 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
May 07, 2026Reinforcement learning with verifiable rewards (RLVR) has become a standard approach for large language models (LLMs) post-training to incentivize reasoning capacity. Among existing recipes, group-based policy gradient is prevalent, which samples a group of responses per prompt and updates the policy via group-relative advantage signals. This work reveals that these optimization strategies share a common geometric structure: each implicitly defines a target distribution on the response simplex and projects toward it via first-order approximation. Building on this insight, we propose Listwise Policy Optimization (LPO) to explicitly conduct the target-projection, which demystifies the implicit target by restricting the proximal RL objective to the response simplex, and then projects the policy via exact divergence minimization. This framework provides (i) monotonic improvement on the listwise objective with bounded, zero-sum, and self-correcting projection gradients, and (ii) flexibility in divergence selection with distinct structural properties through the decoupled projection step. On diverse reasoning tasks and LLM backbones, LPO consistently improves training performance over typical policy gradient baselines under matched targets, while intrinsically preserving optimization stability and response diversity.
MaTVLM: Hybrid Mamba-Transformer for Efficient Vision-Language Modeling
Mar 17, 2025With the advancement of RNN models with linear complexity, the quadratic complexity challenge of transformers has the potential to be overcome. Notably, the emerging Mamba-2 has demonstrated competitive performance, bridging the gap between RNN models and transformers. However, due to sequential processing and vanishing gradients, RNN models struggle to capture long-range dependencies, limiting contextual understanding. This results in slow convergence, high resource demands, and poor performance on downstream understanding and complex reasoning tasks. In this work, we present a hybrid model MaTVLM by substituting a portion of the transformer decoder layers in a pre-trained VLM with Mamba-2 layers. Leveraging the inherent relationship between attention and Mamba-2, we initialize Mamba-2 with corresponding attention weights to accelerate convergence. Subsequently, we employ a single-stage distillation process, using the pre-trained VLM as the teacher model to transfer knowledge to the MaTVLM, further enhancing convergence speed and performance. Furthermore, we investigate the impact of differential distillation loss within our training framework. We evaluate the MaTVLM on multiple benchmarks, demonstrating competitive performance against the teacher model and existing VLMs while surpassing both Mamba-based VLMs and models of comparable parameter scales. Remarkably, the MaTVLM achieves up to 3.6x faster inference than the teacher model while reducing GPU memory consumption by 27.5%, all without compromising performance. Code and models are released at http://github.com/hustvl/MaTVLM.
Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
Feb 18, 2025Recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance but face deployment challenges due to their quadratic computational complexity, growing Key-Value cache requirements, and reliance on separate vision encoders. We propose mmMamba, a framework for developing linear-complexity native multimodal state space models through progressive distillation from existing MLLMs using moderate academic computational resources. Our approach enables the direct conversion of trained decoder-only MLLMs to linear-complexity architectures without requiring pre-trained RNN-based LLM or vision encoders. We propose an seeding strategy to carve Mamba from trained Transformer and a three-stage distillation recipe, which can effectively transfer the knowledge from Transformer to Mamba while preserving multimodal capabilities. Our method also supports flexible hybrid architectures that combine Transformer and Mamba layers for customizable efficiency-performance trade-offs. Distilled from the Transformer-based decoder-only HoVLE, mmMamba-linear achieves competitive performance against existing linear and quadratic-complexity VLMs, while mmMamba-hybrid further improves performance significantly, approaching HoVLE's capabilities. At 103K tokens, mmMamba-linear demonstrates 20.6$\times$ speedup and 75.8% GPU memory reduction compared to HoVLE, while mmMamba-hybrid achieves 13.5$\times$ speedup and 60.2% memory savings. Code and models are released at https://github.com/hustvl/mmMamba
GFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Dec 03, 2024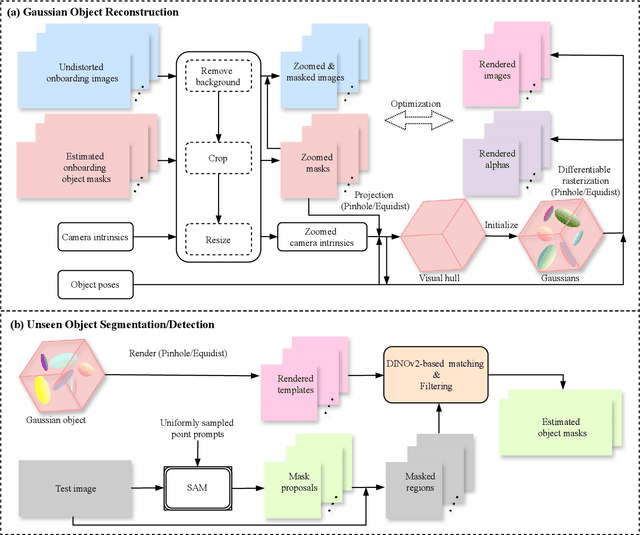

In this report, we provide the technical details of the submitted method GFreeDet, which exploits Gaussian splatting and vision Foundation models for the model-free unseen object Detection track in the BOP 2024 Challenge.
Stackelberg Driver Model for Continual Policy Improvement in Scenario-Based Closed-Loop Autonomous Driving
Sep 25, 2023The deployment of autonomous vehicles (AVs) has faced hurdles due to the dominance of rare but critical corner cases within the long-tail distribution of driving scenarios, which negatively affects their overall performance. To address this challenge, adversarial generation methods have emerged as a class of efficient approaches to synthesize safety-critical scenarios for AV testing. However, these generated scenarios are often underutilized for AV training, resulting in the potential for continual AV policy improvement remaining untapped, along with a deficiency in the closed-loop design needed to achieve it. Therefore, we tailor the Stackelberg Driver Model (SDM) to accurately characterize the hierarchical nature of vehicle interaction dynamics, facilitating iterative improvement by engaging background vehicles (BVs) and AV in a sequential game-like interaction paradigm. With AV acting as the leader and BVs as followers, this leader-follower modeling ensures that AV would consistently refine its policy, always taking into account the additional information that BVs play the best response to challenge AV. Extensive experiments have shown that our algorithm exhibits superior performance compared to several baselines especially in higher dimensional scenarios, leading to substantial advancements in AV capabilities while continually generating progressively challenging scenarios.
WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation
Apr 27, 2023This paper explores the properties of the plain Vision Transformer (ViT) for Weakly-supervised Semantic Segmentation (WSSS). The class activation map (CAM) is of critical importance for understanding a classification network and launching WSSS. We observe that different attention heads of ViT focus on different image areas. Thus a novel weight-based method is proposed to end-to-end estimate the importance of attention heads, while the self-attention maps are adaptively fused for high-quality CAM results that tend to have more complete objects. Besides, we propose a ViT-based gradient clipping decoder for online retraining with the CAM results to complete the WSSS task. We name this plain Transformer-based Weakly-supervised learning framework WeakTr. It achieves the state-of-the-art WSSS performance on standard benchmarks, i.e., 78.4% mIoU on the val set of PASCAL VOC 2012 and 50.3% mIoU on the val set of COCO 2014. Code is available at https://github.com/hustvl/WeakTr.