 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Policies with Value-Conditional Optimization for Offline Reinforcement Learning
Nov 12, 2025
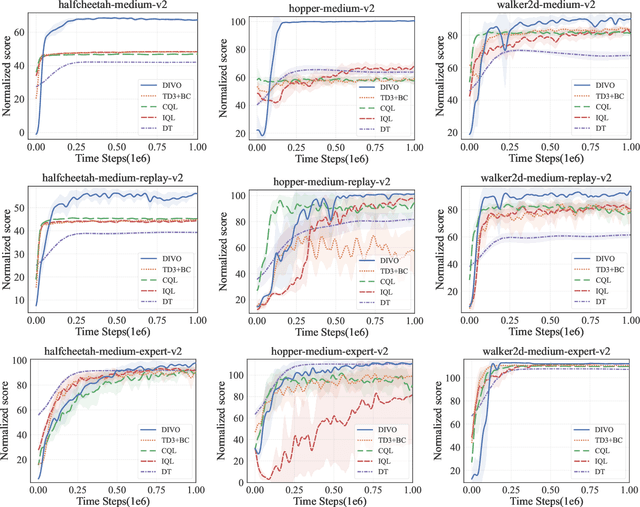

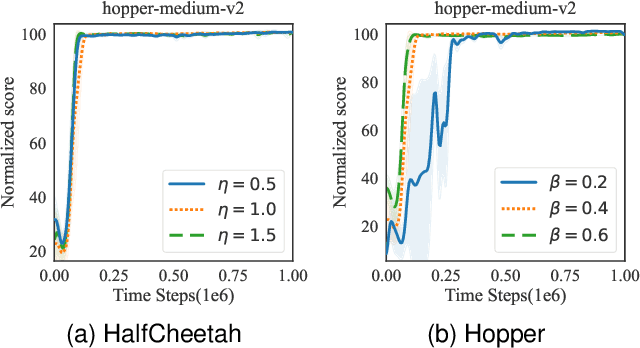
In offline reinforcement learning, value overestimation caused by out-of-distribution (OOD) actions significantly limits policy performance. Recently, diffusion models have been leveraged for their strong distribution-matching capabilities, enforcing conservatism through behavior policy constraints. However, existing methods often apply indiscriminate regularization to redundant actions in low-quality datasets, resulting in excessive conservatism and an imbalance between the expressiveness and efficiency of diffusion modeling. To address these issues, we propose DIffusion policies with Value-conditional Optimization (DIVO), a novel approach that leverages diffusion models to generate high-quality, broadly covered in-distribution state-action samples while facilitating efficient policy improvement. Specifically, DIVO introduces a binary-weighted mechanism that utilizes the advantage values of actions in the offline dataset to guide diffusion model training. This enables a more precise alignment with the dataset's distribution while selectively expanding the boundaries of high-advantage actions. During policy improvement, DIVO dynamically filters high-return-potential actions from the diffusion model, effectively guiding the learned policy toward better performance. This approach achieves a critical balance between conservatism and explorability in offline RL. We evaluate DIVO on the D4RL benchmark and compare it against state-of-the-art baselines. Empirical results demonstrate that DIVO achieves superior performance, delivering significant improvements in average returns across locomotion tasks and outperforming existing methods in the challenging AntMaze domain, where sparse rewards pose a major difficulty.
NVSPolicy: Adaptive Novel-View Synthesis for Generalizable Language-Conditioned Policy Learning
May 15, 2025



Recent advances in deep generative models demonstrate unprecedented zero-shot generalization capabilities, offering great potential for robot manipulation in unstructured environments. Given a partial observation of a scene, deep generative models could generate the unseen regions and therefore provide more context, which enhances the capability of robots to generalize across unseen environments. However, due to the visual artifacts in generated images and inefficient integration of multi-modal features in policy learning, this direction remains an open challenge. We introduce NVSPolicy, a generalizable language-conditioned policy learning method that couples an adaptive novel-view synthesis module with a hierarchical policy network. Given an input image, NVSPolicy dynamically selects an informative viewpoint and synthesizes an adaptive novel-view image to enrich the visual context. To mitigate the impact of the imperfect synthesized images, we adopt a cycle-consistent VAE mechanism that disentangles the visual features into the semantic feature and the remaining feature. The two features are then fed into the hierarchical policy network respectively: the semantic feature informs the high-level meta-skill selection, and the remaining feature guides low-level action estimation. Moreover, we propose several practical mechanisms to make the proposed method efficient. Extensive experiments on CALVIN demonstrate the state-of-the-art performance of our method. Specifically, it achieves an average success rate of 90.4\% across all tasks, greatly outperforming the recent methods. Ablation studies confirm the significance of our adaptive novel-view synthesis paradigm. In addition, we evaluate NVSPolicy on a real-world robotic platform to demonstrate its practical applicability.
