 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisARM: Displacement Aware Relation Module for 3D Detection
Mar 02, 2022
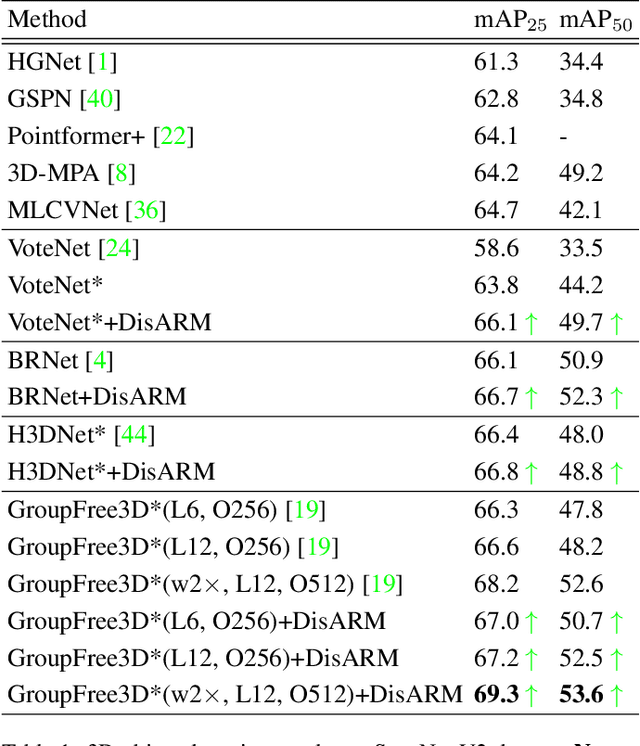
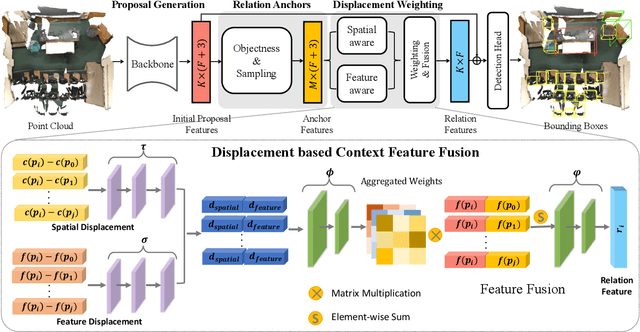
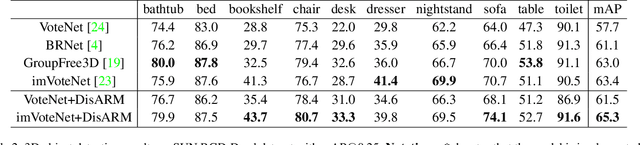
We introduce Displacement Aware Relation Module (DisARM), a novel neural network module for enhancing the performance of 3D object detection in point cloud scenes. The core idea of our method is that contextual information is critical to tell the difference when the instance geometry is incomplete or featureless. We find that relations between proposals provide a good representation to describe the context. However, adopting relations between all the object or patch proposals for detection is inefficient, and an imbalanced combination of local and global relations brings extra noise that could mislead the training. Rather than working with all relations, we found that training with relations only between the most representative ones, or anchors, can significantly boost the detection performance. A good anchor should be semantic-aware with no ambiguity and independent with other anchors as well. To find the anchors, we first perform a preliminary relation anchor module with an objectness-aware sampling approach and then devise a displacement-based module for weighing the relation importance for better utilization of contextual information. This lightweight relation module leads to significantly higher accuracy of object instance detection when being plugged into the state-of-the-art detectors. Evaluations on the public benchmarks of real-world scenes show that our method achieves state-of-the-art performance on both SUN RGB-D and ScanNet V2.
