 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Image Synthesis via Next-Token Prediction
Nov 22, 2024
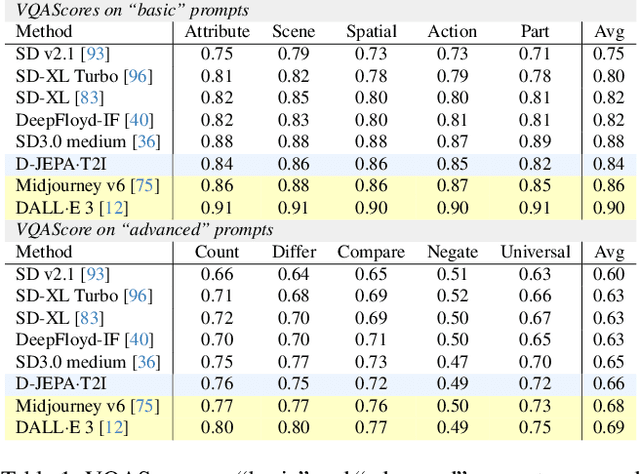

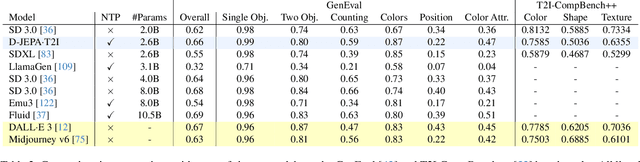
Denoising with a Joint-Embedding Predictive Architecture (D-JEPA), an autoregressive model, has demonstrated outstanding performance in class-conditional image generation. However, the application of next-token prediction in high-resolution text-to-image generation remains underexplored. In this paper, we introduce D-JEPA$\cdot$T2I, an extension of D-JEPA incorporating flow matching loss, designed to enable data-efficient continuous resolution learning. D-JEPA$\cdot$T2I leverages a multimodal visual transformer to effectively integrate textual and visual features and adopts Visual Rotary Positional Embedding (VoPE) to facilitate continuous resolution learning. Furthermore, we devise a data feedback mechanism that significantly enhances data utilization efficiency. For the first time, we achieve state-of-the-art \textbf{high-resolution} image synthesis via next-token prediction. The experimental code and pretrained models will be open-sourced at \url{https://d-jepa.github.io/t2i}.
Denoising with a Joint-Embedding Predictive Architecture
Oct 02, 2024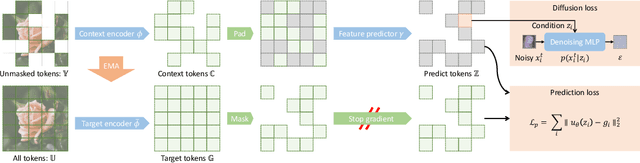
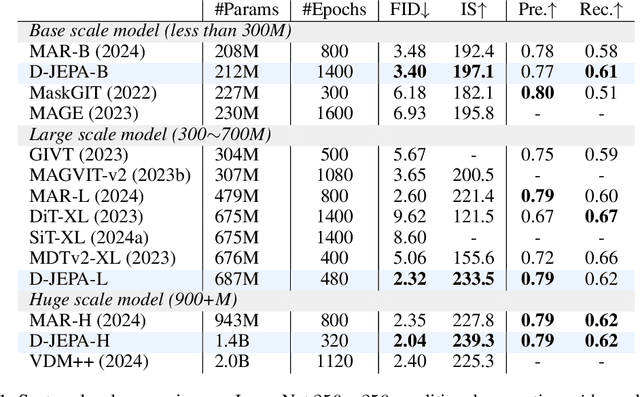
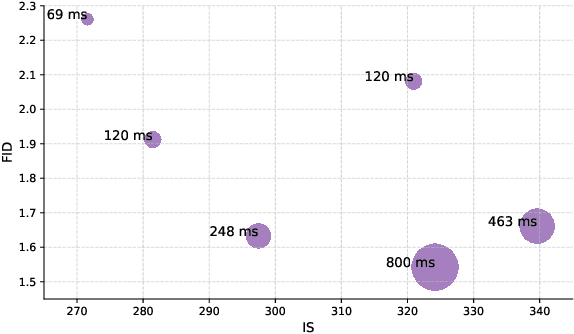
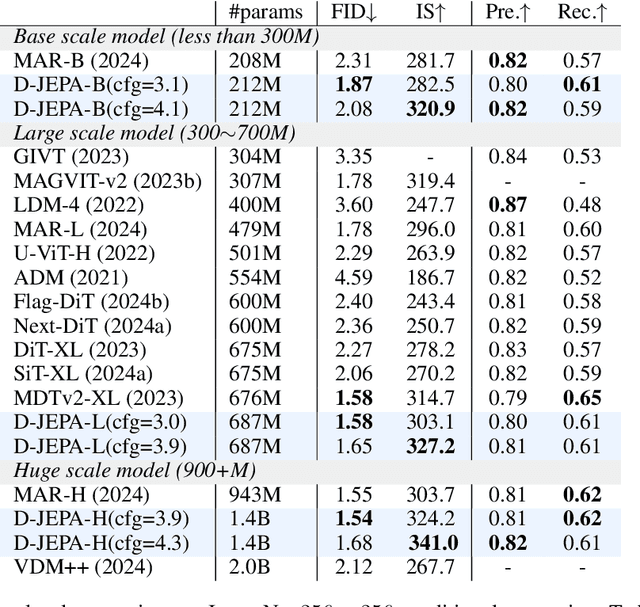
Joint-embedding predictive architectures (JEPAs) have shown substantial promise in self-supervised representation learning, yet their application in generative modeling remains underexplored. Conversely, diffusion models have demonstrated significant efficacy in modeling arbitrary probability distributions. In this paper, we introduce Denoising with a Joint-Embedding Predictive Architecture (D-JEPA), pioneering the integration of JEPA within generative modeling. By recognizing JEPA as a form of masked image modeling, we reinterpret it as a generalized next-token prediction strategy, facilitating data generation in an auto-regressive manner. Furthermore, we