 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibeating Made Simple
Mar 23, 2026We study calibeating, the problem of post-processing external forecasts online to minimize cumulative losses and match an informativeness-based benchmark. Unlike prior work, which analyzed calibeating for specific losses with specific arguments, we reduce calibeating to existing online learning techniques and obtain results for general proper losses. More concretely, we first show that calibeating is minimax-equivalent to regret minimization. This recovers the $O(\log T)$ calibeating rate of Foster and Hart [FH23] for the Brier and log losses and its optimality, and yields new optimal calibeating rates for mixable losses and general bounded losses. Second, we prove that multi-calibeating is minimax-equivalent to the combination of calibeating and the classical expert problem. This yields new optimal multi-calibeating rates for mixable losses, including Brier and log losses, and general bounded losses. Finally, we obtain new bounds for achieving calibeating and calibration simultaneously for the Brier loss. For binary predictions, our result gives the first calibrated algorithm that at the same time also achieves the optimal $O(\log T)$ calibeating rate.
How Sampling Shapes LLM Alignment: From One-Shot Optima to Iterative Dynamics
Feb 12, 2026Standard methods for aligning large language models with human preferences learn from pairwise comparisons among sampled candidate responses and regularize toward a reference policy. Despite their effectiveness, the effects of sampling and reference choices are poorly understood theoretically. We investigate these effects through Identity Preference Optimization, a widely used preference alignment framework, and show that proper instance-dependent sampling can yield stronger ranking guarantees, while skewed on-policy sampling can induce excessive concentration under structured preferences. We then analyze iterative alignment dynamics in which the learned policy feeds back into future sampling and reference policies, reflecting a common practice of model-generated preference data. We prove that these dynamics can exhibit persistent oscillations or entropy collapse for certain parameter choices, and characterize regimes that guarantee stability. Our theoretical insights extend to Direct Preference Optimization, indicating the phenomena we captured are common to a broader class of preference-alignment methods. Experiments on real-world preference data validate our findings.
Are Bounded Contracts Learnable and Approximately Optimal?
Feb 22, 2024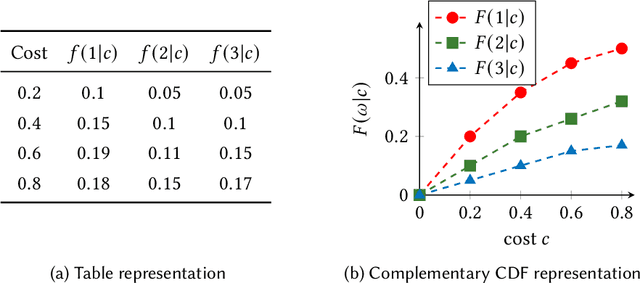

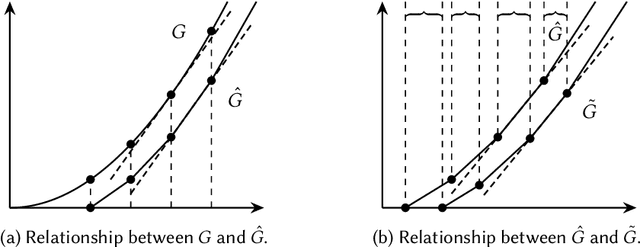
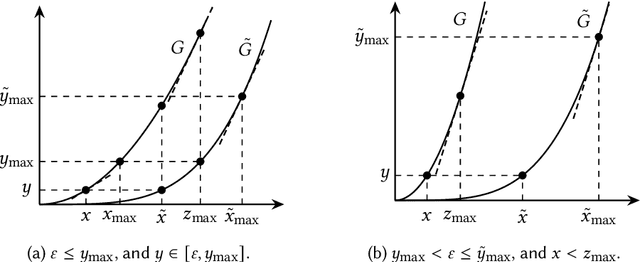
This paper considers the hidden-action model of the principal-agent problem, in which a principal incentivizes an agent to work on a project using a contract. We investigate whether contracts with bounded payments are learnable and approximately optimal. Our main results are two learning algorithms that can find a nearly optimal bounded contract using a polynomial number of queries, under two standard assumptions in the literature: a costlier action for the agent leads to a better outcome distribution for the principal, and the agent's cost/effort has diminishing returns. Our polynomial query complexity upper bound shows that standard assumptions are sufficient for achieving an exponential improvement upon the known lower bound for general instances. Unlike the existing algorithms, which relied on discretizing the contract space, our algorithms directly learn the underlying outcome distributions. As for the approximate optimality of bounded contracts, we find that they could be far from optimal in terms of multiplicative or additive approximation, but satisfy a notion of mixed approximation.
