 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
Dec 16, 2025The rapid scaling of Large Language Models (LLMs) has achieved remarkable performance, but it also leads to prohibitive memory costs. Existing parameter-efficient approaches such as pruning and quantization mainly compress pretrained models without enhancing architectural capacity, thereby hitting the representational ceiling of the base model. In this work, we propose VersatileFFN, a novel feed-forward network (FFN) that enables flexible reuse of parameters in both width and depth dimensions within a fixed parameter budget. Inspired by the dual-process theory of cognition, VersatileFFN comprises two adaptive pathways: a width-versatile path that generates a mixture of sub-experts from a single shared FFN, mimicking sparse expert routing without increasing parameters, and a depth-versatile path that recursively applies the same FFN to emulate deeper processing for complex tokens. A difficulty-aware gating dynamically balances the two pathways, steering "easy" tokens through the efficient width-wise route and allocating deeper iterative refinement to "hard" tokens. Crucially, both pathways reuse the same parameters, so all additional capacity comes from computation rather than memory. Experiments across diverse benchmarks and model scales demonstrate the effectiveness of the method. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/VersatileFFN.
Free Video-LLM: Prompt-guided Visual Perception for Efficient Training-free Video LLMs
Oct 14, 2024
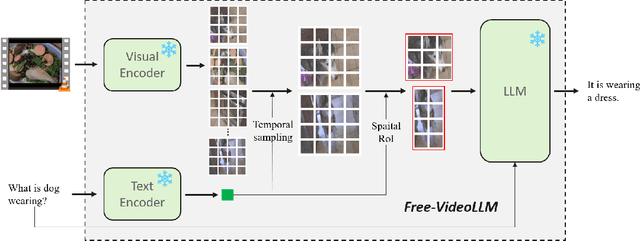

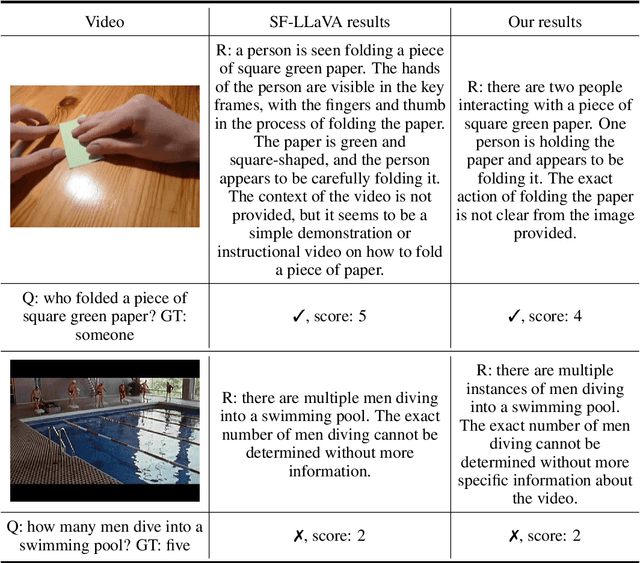
Vision-language large models have achieved remarkable success in various multi-modal tasks, yet applying them to video understanding remains challenging due to the inherent complexity and computational demands of video data. While training-based video-LLMs deliver high performance, they often require substantial resources for training and inference. Conversely, training-free approaches offer a more efficient alternative by adapting pre-trained image-LLMs models for video tasks without additional training, but they face inference efficiency bottlenecks due to the large number of visual tokens generated from video frames. In this work, we present a novel prompt-guided visual perception framework (abbreviated as \emph{Free Video-LLM}) for efficient inference of training-free video LLMs. The proposed framework decouples spatial-temporal dimension and performs temporal frame sampling and spatial RoI cropping respectively based on task-specific prompts. Our method effectively reduces the number of visual tokens while maintaining high performance across multiple video question-answering benchmarks. Extensive experiments demonstrate that our approach achieves competitive results with significantly fewer tokens, offering an optimal trade-off between accuracy and computational efficiency compared to state-of-the-art video LLMs. The code will be available at \url{https://github.com/contrastive/FreeVideoLLM}.