incorporate diffusion loss to model the per-token probability distribution, enabling data generation in a continuous space. We also adapt flow matching loss as an alternative to diffusion loss, thereby enhancing the flexibility of D-JEPA. Empirically, with increased GFLOPs, D-JEPA consistently achieves lower FID scores with fewer training epochs, indicating its good scalability. Our base, large, and huge models outperform all previous generative models across all scales on class-conditional ImageNet benchmarks. Beyond image generation, D-JEPA is well-suited for other continuous data modeling, including video and audio.
Deformable 3D Shape Diffusion Model
Jul 31, 2024



The Gaussian diffusion model, initially designed for image generation, has recently been adapted for 3D point cloud generation. However, these adaptations have not fully considered the intrinsic geometric characteristics of 3D shapes, thereby constraining the diffusion model's potential for 3D shape manipulation. To address this limitation, we introduce a novel deformable 3D shape diffusion model that facilitates comprehensive 3D shape manipulation, including point cloud generation, mesh deformation, and facial animation. Our approach innovatively incorporates a differential deformation kernel, which deconstructs the generation of geometric structures into successive non-rigid deformation stages. By leveraging a probabilistic diffusion model to simulate this step-by-step process, our method provides a versatile and efficient solution for a wide range of applications, spanning from graphics rendering to facial expression animation. Empirical evidence highlights the effectiveness of our approach, demonstrating state-of-the-art performance in point cloud generation and competitive results in mesh deformation. Additionally, extensive visual demonstrations reveal the significant potential of our approach for practical applications. Our method presents a unique pathway for advancing 3D shape manipulation and unlocking new opportunities in the realm of virtual reality.