3DRM:Pair-wise relation module for 3D object detection
Feb 20, 2022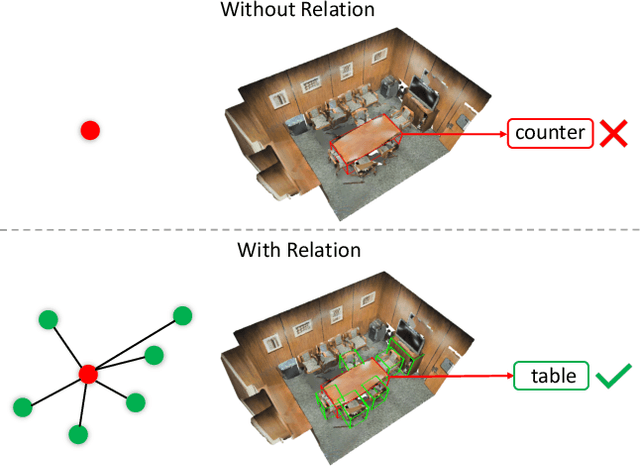
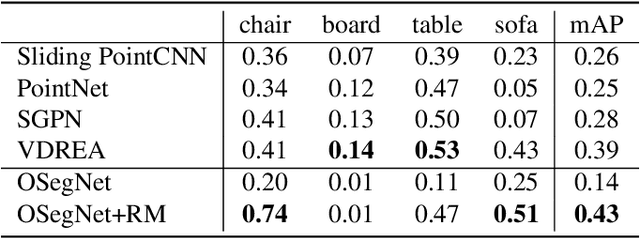
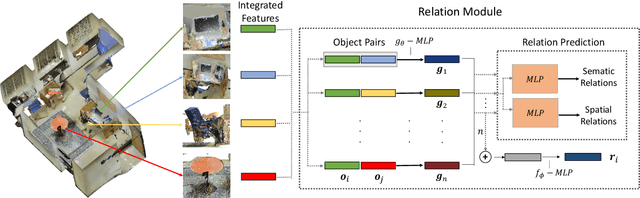
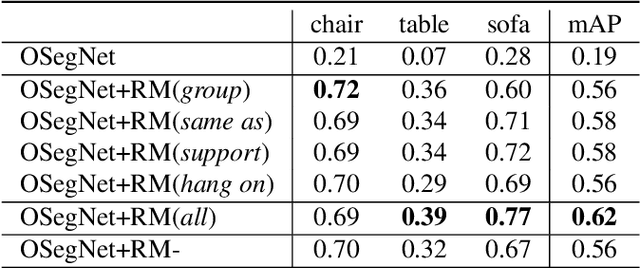
Context has proven to be one of the most important factors in object layout reasoning for 3D scene understanding. Existing deep contextual models either learn holistic features for context encoding or rely on pre-defined scene templates for context modeling. We argue that scene understanding benefits from object relation reasoning, which is capable of mitigating the ambiguity of 3D object detections and thus helps locate and classify the 3D objects more accurately and robustly. To achieve this, we propose a novel 3D relation module (3DRM) which reasons about object relations at pair-wise levels. The 3DRM predicts the semantic and spatial relationships between objects and extracts the object-wise relation features. We demonstrate the effects of 3DRM by plugging it into proposal-based and voting-based 3D object detection pipelines, respectively. Extensive evaluations show the effectiveness and generalization of 3DRM on 3D object detection. Our source code is available at https://github.com/lanlan96/3DRM.
* 13 pages, 8 figures
ARM3D: Attention-based relation module for indoor 3D object detection
Feb 20, 2022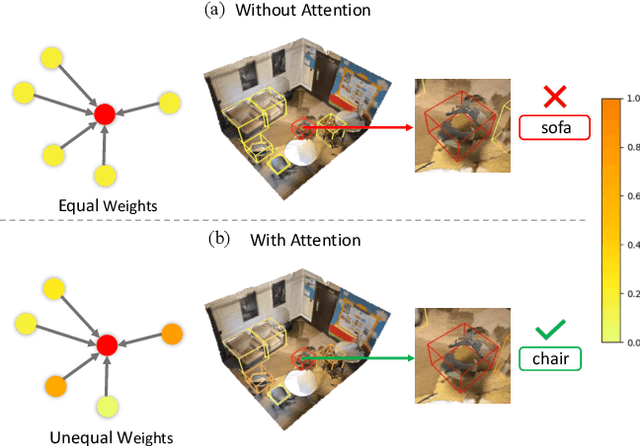

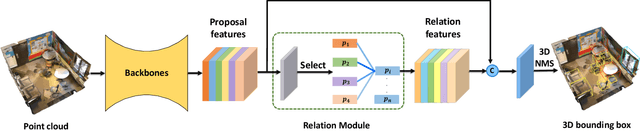
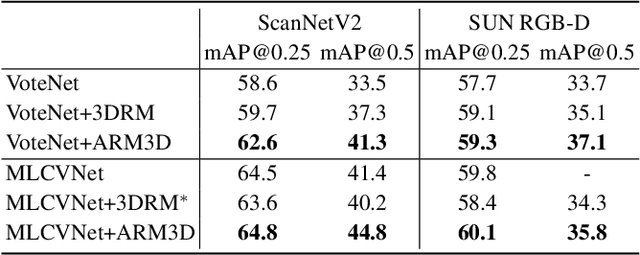
Relation context has been proved to be useful for many challenging vision tasks. In the field of 3D object detection, previous methods have been taking the advantage of context encoding, graph embedding, or explicit relation reasoning to extract relation context. However, there exists inevitably redundant relation context due to noisy or low-quality proposals. In fact, invalid relation context usually indicates underlying scene misunderstanding and ambiguity, which may, on the contrary, reduce the performance in complex scenes. Inspired by recent attention mechanism like Transformer, we propose a novel 3D attention-based relation