 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSke2Grid: Skeleton-to-Grid Representation Learning for Action Recognition
Aug 15, 2023



This paper presents Ske2Grid, a new representation learning framework for improved skeleton-based action recognition. In Ske2Grid, we define a regular convolution operation upon a novel grid representation of human skeleton, which is a compact image-like grid patch constructed and learned through three novel designs. Specifically, we propose a graph-node index transform (GIT) to construct a regular grid patch through assigning the nodes in the skeleton graph one by one to the desired grid cells. To ensure that GIT is a bijection and enrich the expressiveness of the grid representation, an up-sampling transform (UPT) is learned to interpolate the skeleton graph nodes for filling the grid patch to the full. To resolve the problem when the one-step UPT is aggressive and further exploit the representation capability of the grid patch with increasing spatial size, a progressive learning strategy (PLS) is proposed which decouples the UPT into multiple steps and aligns them to multiple paired GITs through a compact cascaded design learned progressively. We construct networks upon prevailing graph convolution networks and conduct experiments on six mainstream skeleton-based action recognition datasets. Experiments show that our Ske2Grid significantly outperforms existing GCN-based solutions under different benchmark settings, without bells and whistles. Code and models are available at https://github.com/OSVAI/Ske2Grid
Hierarchical and Contrastive Representation Learning for Knowledge-aware Recommendation
Apr 15, 2023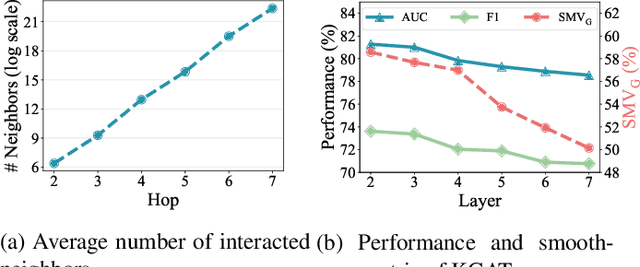
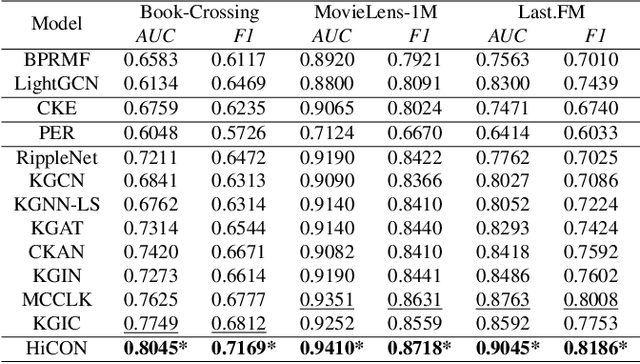
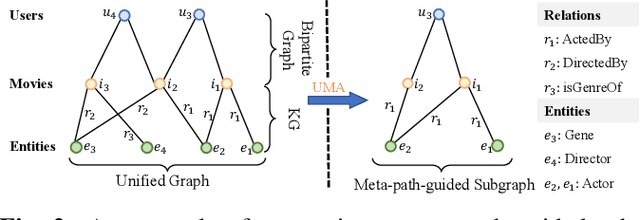

Incorporating knowledge graph into recommendation is an effective way to alleviate data sparsity. Most existing knowledge-aware methods usually perform recursive embedding propagation by enumerating graph neighbors. However, the number of nodes' neighbors grows exponentially as the hop number increases, forcing the nodes to be aware of vast neighbors under this recursive propagation for distilling the high-order semantic relatedness. This may induce more harmful noise than useful information into recommendation, leading the learned node representations to be indistinguishable from each other, that is, the well-known over-smoothing issue. To relieve this issue, we propose a Hierarchical and CONtrastive representation learning framework for knowledge-aware recommendation named HiCON. Specifically, for avoiding the exponential expansion of neighbors, we propose a hierarchical message aggregation mechanism to interact separately with low-order neighbors and meta-path-constrained high-order neighbors. Moreover, we also perform cross-order contrastive learning to enforce the representations to be more discriminative. Extensive experiments on three datasets show the remarkable superiority of HiCON over state-of-the-art approaches.
3D Human Pose Lifting with Grid Convolution
Feb 17, 2023Existing lifting networks for regressing 3D human poses from 2D single-view poses are typically constructed with linear layers based on graph-structured representation learning. In sharp contrast to them, this paper presents Grid Convolution (GridConv), mimicking the wisdom of regular convolution operations in image space. GridConv is based on a novel Semantic Grid Transformation (SGT) which leverages a binary assignment matrix to map the irregular graph-structured human pose onto a regular weave-like grid pose representation joint by joint, enabling layer-wise feature learning with GridConv operations. We provide two ways to implement SGT, including handcrafted and learnable designs. Surprisingly, both designs turn out to achieve promising results and the learnable one is better, demonstrating the great potential of this new lifting representation learning formulation. To improve the ability of GridConv to encode contextual cues, we introduce an attention module over the convolutional kernel, making grid convolution operations input-dependent, spatial-aware and grid-specific. We show that our fully convolutional grid lifting network outperforms state-of-the-art methods with noticeable margins under (1) conventional evaluation on Human3.6M and (2) cross-evaluation on MPI-INF-3DHP. Code is available at https://github.com/OSVAI/GridConv