Fine-gained Zero-shot Video Sampling
Jul 31, 2024



Incorporating a temporal dimension into pretrained image diffusion models for video generation is a prevalent approach. However, this method is computationally demanding and necessitates large-scale video datasets. More critically, the heterogeneity between image and video datasets often results in catastrophic forgetting of the image expertise. Recent attempts to directly extract video snippets from image diffusion models have somewhat mitigated these problems. Nevertheless, these methods can only generate brief video clips with simple movements and fail to capture fine-grained motion or non-grid deformation. In this paper, we propose a novel Zero-Shot video Sampling algorithm, denoted as $\mathcal{ZS}^2$, capable of directly sampling high-quality video clips from existing image synthesis methods, such as Stable Diffusion, without any training or optimization. Specifically, $\mathcal{ZS}^2$ utilizes the dependency noise model and temporal momentum attention to ensure content consistency and animation coherence, respectively. This ability enables it to excel in related tasks, such as conditional and context-specialized video generation and instruction-guided video editing. Experimental results demonstrate that $\mathcal{ZS}^2$ achieves state-of-the-art performance in zero-shot video generation, occasionally outperforming recent supervised methods. Homepage: \url{https://densechen.github.io/zss/}.
Rethinking skip connection model as a learnable Markov chain
Sep 30, 2022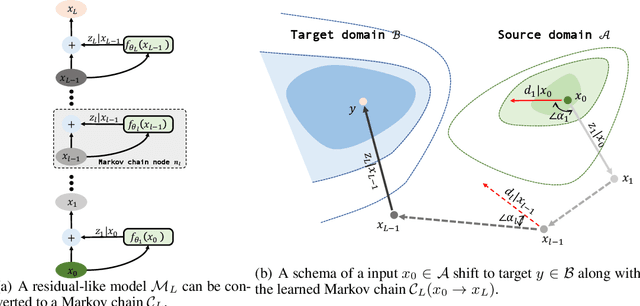

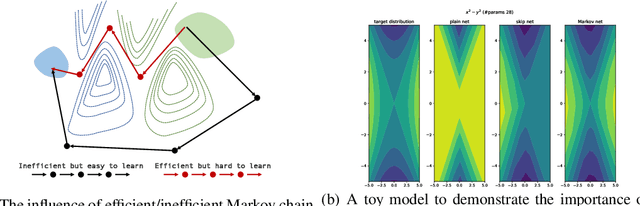

Over past few years afterward the birth of ResNet, skip connection has become the defacto standard for the design of modern architectures due to its widespread adoption, easy optimization and proven performance. Prior work has explained the effectiveness of the skip connection mechanism from different perspectives. In this work, we deep dive into the model's behaviors with skip connections which can be formulated as a learnable Markov chain. An efficient Markov chain is preferred as it always maps the input data to the target domain in a better way. However, while a model is explained as a Markov chain, it is not guaranteed to be optimized following an efficient Markov chain by existing SGD-based optimizers which are prone to get trapped in local optimal points. In order to towards a more efficient Markov chain, we propose a simple routine of penal connection to make any residual-like model become a learnable Markov chain. Aside from that, the penal connection can also be viewed as a particular model regularization and can be easily implemented with one line of code in the most popular deep learning frameworks~\footnote{Source code: \url{https://github.com/densechen/penal-connection}}. The encouraging experimental results in multi-modal translation and image recognition empirically confirm our conjecture of the learnable Markov chain view and demonstrate the superiority of the proposed penal connection.
