 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing VLA Potentials in Autonomous Driving via Explicit Learning from Failures
Mar 01, 2026Vision-Language-Action (VLA) models for autonomous driving often hit a performance plateau during Reinforcement Learning (RL) optimization. This stagnation arises from exploration capabilities constrained by previous Supervised Fine-Tuning (SFT), leading to persistent failures in long-tail scenarios. In these critical situations, all explored actions yield a zero-value driving score. This information-sparse reward signals a failure, yet fails to identify its root cause -- whether it is due to incorrect planning, flawed reasoning, or poor trajectory execution. To address this limitation, we propose VLA with Explicit Learning from Failures (ELF-VLA), a framework that augments RL with structured diagnostic feedback. Instead of relying on a vague scalar reward, our method produces detailed, interpretable reports that identify the specific failure mode. The VLA policy then leverages this explicit feedback to generate a Feedback-Guided Refinement. By injecting these corrected, high-reward samples back into the RL training batch, our approach provides a targeted gradient, which enables the policy to solve critical scenarios that unguided exploration cannot. Extensive experiments demonstrate that our method unlocks the latent capabilities of VLA models, achieving state-of-the-art (SOTA) performance on the public NAVSIM benchmark for overall PDMS, EPDMS score and high-level planning accuracy.
VILTA: A VLM-in-the-Loop Adversary for Enhancing Driving Policy Robustness
Jan 19, 2026The safe deployment of autonomous driving (AD) systems is fundamentally hindered by the long-tail problem, where rare yet critical driving scenarios are severely underrepresented in real-world data. Existing solutions including safety-critical scenario generation and closed-loop learning often rely on rule-based heuristics, resampling methods and generative models learned from offline datasets, limiting their ability to produce diverse and novel challenges. While recent works leverage Vision Language Models (VLMs) to produce scene descriptions that guide a separate, downstream model in generating hazardous trajectories for agents, such two-stage framework constrains the generative potential of VLMs, as the diversity of the final trajectories is ultimately limited by the generalization ceiling of the downstream algorithm. To overcome these limitations, we introduce VILTA (VLM-In-the-Loop Trajectory Adversary), a novel framework that integrates a VLM into the closed-loop training of AD agents. Unlike prior works, VILTA actively participates in the training loop by comprehending the dynamic driving environment and strategically generating challenging scenarios through direct, fine-grained editing of surrounding agents' future trajectories. This direct-editing approach fully leverages the VLM's powerful generalization capabilities to create a diverse curriculum of plausible yet challenging scenarios that extend beyond the scope of traditional methods. We demonstrate that our approach substantially enhances the safety and robustness of the resulting AD policy, particularly in its ability to navigate critical long-tail events.
xTED: Cross-Domain Policy Adaptation via Diffusion-Based Trajectory Editing