Skill Expansion and Composition in Parameter Space
Feb 09, 2025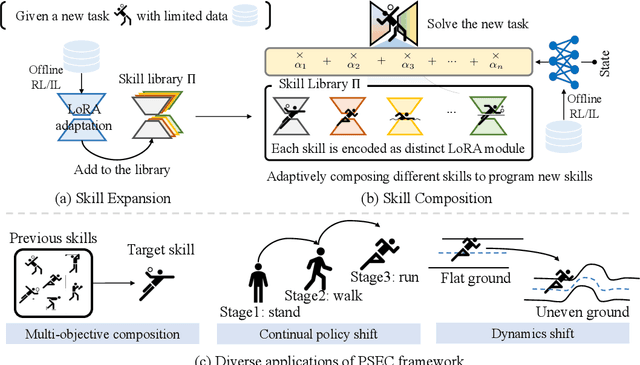
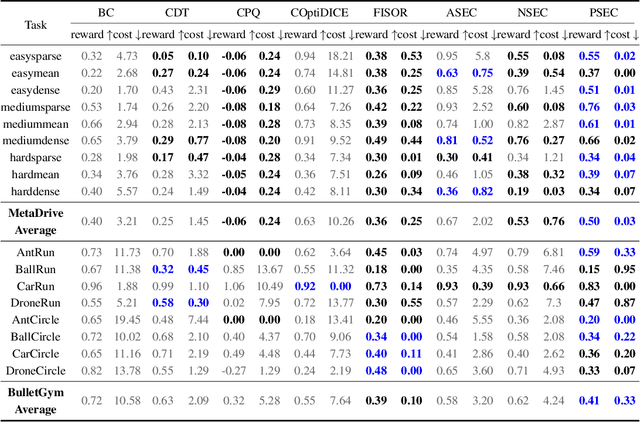
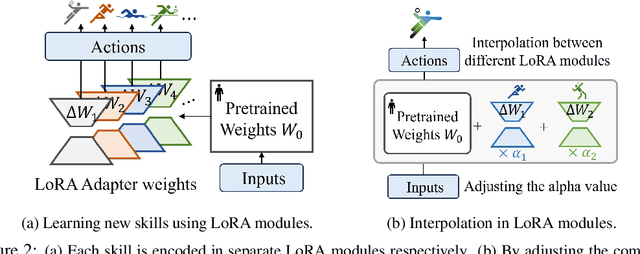
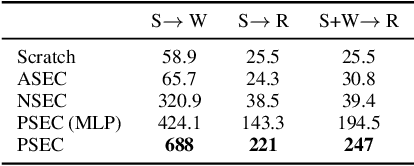
Humans excel at reusing prior knowledge to address new challenges and developing skills while solving problems. This paradigm becomes increasingly popular in the development of autonomous agents, as it develops systems that can self-evolve in response to new challenges like human beings. However, previous methods suffer from limited training efficiency when expanding new skills and fail to fully leverage prior knowledge to facilitate new task learning. In this paper, we propose Parametric Skill Expansion and Composition (PSEC), a new framework designed to iteratively evolve the agents' capabilities and efficiently address new challenges by maintaining a manageable skill library. This library can progressively integrate skill primitives as plug-and-play Low-Rank Adaptation (LoRA) modules in parameter-efficient finetuning, facilitating efficient and flexible skill expansion. This structure also enables the direct skill compositions in parameter space by merging LoRA modules that encode different skills, leveraging shared information across skills to effectively program new skills. Based on this, we propose a context-aware module to dynamically activate different skills to collaboratively handle new tasks. Empowering diverse applications including multi-objective composition, dynamics shift, and continual policy shift, the results on D4RL, DSRL benchmarks, and the DeepMind Control Suite show that PSEC exhibits superior capacity to leverage prior knowledge to efficiently tackle new challenges, as well as expand its skill libraries to evolve the capabilities. Project website: https://ltlhuuu.github.io/PSEC/.