Potential Convolution: Embedding Point Clouds into Potential Fields
Apr 05, 2021

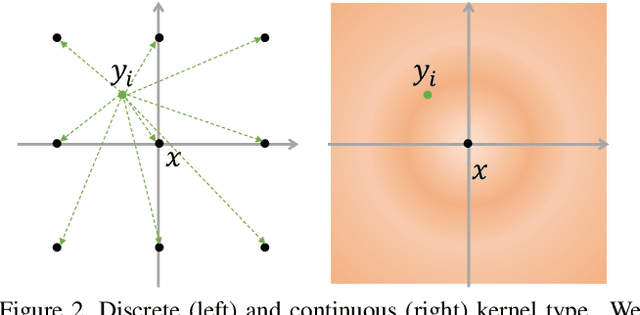
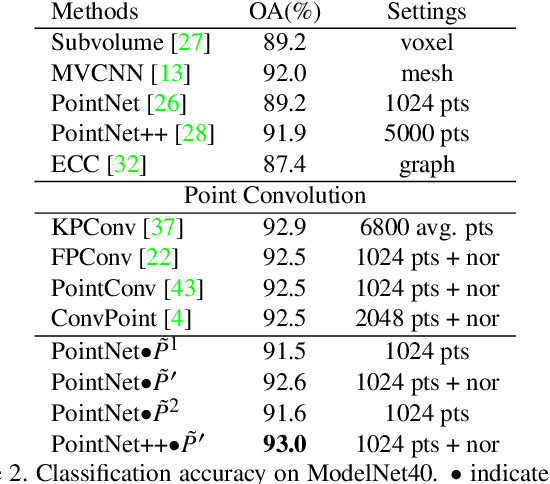
Recently, various convolutions based on continuous or discrete kernels for point cloud processing have been widely studied, and achieve impressive performance in many applications, such as shape classification, scene segmentation and so on. However, they still suffer from some drawbacks. For continuous kernels, the inaccurate estimation of the kernel weights constitutes a bottleneck for further improving the performance; while for discrete ones, the kernels represented as the points located in the 3D space are lack of rich geometry information. In this work, rather than defining a continuous or discrete kernel, we directly embed convolutional kernels into the learnable potential fields, giving rise to potential convolution. It is convenient for us to define various potential functions for potential convolution which can generalize well to a wide range of tasks. Specifically, we provide two simple yet effective potential functions via point-wise convolution operations. Comprehensive experiments demonstrate the effectiveness of our method, which achieves superior performance on the popular 3D shape classification and scene segmentation benchmarks compared with other state-of-the-art point convolution methods.
AReLU: Attention-based Rectified Linear Unit
Jun 24, 2020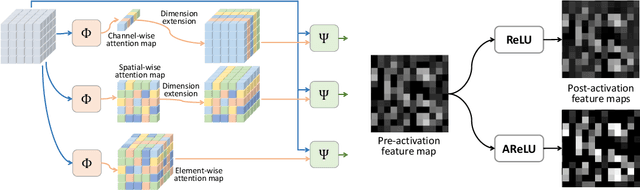
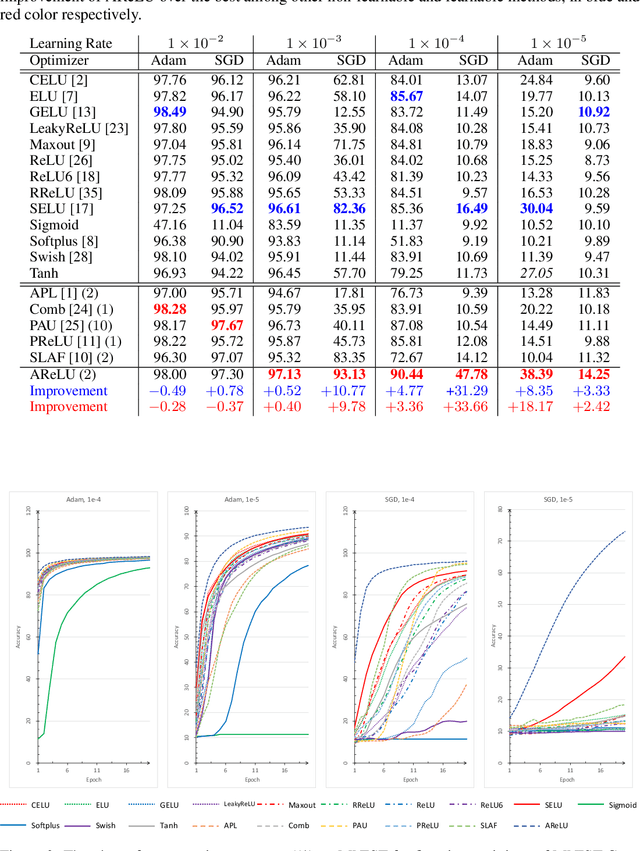
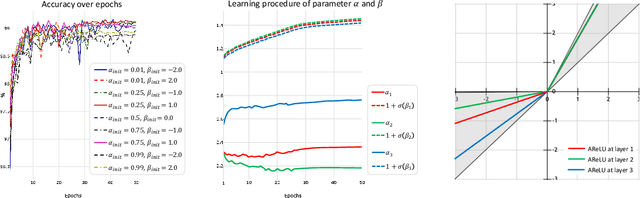
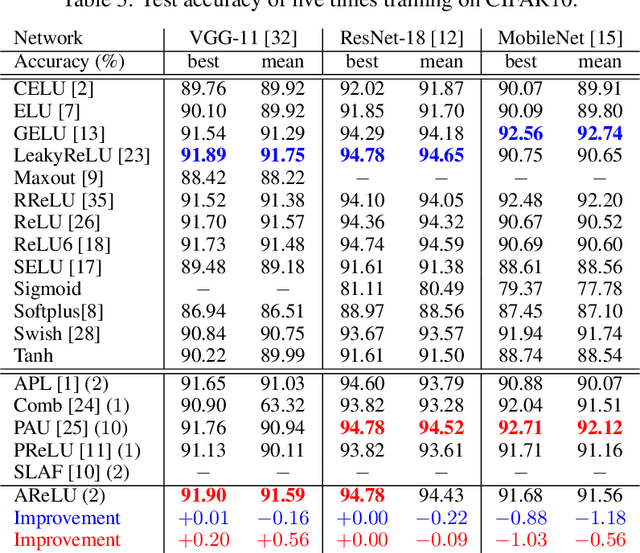
Element-wise activation functions play a critical role in deep neural networks by affecting the expressivity power and the learning dynamics. Learning-based activation functions have recently gained increasing attention and success. We propose a new perspective of learnable activation function through formulating