 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Positive-Incentive Point Sampling in Neural Implicit Fields for Object Pose Estimation
Feb 23, 2026Learning neural implicit fields of 3D shapes is a rapidly emerging field that enables shape representation at arbitrary resolutions. Due to the flexibility, neural implicit fields have succeeded in many research areas, including shape reconstruction, novel view image synthesis, and more recently, object pose estimation. Neural implicit fields enable learning dense correspondences between the camera space and the object's canonical space-including unobserved regions in camera space-significantly boosting object pose estimation performance in challenging scenarios like highly occluded objects and novel shapes. Despite progress, predicting canonical coordinates for unobserved camera-space regions remains challenging due to the lack of direct observational signals. This necessitates heavy reliance on the model's generalization ability, resulting in high uncertainty. Consequently, densely sampling points across the entire camera space may yield inaccurate estimations that hinder the learning process and compromise performance. To alleviate this problem, we propose a method combining an SO(3)-equivariant convolutional implicit network and a positive-incentive point sampling (PIPS) strategy. The SO(3)-equivariant convolutional implicit network estimates point-level attributes with SO(3)-equivariance at arbitrary query locations, demonstrating superior performance compared to most existing baselines. The PIPS strategy dynamically determines sampling locations based on the input, thereby boosting the network's accuracy and training efficiency. Our method outperforms the state-of-the-art on three pose estimation datasets. Notably, it demonstrates significant improvements in challenging scenarios, such as objects captured with unseen pose, high occlusion, novel geometry, and severe noise.
Machine Learning for Energy-Performance-aware Scheduling
Jan 30, 2026In the post-Dennard era, optimizing embedded systems requires navigating complex trade-offs between energy efficiency and latency. Traditional heuristic tuning is often inefficient in such high-dimensional, non-smooth landscapes. In this work, we propose a Bayesian Optimization framework using Gaussian Processes to automate the search for optimal scheduling configurations on heterogeneous multi-core architectures. We explicitly address the multi-objective nature of the problem by approximating the Pareto Frontier between energy and time. Furthermore, by incorporating Sensitivity Analysis (fANOVA) and comparing different covariance kernels (e.g., Matérn vs. RBF), we provide physical interpretability to the black-box model, revealing the dominant hardware parameters driving system performance.
Trusted Multi-view Learning for Long-tailed Classification
Nov 12, 2025Class imbalance has been extensively studied in single-view scenarios; however, addressing this challenge in multi-view contexts remains an open problem, with even scarcer research focusing on trustworthy solutions. In this paper, we tackle a particularly challenging class imbalance problem in multi-view scenarios: long-tailed classification. We propose TMLC, a Trusted Multi-view Long-tailed Classification framework, which makes contributions on two critical aspects: opinion aggregation and pseudo-data generation. Specifically, inspired by Social Identity Theory, we design a group consensus opinion aggregation mechanism that guides decision making toward the direction favored by the majority of the group. In terms of pseudo-data generation, we introduce a novel distance metric to adapt SMOTE for multi-view scenarios and develop an uncertainty-guided data generation module that produces high-quality pseudo-data, effectively mitigating the adverse effects of class imbalance. Extensive experiments on long-tailed multi-view datasets demonstrate that our model is capable of achieving superior performance. The code is released at https://github.com/cncq-tang/TMLC.
PartDexTOG: Generating Dexterous Task-Oriented Grasping via Language-driven Part Analysis
May 18, 2025Task-oriented grasping is a crucial yet challenging task in robotic manipulation. Despite the recent progress, few existing methods address task-oriented grasping with dexterous hands. Dexterous hands provide better precision and versatility, enabling robots to perform task-oriented grasping more effectively. In this paper, we argue that part analysis can enhance dexterous grasping by providing detailed information about the object's functionality. We propose PartDexTOG, a method that generates dexterous task-oriented grasps via language-driven part analysis. Taking a 3D object and a manipulation task represented by language as input, the method first generates the category-level and part-level grasp descriptions w.r.t the manipulation task by LLMs. Then, a category-part conditional diffusion model is developed to generate a dexterous grasp for each part, respectively, based on the generated descriptions. To select the most plausible combination of grasp and corresponding part from the generated ones, we propose a measure of geometric consistency between grasp and part. We show that our method greatly benefits from the open-world knowledge reasoning on object parts by LLMs, which naturally facilitates the learning of grasp generation on objects with different geometry and for different manipulation tasks. Our method ranks top on the OakInk-shape dataset over all previous methods, improving the Penetration Volume, the Grasp Displace, and the P-FID over the state-of-the-art by $3.58\%$, $2.87\%$, and $41.43\%$, respectively. Notably, it demonstrates good generality in handling novel categories and tasks.