xTED: Cross-Domain Policy Adaptation via Diffusion-Based Trajectory Editing
Sep 13, 2024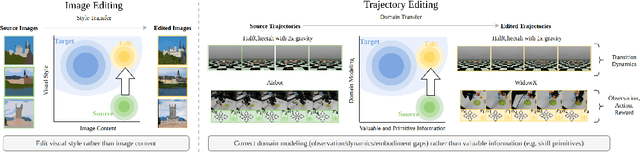
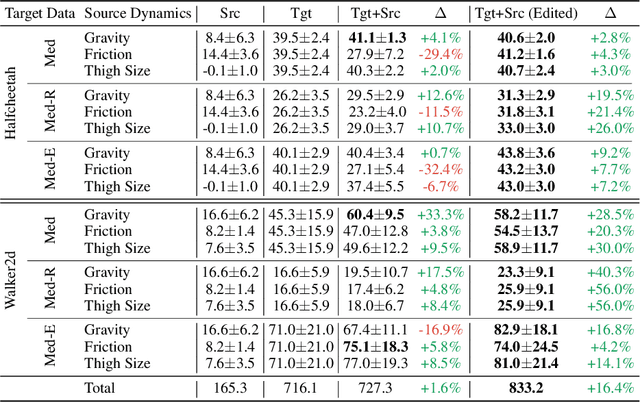
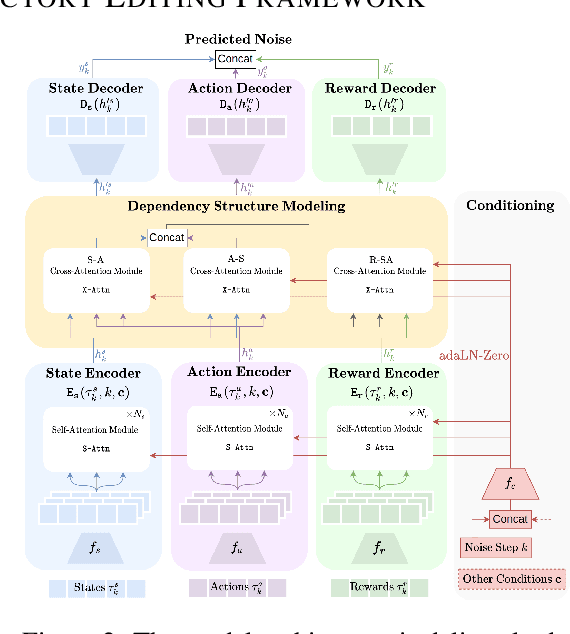

Reusing pre-collected data from different domains is an attractive solution in decision-making tasks where the accessible data is insufficient in the target domain but relatively abundant in other related domains. Existing cross-domain policy transfer methods mostly aim at learning domain correspondences or corrections to facilitate policy learning, which requires learning domain/task-specific model components, representations, or policies that are inflexible or not fully reusable to accommodate arbitrary domains and tasks. These issues make us wonder: can we directly bridge the domain gap at the data (trajectory) level, instead of devising complicated, domain-specific policy transfer models? In this study, we propose a Cross-Domain Trajectory EDiting (xTED) framework with a new diffusion transformer model (Decision Diffusion Transformer, DDiT) that captures the trajectory distribution from the target dataset as a prior. The proposed diffusion transformer backbone captures the intricate dependencies among state, action, and reward sequences, as well as the transition dynamics within the target data trajectories. With the above pre-trained diffusion prior, source data trajectories with domain gaps can be transformed into edited trajectories that closely resemble the target data distribution through the diffusion-based editing process, which implicitly corrects the underlying domain gaps, enhancing the state realism and dynamics reliability in source trajectory data, while enabling flexible choices of downstream policy learning methods. Despite its simplicity, xTED demonstrates superior performance against other baselines in extensive simulation and real-robot experiments.
Adaptive Advantage-Guided Policy Regularization for Offline Reinforcement Learning
Jun 01, 2024In offline reinforcement learning, the challenge of out-of-distribution (OOD) is pronounced. To address this, existing methods often constrain the learned policy through policy regularization. However, these methods often suffer from the issue of unnecessary conservativeness, hampering policy improvement. This occurs due to the indiscriminate use of all actions from the behavior policy that generates the offline dataset as constraints. The problem becomes particularly noticeable when the quality of the dataset is suboptimal. Thus, we propose Adaptive Advantage-guided Policy Regularization (A2PR), obtaining high-advantage actions from an augmented behavior policy combined with VAE to guide the learned policy. A2PR can select high-advantage actions that differ from those present in the dataset, while still effectively maintaining conservatism from OOD actions. This is achieved by harnessing the VAE capacity to generate samples matching the distribution of the data points. We theoretically prove that the improvement of the behavior policy is guaranteed. Besides, it effectively mitigates value overestimation with a bounded performance gap. Empirically, we conduct a series of experiments on the D4RL benchmark, where A2PR demonstrates state-of-the-art performance. Furthermore, experimental results on additional suboptimal mixed datasets reveal that A2PR exhibits superior performance. Code is available at https://github.com/ltlhuuu/A2PR.