them with element-wise attention mechanism. In each network layer, we devise an attention module which learns an element-wise, sign-based attention map for the pre-activation feature map. The attention map scales an element based on its sign. Adding the attention module with a rectified linear unit (ReLU) results in an amplification of positive elements and a suppression of negative ones, both with learned, data-adaptive parameters. We coin the resulting activation function Attention-based Rectified Linear Unit (AReLU). The attention module essentially learns an element-wise residue of the activated part of the input, as ReLU can be viewed as an identity transformation. This makes the network training more resistant to gradient vanishing. The learned attentive activation leads to well-focused activation of relevant regions of a feature map. Through extensive evaluations, we show that AReLU significantly boosts the performance of most mainstream network architectures with only two extra learnable parameters per layer introduced. Notably, AReLU facilitates fast network training under small learning rates, which makes it especially suited in the case of transfer learning. Our source code has been released (https://github.com/densechen/AReLU).
Learning Canonical Shape Space for Category-Level 6D Object Pose and Size Estimation
Jan 25, 2020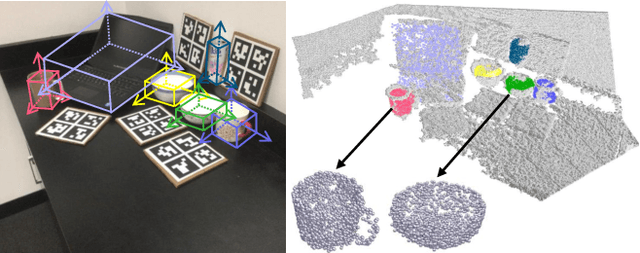
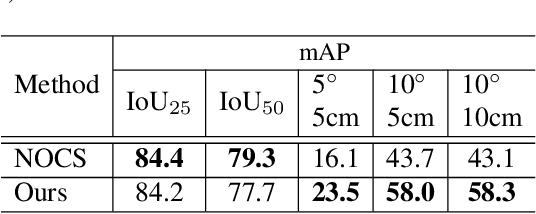
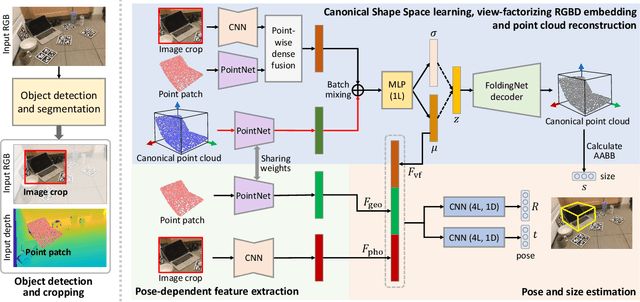
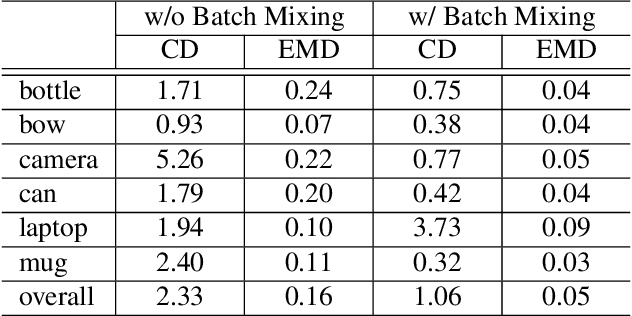
We present a novel approach to category-level 6D object pose and size estimation. To tackle intra-class shape variation, we learn canonical shape space (CASS), a unified representation for a large variety of instances of a certain object category. In particular, CASS is modeled as the latent space of a deep generative model of canonical 3D shapes with normalized pose and size. We train a variational