Ske2Grid: Skeleton-to-Grid Representation Learning for Action Recognition
Aug 15, 2023



This paper presents Ske2Grid, a new representation learning framework for improved skeleton-based action recognition. In Ske2Grid, we define a regular convolution operation upon a novel grid representation of human skeleton, which is a compact image-like grid patch constructed and learned through three novel designs. Specifically, we propose a graph-node index transform (GIT) to construct a regular grid patch through assigning the nodes in the skeleton graph one by one to the desired grid cells. To ensure that GIT is a bijection and enrich the expressiveness of the grid representation, an up-sampling transform (UPT) is learned to interpolate the skeleton graph nodes for filling the grid patch to the full. To resolve the problem when the one-step UPT is aggressive and further exploit the representation capability of the grid patch with increasing spatial size, a progressive learning strategy (PLS) is proposed which decouples the UPT into multiple steps and aligns them to multiple paired GITs through a compact cascaded design learned progressively. We construct networks upon prevailing graph convolution networks and conduct experiments on six mainstream skeleton-based action recognition datasets. Experiments show that our Ske2Grid significantly outperforms existing GCN-based solutions under different benchmark settings, without bells and whistles. Code and models are available at https://github.com/OSVAI/Ske2Grid
ECT: Fine-grained Edge Detection with Learned Cause Tokens
Aug 06, 2023In this study, we tackle the challenging fine-grained edge detection task, which refers to predicting specific edges caused by reflectance, illumination, normal, and depth changes, respectively. Prior methods exploit multi-scale convolutional networks, which are limited in three aspects: (1) Convolutions are local operators while identifying the cause of edge formation requires looking at far away pixels. (2) Priors specific to edge cause are fixed in prediction heads. (3) Using separate networks for generic and fine-grained edge detection, and the constraint between them may be violated. To address these three issues, we propose a two-stage transformer-based network sequentially predicting generic edges and fine-grained edges, which has a global receptive field thanks to the attention mechanism. The prior knowledge of edge causes is formulated as four learnable cause tokens in a cause-aware decoder design. Furthermore, to encourage the consistency between generic edges and fine-grained edges, an edge aggregation and alignment loss is exploited. We evaluate our method on the public benchmark BSDS-RIND and several newly derived benchmarks, and achieve new state-of-the-art results. Our code, data, and models are publicly available at https://github.com/Daniellli/ECT.git.
Coordinated Dynamic Bidding in Repeated Second-Price Auctions with Budgets
Jun 13, 2023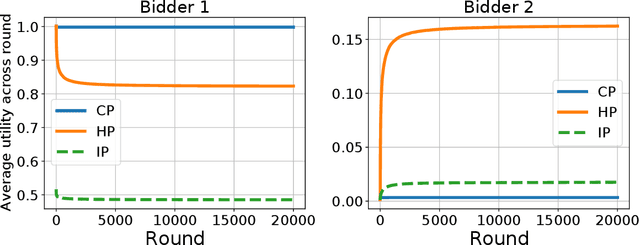
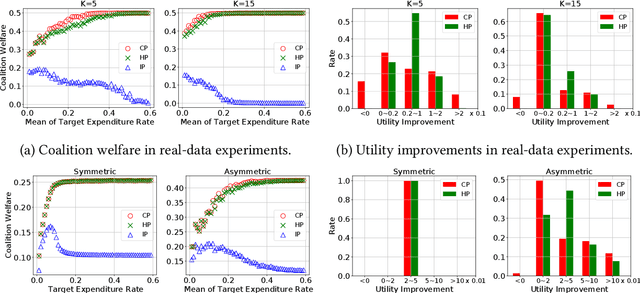
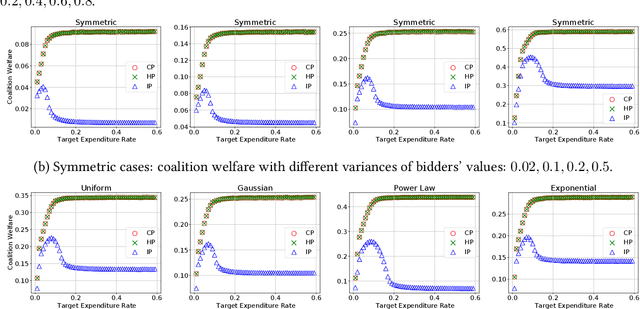
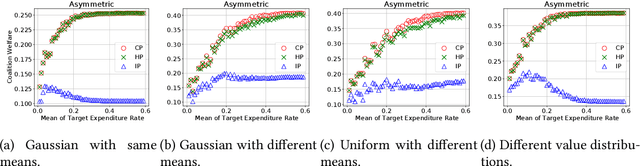
In online ad markets, a rising number of advertisers are employing bidding agencies to participate in ad auctions. These agencies are specialized in designing online algorithms and bidding on behalf of their clients. Typically, an agency usually has information on multiple advertisers, so she can potentially coordinate bids to help her clients achieve higher utilities than those under independent bidding. In this paper, we study coordinated online bidding algorithms in repeated second-price auctions with budgets. We propose algorithms that guarantee every client a higher utility than the best she can get under independent bidding. We show that these algorithms achieve maximal coalition welfare and discuss bidders' incentives to misreport their budgets, in symmetric cases. Our proofs combine the techniques of online learning and equilibrium analysis, overcoming the difficulty of competing with a multi-dimensional benchmark. The performance of our algorithms is further evaluated by experiments on both synthetic and real data. To the best of our knowledge, we are the first to consider bidder coordination in online repeated auctions with constraints.
