 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Image Synthesis via Next-Token Prediction
Paper and Code

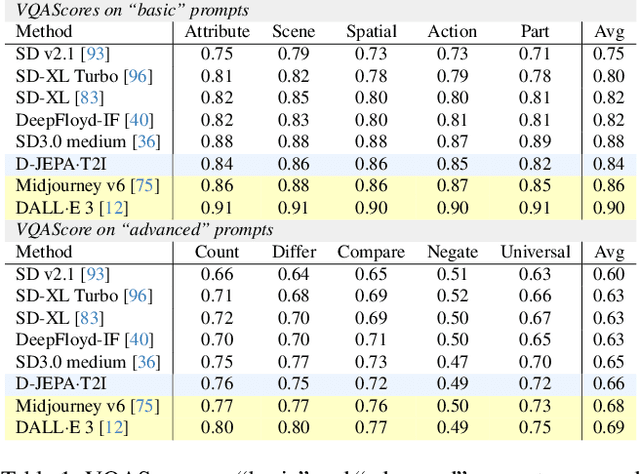

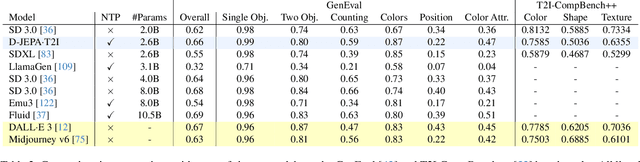
Denoising with a Joint-Embedding Predictive Architecture (D-JEPA), an autoregressive model, has demonstrated outstanding performance in class-conditional image generation. However, the application of next-token prediction in high-resolution text-to-image generation remains underexplored. In this paper, we introduce D-JEPA$\cdot$T2I, an extension of D-JEPA incorporating flow matching loss, designed to enable data-efficient continuous resolution learning. D-JEPA$\cdot$T2I leverages a multimodal visual transformer to effectively integrate textual and visual features and adopts Visual Rotary Positional Embedding (VoPE) to facilitate continuous resolution learning. Furthermore, we devise a data feedback mechanism that significantly enhances data utilization efficiency. For the first time, we achieve state-of-the-art \textbf{high-resolution} image synthesis via next-token prediction. The experimental code and pretrained models will be open-sourced at \url{https://d-jepa.github.io/t2i}.