auto-encoder (VAE) for generating 3D point clouds in the canonical space from an RGBD image. The VAE is trained in a cross-category fashion, exploiting the publicly available large 3D shape repositories. Since the 3D point cloud is generated in normalized pose and size, the encoder of the VAE learns view-factorized RGBD embedding. It maps an RGBD image in arbitrary view into a pose-independent 3D shape representation. Object pose and size are then estimated via contrasting it with a pose-dependent feature of the input RGBD extracted with a separate deep neural networks. We integrate the learning of CASS and pose and size estimation into an end-to-end trainable network, achieving the state-of-the-art pose and size accuracy.
Enhancement Mask for Hippocampus Detection and Segmentation
Feb 12, 2019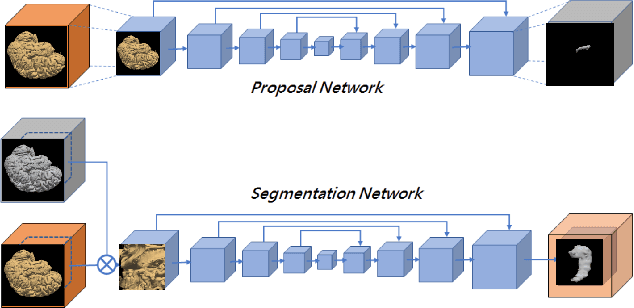

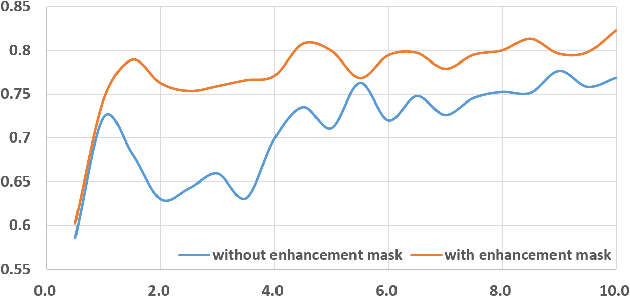
Detection and segmentation of the hippocampal structures in volumetric brain images is a challenging problem in the area of medical imaging. In this paper, we propose a two-stage 3D fully convolutional neural network that efficiently detects and segments the hippocampal structures. In particular, our approach first localizes the hippocampus from the whole volumetric image while obtaining a proposal for a rough segmentation. After localization, we apply the proposal as an enhancement mask to extract the fine structure of the hippocampus. The proposed method has been evaluated on a public dataset and compares with state-of-the-art approaches. Results indicate the effectiveness of the proposed method, which yields mean Dice Similarity Coefficients (i.e. DSC) of $0.897$ and $0.900$ for the left and right hippocampus, respectively. Furthermore, extensive experiments manifest that the proposed enhancement mask layer has remarkable benefits for accelerating training process and obtaining more accurate segmentation results.