NVSPolicy: Adaptive Novel-View Synthesis for Generalizable Language-Conditioned Policy Learning
May 15, 2025



Recent advances in deep generative models demonstrate unprecedented zero-shot generalization capabilities, offering great potential for robot manipulation in unstructured environments. Given a partial observation of a scene, deep generative models could generate the unseen regions and therefore provide more context, which enhances the capability of robots to generalize across unseen environments. However, due to the visual artifacts in generated images and inefficient integration of multi-modal features in policy learning, this direction remains an open challenge. We introduce NVSPolicy, a generalizable language-conditioned policy learning method that couples an adaptive novel-view synthesis module with a hierarchical policy network. Given an input image, NVSPolicy dynamically selects an informative viewpoint and synthesizes an adaptive novel-view image to enrich the visual context. To mitigate the impact of the imperfect synthesized images, we adopt a cycle-consistent VAE mechanism that disentangles the visual features into the semantic feature and the remaining feature. The two features are then fed into the hierarchical policy network respectively: the semantic feature informs the high-level meta-skill selection, and the remaining feature guides low-level action estimation. Moreover, we propose several practical mechanisms to make the proposed method efficient. Extensive experiments on CALVIN demonstrate the state-of-the-art performance of our method. Specifically, it achieves an average success rate of 90.4\% across all tasks, greatly outperforming the recent methods. Ablation studies confirm the significance of our adaptive novel-view synthesis paradigm. In addition, we evaluate NVSPolicy on a real-world robotic platform to demonstrate its practical applicability.
DK-SLAM: Monocular Visual SLAM with Deep Keypoints Adaptive Learning, Tracking and Loop-Closing
Jan 17, 2024



Unreliable feature extraction and matching in handcrafted features undermine the performance of visual SLAM in complex real-world scenarios. While learned local features, leveraging CNNs, demonstrate proficiency in capturing high-level information and excel in matching benchmarks, they encounter challenges in continuous motion scenes, resulting in poor generalization and impacting loop detection accuracy. To address these issues, we present DK-SLAM, a monocular visual SLAM system with adaptive deep local features. MAML optimizes the training of these features, and we introduce a coarse-to-fine feature tracking approach. Initially, a direct method approximates the relative pose between consecutive frames, followed by a feature matching method for refined pose estimation. To counter cumulative positioning errors, a novel online learning binary feature-based online loop closure module identifies loop nodes within a sequence. Experimental results underscore DK-SLAM's efficacy, outperforms representative SLAM solutions, such as ORB-SLAM3 on publicly available datasets.
Continual Learning through Networks Splitting and Merging with Dreaming-Meta-Weighted Model Fusion
Dec 12, 2023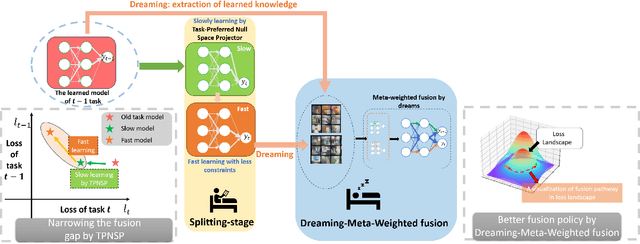
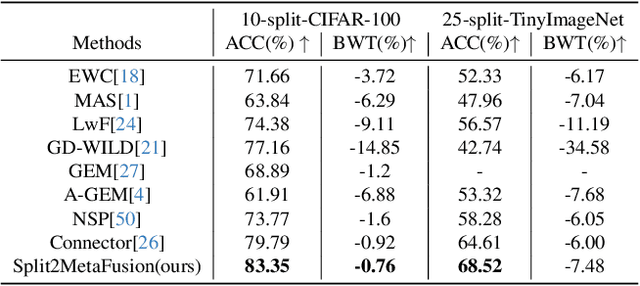
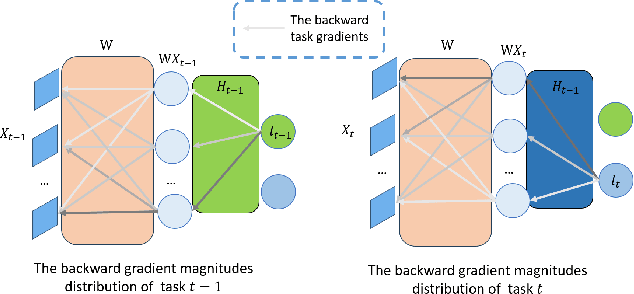

It's challenging to balance the networks stability and plasticity in continual learning scenarios, considering stability suffers from the update of model and plasticity benefits from it. Existing works usually focus more on the stability and restrict the learning plasticity of later tasks to avoid catastrophic forgetting of learned knowledge. Differently, we propose a continual learning method named Split2MetaFusion which can achieve better trade-off by employing a two-stage strategy: splitting and meta-weighted fusion. In this strategy, a slow model with better stability, and a fast model with better plasticity are learned sequentially at the splitting stage. Then stability and plasticity are both kept by fusing the two models in an adaptive manner. Towards this end, we design an optimizer named Task-Preferred Null Space Projector(TPNSP) to the slow learning process for narrowing the fusion gap. To achieve better model fusion, we further design a Dreaming-Meta-Weighted fusion policy for better maintaining the old and new knowledge simultaneously, which doesn't require to use the previous datasets. Experimental results and analysis reported in this work demonstrate the superiority of the proposed method for maintaining networks stability and keeping its plasticity. Our code will be released.
