutilize fine-grained semantic signals in text, and this issue becomes even more pronounced when dealing with long and detailed captions. This stems from CLIP's training objective, which optimizes only global image-text similarity and overlooks token-level supervision - limiting its ability to achieve fine-grained visual-text alignment. To address this, we propose SuperCLIP, a simple yet effective framework that augments contrastive learning with classification-based supervision. By adding only a lightweight linear layer to the vision encoder, SuperCLIP leverages token-level cues to enhance visual-textual alignment - with just a 0.077% increase in total FLOPs, and no need for additional annotated data. Experiments show that SuperCLIP consistently improves zero-shot classification, image-text retrieval, and purely visual tasks. These gains hold regardless of whether the model is trained on original web data or rich re-captioned data, demonstrating SuperCLIP's ability to recover textual supervision in both cases. Furthermore, SuperCLIP alleviates CLIP's small-batch performance drop through classification-based supervision that avoids reliance on large batch sizes. Code and models will be made open source.
Towards Scalable Pre-training of Visual Tokenizers for Generation
Dec 15, 2025The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation. We identify this as the ``pre-training scaling problem`` and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy and 0.36 rFID on ImageNet) and 4.1 times faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8\% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS. Our pre-trained models are available at https://github.com/MiniMax-AI/VTP.
InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
Dec 09, 2025Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at https://github.com/hustvl/InfiniteVL.
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025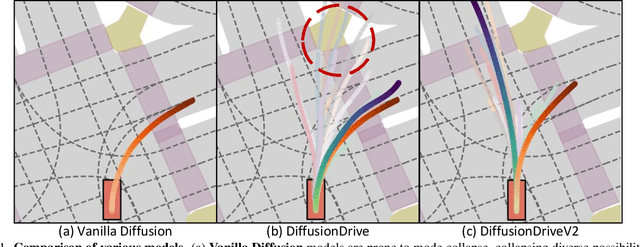
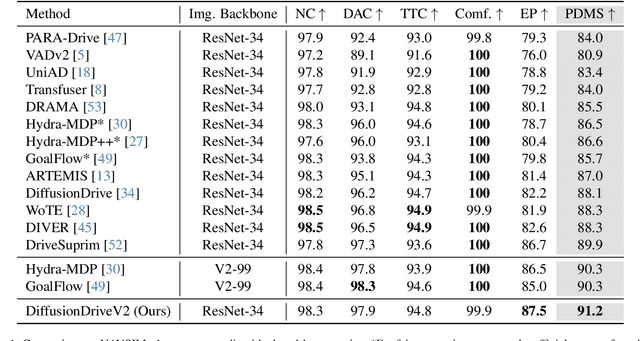
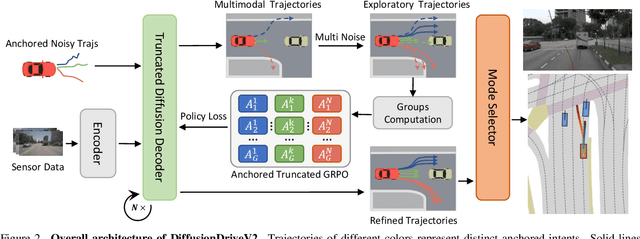
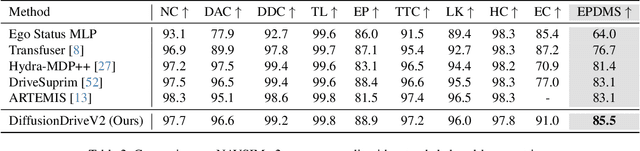
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
Phys-Liquid: A Physics-Informed Dataset for Estimating 3D Geometry and Volume of Transparent Deformable Liquids
Nov 14, 2025
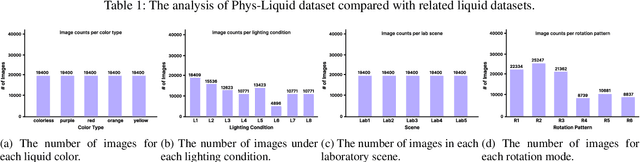

Estimating the geometric and volumetric properties of transparent deformable liquids is challenging due to optical complexities and dynamic surface deformations induced by container movements. Autonomous robots performing precise liquid manipulation tasks, such as dispensing, aspiration, and mixing, must handle containers in ways that inevitably induce these deformations, complicating accurate liquid state assessment. Current datasets lack comprehensive physics-informed simulation data representing realistic liquid behaviors under diverse dynamic scenarios. To bridge this gap, we introduce Phys-Liquid, a physics-informed dataset comprising 97,200 simulation images and corresponding 3D meshes, capturing liquid dynamics across multiple laboratory scenes, lighting conditions, liquid colors, and container rotations. To validate the realism and effectiveness of Phys-Liquid, we propose a four-stage reconstruction and estimation pipeline involving liquid segmentation, multi-view mask generation, 3D mesh reconstruction, and real-world scaling. Experimental results demonstrate improved accuracy and consistency in reconstructing liquid geometry and volume, outperforming existing benchmarks. The dataset and associated validation methods facilitate future advancements in transparent liquid perception tasks. The dataset and code are available at https://dualtransparency.github.io/Phys-Liquid/.