module (ARM3D). It encompasses object-aware relation reasoning to extract pair-wise relation contexts among qualified proposals and an attention module to distribute attention weights towards different relation contexts. In this way, ARM3D can take full advantage of the useful relation context and filter those less relevant or even confusing contexts, which mitigates the ambiguity in detection. We have evaluated the effectiveness of ARM3D by plugging it into several state-of-the-art 3D object detectors and showing more accurate and robust detection results. Extensive experiments show the capability and generalization of ARM3D on 3D object detection. Our source code is available at https://github.com/lanlan96/ARM3D.
Potential Convolution: Embedding Point Clouds into Potential Fields
Apr 05, 2021

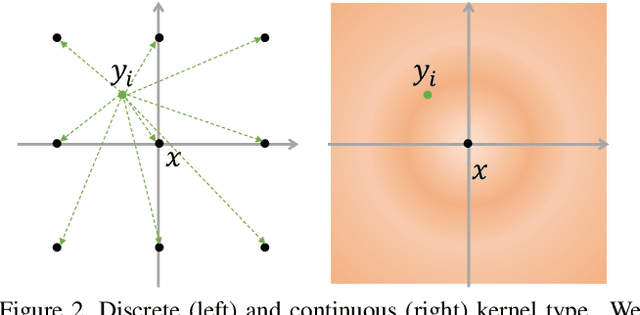
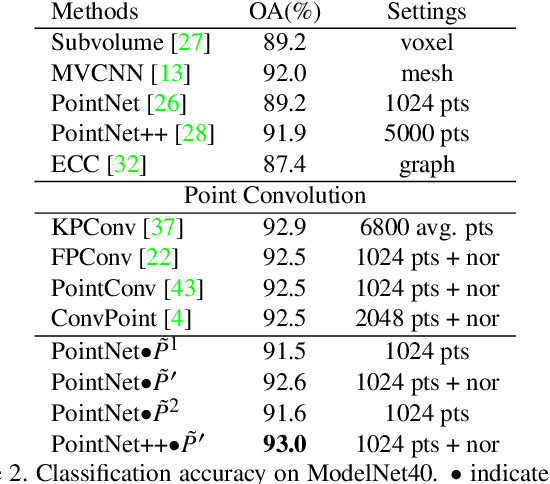
Recently, various convolutions based on continuous or discrete kernels for point cloud processing have been widely studied, and achieve impressive performance in many applications, such as shape classification, scene segmentation and so on. However, they still suffer from some drawbacks. For continuous kernels, the inaccurate estimation of the kernel weights constitutes a bottleneck for further improving the performance; while for discrete ones, the kernels represented as the points located in the 3D space are lack of rich geometry information. In this work, rather than defining a continuous or discrete kernel, we directly embed convolutional kernels into the learnable potential fields, giving rise to potential convolution. It is convenient for us to define various potential functions for potential convolution which can generalize well to a wide range of tasks. Specifically, we provide two simple yet effective potential functions via point-wise convolution operations. Comprehensive experiments demonstrate the effectiveness of our method, which achieves superior performance on the popular 3D shape classification and scene segmentation benchmarks compared with other state-of-the-art point convolution methods.