Denoising with a Joint-Embedding Predictive Architecture
Oct 02, 2024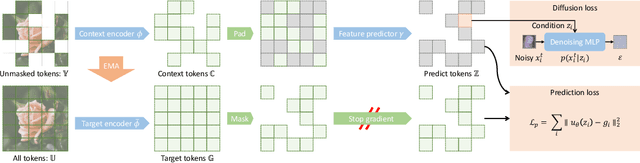
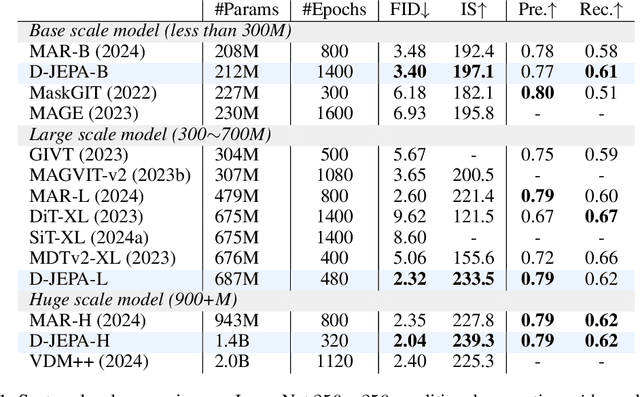
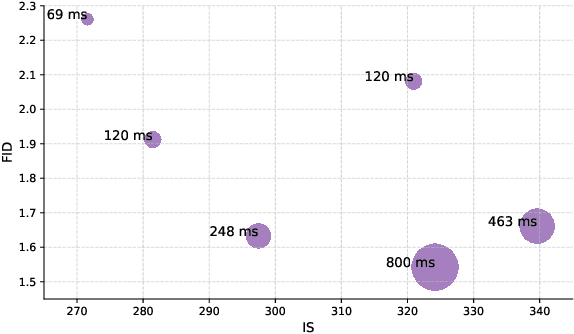
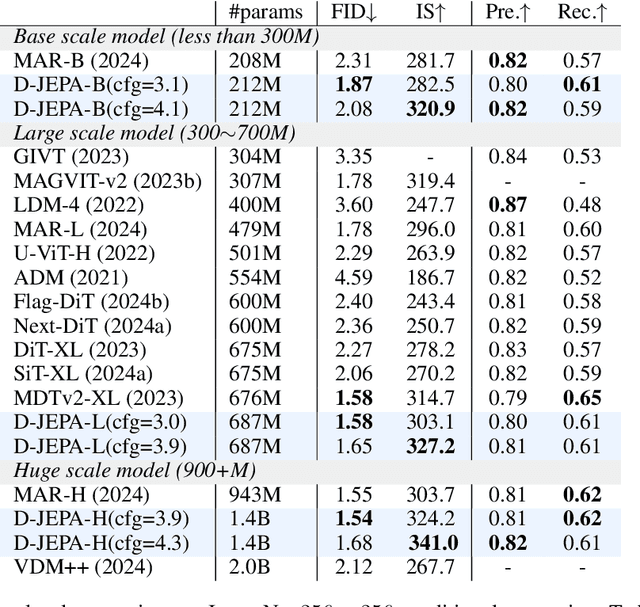
Joint-embedding predictive architectures (JEPAs) have shown substantial promise in self-supervised representation learning, yet their application in generative modeling remains underexplored. Conversely, diffusion models have demonstrated significant efficacy in modeling arbitrary probability distributions. In this paper, we introduce Denoising with a Joint-Embedding Predictive Architecture (D-JEPA), pioneering the integration of JEPA within generative modeling. By recognizing JEPA as a form of masked image modeling, we reinterpret it as a generalized next-token prediction strategy, facilitating data generation in an auto-regressive manner. Furthermore, we incorporate diffusion loss to model the per-token probability distribution, enabling data generation in a continuous space. We also adapt flow matching loss as an alternative to diffusion loss, thereby enhancing the flexibility of D-JEPA. Empirically, with increased GFLOPs, D-JEPA consistently achieves lower FID scores with fewer training epochs, indicating its good scalability. Our base, large, and huge models outperform all previous generative models across all scales on class-conditional ImageNet benchmarks. Beyond image generation, D-JEPA is well-suited for other continuous data modeling, including video and audio.
Kangaroo: A Powerful Video-Language Model Supporting Long-context Video Input
Aug 28, 2024



Rapid advancements have been made in extending Large Language Models (LLMs) to Large Multi-modal Models (LMMs). However, extending input modality of LLMs to video data remains a challenging endeavor, especially for long videos. Due to insufficient access to large-scale high-quality video data and the excessive compression of visual features, current methods exhibit limitations in effectively processing long videos. In this paper, we introduce Kangaroo, a powerful Video LMM aimed at addressing these challenges. Confronted with issue of inadequate training data, we develop a data curation system to build a large-scale dataset with high-quality annotations for vision-language pre-training and instruction tuning. In addition, we design a curriculum training pipeline with gradually increasing resolution and number of input frames to accommodate long videos. Evaluation results demonstrate that, with 8B parameters, Kangaroo achieves state-of-the-art performance across a variety of video understanding benchmarks while exhibiting competitive results on others. Particularly, on benchmarks specialized for long videos, Kangaroo excels some larger models with over 10B parameters and proprietary models.