* This paper has been published in the proceedings of IEEE International Conference on Information and Automation 2018
Deformable Object Tracking with Gated Fusion
Sep 27, 2018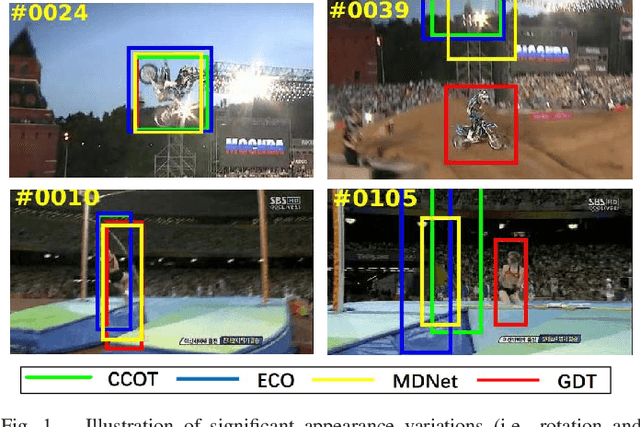

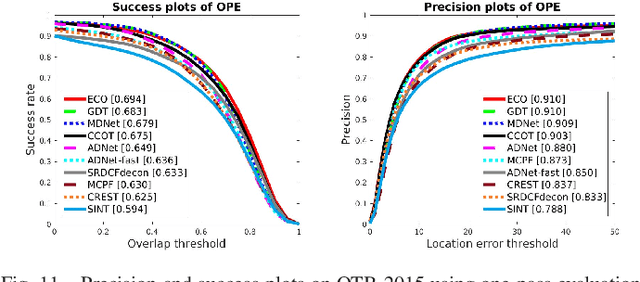
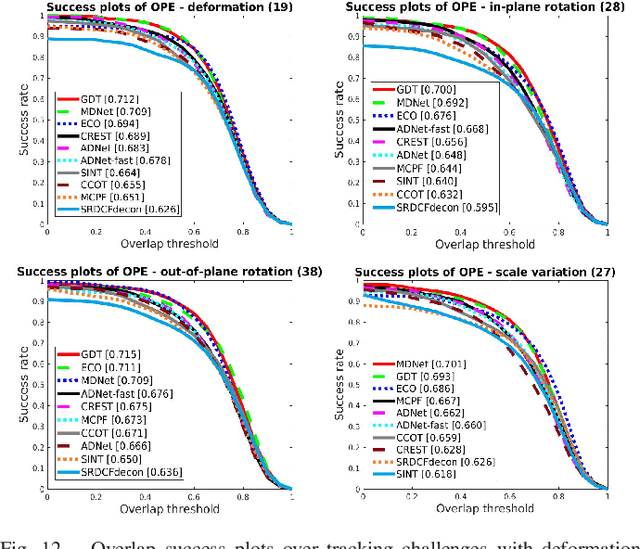
The tracking-by-detection framework receives growing attentions through the integration with the Convolutional Neural Network (CNN). Existing methods, however, fail to track objects with severe appearance variations. This is because the traditional convolutional operation is performed on fixed grids, and thus may not be able to find the correct response while the object is changing pose or under varying environmental conditions. In this paper, we propose a deformable convolution layer to enrich the target appearance representations in the tracking-by-detection framework. We aim to capture the target appearance variations via deformable convolution and supplement its original appearance through residual learning. Meanwhile, we propose a gated fusion scheme to control how the variations captured by the deformable convolution affect the original appearance. The enriched feature representation through deformable convolution facilitates the discrimination of the CNN classifier on the target object and background. Extensive experiments on the standard benchmarks show that the proposed tracker performs favorably against state-of-the-art methods.