Sep 13, 2024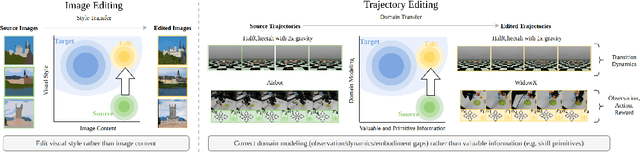
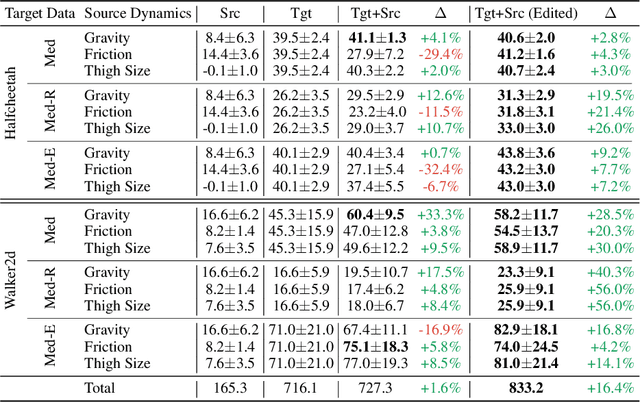
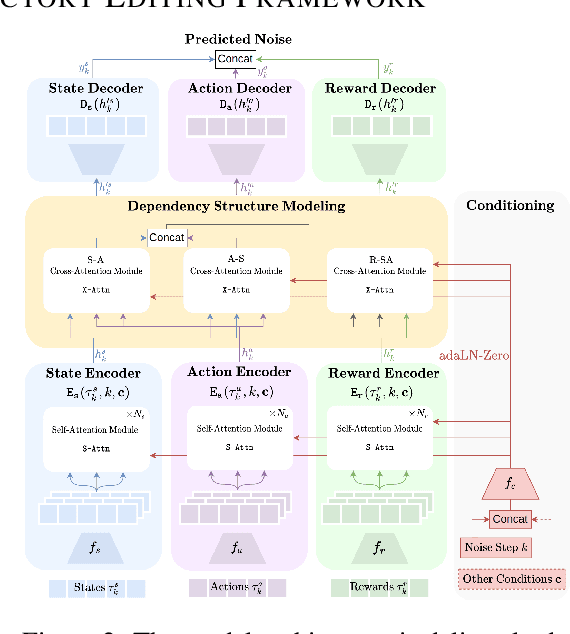

Reusing pre-collected data from different domains is an attractive solution in decision-making tasks where the accessible data is insufficient in the target domain but relatively abundant in other related domains. Existing cross-domain policy transfer methods mostly aim at learning domain correspondences or corrections to facilitate policy learning, which requires learning domain/task-specific model components, representations, or policies that are inflexible or not fully reusable to accommodate arbitrary domains and tasks. These issues make us wonder: can we directly bridge the domain gap at the data (trajectory) level, instead of devising complicated, domain-specific policy transfer models? In this study, we propose a Cross-Domain Trajectory EDiting (xTED) framework with a new diffusion transformer model (Decision Diffusion Transformer, DDiT) that captures the trajectory distribution from the target dataset as a prior. The proposed diffusion transformer backbone captures the intricate dependencies among state, action, and reward sequences, as well as the transition dynamics within the target data trajectories. With the above pre-trained diffusion prior, source data trajectories with domain gaps can be transformed into edited trajectories that closely resemble the target data distribution through the diffusion-based editing process, which implicitly corrects the underlying domain gaps, enhancing the state realism and dynamics reliability in source trajectory data, while enabling flexible choices of downstream policy learning methods. Despite its simplicity, xTED demonstrates superior performance against other baselines in extensive simulation and real-robot experiments.
Stackelberg Driver Model for Continual Policy Improvement in Scenario-Based Closed-Loop Autonomous Driving
Sep 25, 2023The deployment of autonomous vehicles (AVs) has faced hurdles due to the dominance of rare but critical corner cases within the long-tail distribution of driving scenarios, which negatively affects their overall performance. To address this challenge, adversarial generation methods have emerged as a class of efficient approaches to synthesize safety-critical scenarios for AV testing. However, these generated scenarios are often underutilized for AV training, resulting in the potential for continual AV policy improvement remaining untapped, along with a deficiency in the closed-loop design needed to achieve it. Therefore, we tailor the Stackelberg Driver Model (SDM) to accurately characterize the hierarchical nature of vehicle interaction dynamics, facilitating iterative improvement by engaging background vehicles (BVs) and AV in a sequential game-like interaction paradigm. With AV acting as the leader and BVs as followers, this leader-follower modeling ensures that AV would consistently refine its policy, always taking into account the additional information that BVs play the best response to challenge AV. Extensive experiments have shown that our algorithm exhibits superior performance compared to several baselines especially in higher dimensional scenarios, leading to substantial advancements in AV capabilities while continually generating progressively challenging scenarios.