Deformable 3D Shape Diffusion Model
Jul 31, 2024The Gaussian diffusion model, initially designed for image generation, has recently been adapted for 3D point cloud generation. However, these adaptations have not fully considered the intrinsic geometric characteristics of 3D shapes, thereby constraining the diffusion model's potential for 3D shape manipulation. To address this limitation, we introduce a novel deformable 3D shape diffusion model that facilitates comprehensive 3D shape manipulation, including point cloud generation, mesh deformation, and facial animation. Our approach innovatively incorporates a differential deformation kernel, which deconstructs the generation of geometric structures into successive non-rigid deformation stages. By leveraging a probabilistic diffusion model to simulate this step-by-step process, our method provides a versatile and efficient solution for a wide range of applications, spanning from graphics rendering to facial expression animation. Empirical evidence highlights the effectiveness of our approach, demonstrating state-of-the-art performance in point cloud generation and competitive results in mesh deformation. Additionally, extensive visual demonstrations reveal the significant potential of our approach for practical applications. Our method presents a unique pathway for advancing 3D shape manipulation and unlocking new opportunities in the realm of virtual reality.
Fine-gained Zero-shot Video Sampling
Jul 31, 2024



Incorporating a temporal dimension into pretrained image diffusion models for video generation is a prevalent approach. However, this method is computationally demanding and necessitates large-scale video datasets. More critically, the heterogeneity between image and video datasets often results in catastrophic forgetting of the image expertise. Recent attempts to directly extract video snippets from image diffusion models have somewhat mitigated these problems. Nevertheless, these methods can only generate brief video clips with simple movements and fail to capture fine-grained motion or non-grid deformation. In this paper, we propose a novel Zero-Shot video Sampling algorithm, denoted as $\mathcal{ZS}^2$, capable of directly sampling high-quality video clips from existing image synthesis methods, such as Stable Diffusion, without any training or optimization. Specifically, $\mathcal{ZS}^2$ utilizes the dependency noise model and temporal momentum attention to ensure content consistency and animation coherence, respectively. This ability enables it to excel in related tasks, such as conditional and context-specialized video generation and instruction-guided video editing. Experimental results demonstrate that $\mathcal{ZS}^2$ achieves state-of-the-art performance in zero-shot video generation, occasionally outperforming recent supervised methods. Homepage: \url{https://densechen.github.io/zss/}.
Space-time Reinforcement Network for Video Object Segmentation
May 07, 2024Recently, video object segmentation (VOS) networks typically use memory-based methods: for each query frame, the mask is predicted by space-time matching to memory frames. Despite these methods having superior performance, they suffer from two issues: 1) Challenging data can destroy the space-time coherence between adjacent video frames. 2) Pixel-level matching will lead to undesired mismatching caused by the noises or distractors. To address the aforementioned issues, we first propose to generate an auxiliary frame between adjacent frames, serving as an implicit short-temporal reference for the query one. Next, we learn a prototype for each video object and prototype-level matching can be implemented between the query and memory. The experiment demonstrated that our network outperforms the state-of-the-art method on the DAVIS 2017, achieving a J&F score of 86.4%, and attains a competitive result 85.0% on YouTube VOS 2018. In addition, our network exhibits a high inference speed of 32+ FPS.