SuperUDF: Self-supervised UDF Estimation for Surface Reconstruction
Aug 28, 2023Learning-based surface reconstruction based on unsigned distance functions (UDF) has many advantages such as handling open surfaces. We propose SuperUDF, a self-supervised UDF learning which exploits a learned geometry prior for efficient training and a novel regularization for robustness to sparse sampling. The core idea of SuperUDF draws inspiration from the classical surface approximation operator of locally optimal projection (LOP). The key insight is that if the UDF is estimated correctly, the 3D points should be locally projected onto the underlying surface following the gradient of the UDF. Based on that, a number of inductive biases on UDF geometry and a pre-learned geometry prior are devised to learn UDF estimation efficiently. A novel regularization loss is proposed to make SuperUDF robust to sparse sampling. Furthermore, we also contribute a learning-based mesh extraction from the estimated UDFs. Extensive evaluations demonstrate that SuperUDF outperforms the state of the arts on several public datasets in terms of both quality and efficiency. Code will be released after accteptance.
RayMVSNet++: Learning Ray-based 1D Implicit Fields for Accurate Multi-View Stereo
Jul 16, 2023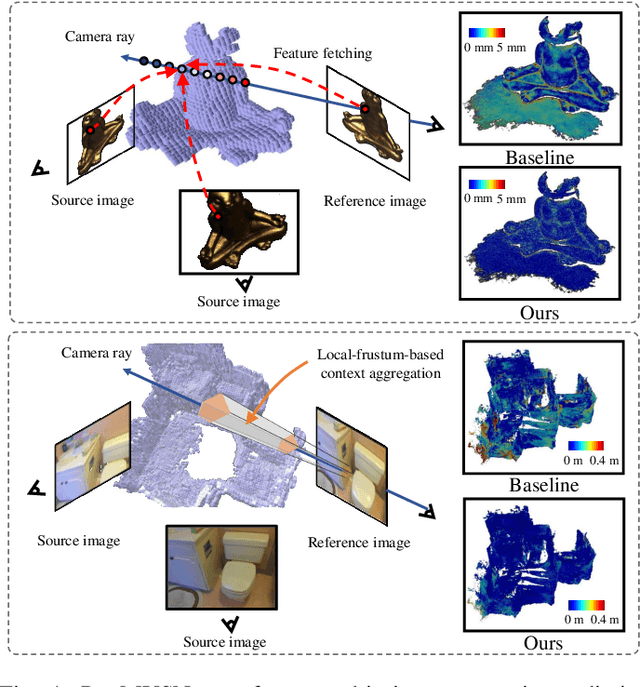
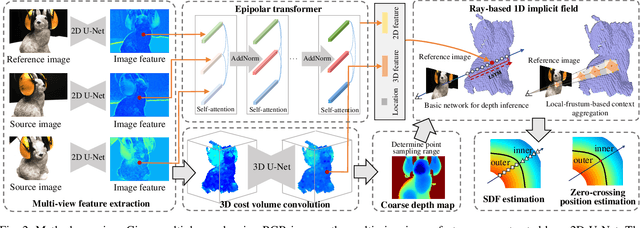
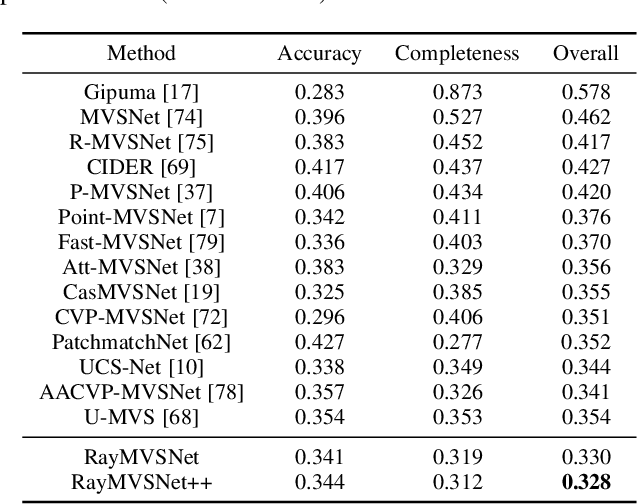
Learning-based multi-view stereo (MVS) has by far centered around 3D convolution on cost volumes. Due to the high computation and memory consumption of 3D CNN, the resolution of output depth is often considerably limited. Different from most existing works dedicated to adaptive refinement of cost volumes, we opt to directly optimize the depth value along each camera ray, mimicking the range finding of a laser scanner. This reduces the MVS problem to ray-based depth optimization which is much more light-weight than full cost volume optimization. In particular, we propose RayMVSNet which learns sequential prediction of a 1D implicit field along each camera ray with the zero-crossing point indicating scene depth. This sequential modeling, conducted based on transformer features, essentially learns the epipolar line search in traditional multi-view stereo. We devise a multi-task learning for better optimization convergence and depth accuracy. We found the monotonicity property of the SDFs along each ray greatly benefits the depth estimation. Our method ranks top on both the DTU and the Tanks & Temples datasets over all previous learning-based methods, achieving an overall reconstruction score of 0.33mm on DTU and an F-score of 59.48% on Tanks & Temples. It is able to produce high-quality depth estimation and point cloud reconstruction in challenging scenarios such as objects/scenes with non-textured surface, severe occlusion, and highly varying depth range. Further, we propose RayMVSNet++ to enhance contextual feature aggregation for each ray through designing an attentional gating unit to select semantically relevant neighboring rays within the local frustum around that ray. RayMVSNet++ achieves state-of-the-art performance on the ScanNet dataset. In particular, it attains an AbsRel of 0.058m and produces accurate results on the two subsets of textureless regions and large depth variation.
Learning Task-preferred Inference Routes for Gradient De-conflict in Multi-output DNNs
May 31, 2023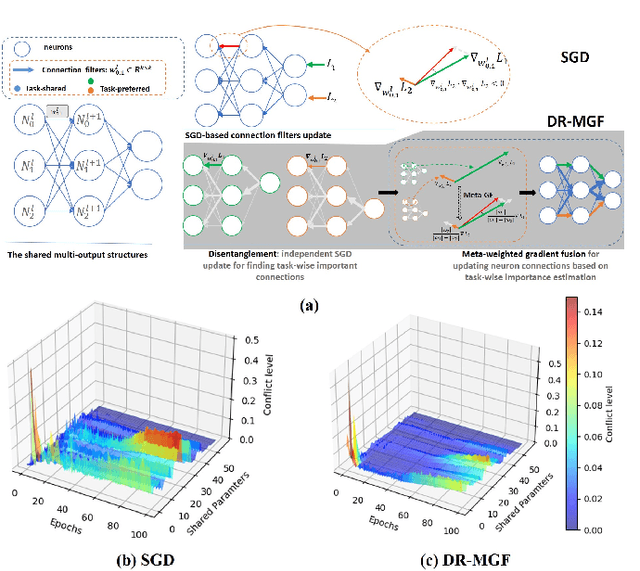

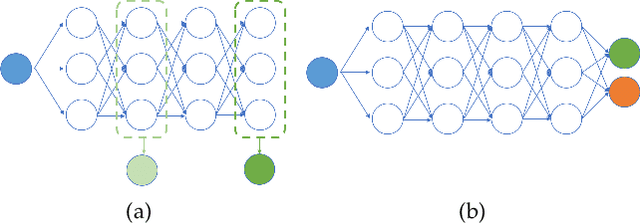

Multi-output deep neural networks(MONs) contain multiple task branches, and these tasks usually share partial network filters that lead to the entanglement of different task inference routes. Due to the inconsistent optimization objectives, the task gradients used for training MONs will interfere with each other on the shared routes, which will decrease the overall model performance. To address this issue, we propose a novel gradient de-conflict algorithm named DR-MGF(Dynamic Routes and Meta-weighted Gradient Fusion) in this work. Different from existing de-conflict methods, DR-MGF achieves gradient de-conflict in MONs by learning task-preferred inference routes. The proposed method is motivated by our experimental findings: the shared filters are not equally important to different tasks. By designing the learnable task-specific importance variables, DR-MGF evaluates the importance of filters for different tasks. Through making the dominances of tasks over filters be proportional to the task-specific importance of filters, DR-MGF can effectively reduce the inter-task interference. The task-specific importance variables ultimately determine task-preferred inference routes at the end of training iterations. Extensive experimental results on CIFAR, ImageNet, and NYUv2 illustrate that DR-MGF outperforms the existing de-conflict methods both in prediction accuracy and convergence speed of MONs. Furthermore, DR-MGF can be extended to general MONs without modifying the overall network structures.