ParameterNet: Parameters Are All You Need for Large-scale Visual Pretraining of Mobile Networks
Jun 26, 2023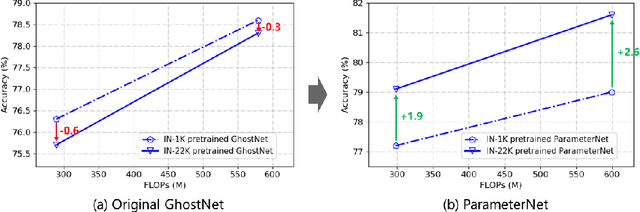
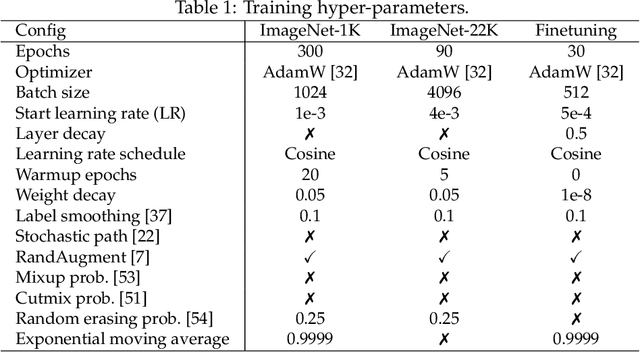
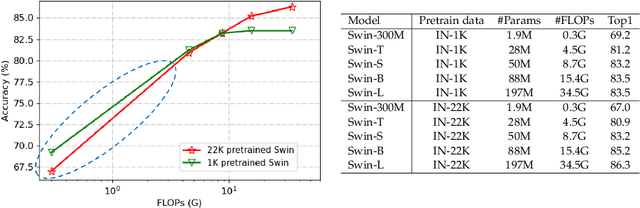
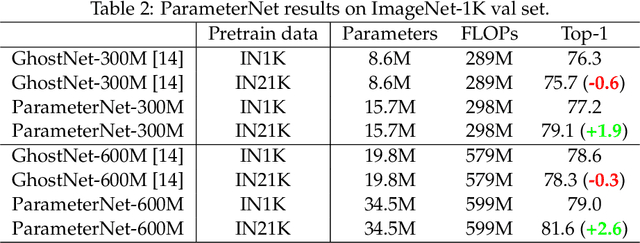
The large-scale visual pretraining has significantly improve the performance of large vision models. However, we observe the \emph{low FLOPs pitfall} that the existing low-FLOPs models cannot benefit from large-scale pretraining. In this paper, we propose a general design principle of adding more parameters while maintaining low FLOPs for large-scale visual pretraining, named as ParameterNet. Dynamic convolutions are used for instance to equip the networks with more parameters and only slightly increase the FLOPs. The proposed ParameterNet scheme enables low-FLOPs networks to benefit from large-scale visual pretraining. Experiments on the large-scale ImageNet-22K have shown the superiority of our ParameterNet scheme. For example, ParameterNet-600M can achieve higher accuracy than the widely-used Swin Transformer (81.6\% \emph{vs.} 80.9\%) and has much lower FLOPs (0.6G \emph{vs.} 4.5G). The code will be released as soon (MindSpore: https://gitee.com/mindspore/models, PyTorch: https://github.com/huawei-noah/Efficient-AI-Backbones).
Robust and Efficient Memory Network for Video Object Segmentation
Apr 24, 2023This paper proposes a Robust and Efficient Memory Network, referred to as REMN, for studying semi-supervised video object segmentation (VOS). Memory-based methods have recently achieved outstanding VOS performance by performing non-local pixel-wise matching between the query and memory. However, these methods have two limitations. 1) Non-local matching could cause distractor objects in the background to be incorrectly segmented. 2) Memory features with high temporal redundancy consume significant computing resources. For limitation 1, we introduce a local attention mechanism that tackles the background distraction by enhancing the features of foreground objects with the previous mask. For limitation 2, we first adaptively decide whether to update the memory features depending on the variation of foreground objects to reduce temporal redundancy. Second, we employ a dynamic memory bank, which uses a lightweight and differentiable soft modulation gate to decide how many memory features need to be removed in the temporal dimension. Experiments demonstrate that our REMN achieves state-of-the-art results on DAVIS 2017, with a $\mathcal{J\&F}$ score of 86.3% and on YouTube-VOS 2018, with a $\mathcal{G}$ over mean of 85.5%. Furthermore, our network shows a high inference speed of 25+ FPS and uses relatively few computing resources.
Bag of Tricks with Quantized Convolutional Neural Networks for image classification
Mar 13, 2023



Deep neural networks have been proven effective in a wide range of tasks. However, their high computational and memory costs make them impractical to deploy on resource-constrained devices. To address this issue, quantization schemes have been proposed to reduce the memory footprint and improve inference speed. While numerous quantization methods have been proposed, they lack systematic analysis for their effectiveness. To bridge this gap, we collect and improve existing quantization methods and propose a gold guideline for post-training quantization. We evaluate the effectiveness of our proposed method with two popular models, ResNet50 and MobileNetV2, on the ImageNet dataset. By following our guidelines, no accuracy degradation occurs even after directly quantizing the model to 8-bits without additional training. A quantization-aware training based on the guidelines can further improve the accuracy in lower-bits quantization. Moreover, we have integrated a multi-stage fine-tuning strategy that works harmoniously with existing pruning techniques to reduce costs even further. Remarkably, our results reveal that a quantized MobileNetV2 with 30\% sparsity actually surpasses the performance of the equivalent full-precision model, underscoring the effectiveness and resilience of our proposed scheme.