A Scalable Neural Network for DSIC Affine Maximizer Auction Design
May 20, 2023


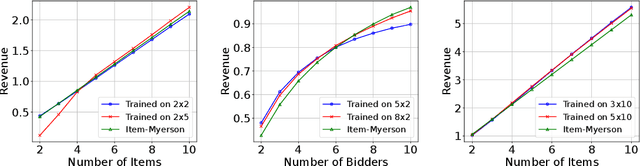
Automated auction design aims to find empirically high-revenue mechanisms through machine learning. Existing works on multi item auction scenarios can be roughly divided into RegretNet-like and affine maximizer auctions (AMAs) approaches. However, the former cannot strictly ensure dominant strategy incentive compatibility (DSIC), while the latter faces scalability issue due to the large number of allocation candidates. To address these limitations, we propose AMenuNet, a scalable neural network that constructs the AMA parameters (even including the allocation menu) from bidder and item representations. AMenuNet is always DSIC and individually rational (IR) due to the properties of AMAs, and it enhances scalability by generating candidate allocations through a neural network. Additionally, AMenuNet is permutation equivariant, and its number of parameters is independent of auction scale. We conduct extensive experiments to demonstrate that AMenuNet outperforms strong baselines in both contextual and non-contextual multi-item auctions, scales well to larger auctions, generalizes well to different settings, and identifies useful deterministic allocations. Overall, our proposed approach offers an effective solution to automated DSIC auction design, with improved scalability and strong revenue performance in various settings.
CABM: Content-Aware Bit Mapping for Single Image Super-Resolution Network with Large Input
Apr 13, 2023

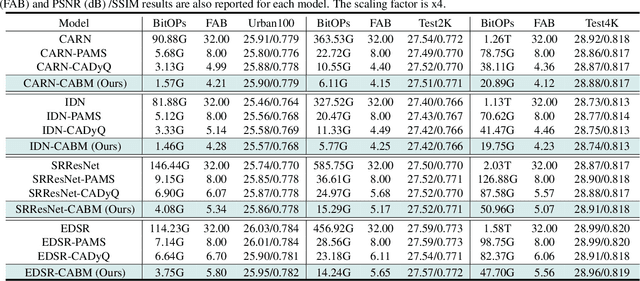
With the development of high-definition display devices, the practical scenario of Super-Resolution (SR) usually needs to super-resolve large input like 2K to higher resolution (4K/8K). To reduce the computational and memory cost, current methods first split the large input into local patches and then merge the SR patches into the output. These methods adaptively allocate a subnet for each patch. Quantization is a very important technique for network acceleration and has been used to design the subnets. Current methods train an MLP bit selector to determine the propoer bit for each layer. However, they uniformly sample subnets for training, making simple subnets overfitted and complicated subnets underfitted. Therefore, the trained bit selector fails to determine the optimal bit. Apart from this, the introduced bit selector brings additional cost to each layer of the SR network. In this paper, we propose a novel method named Content-Aware Bit Mapping (CABM), which can remove the bit selector without any performance loss. CABM also learns a bit selector for each layer during training. After training, we analyze the relation between the edge information of an input patch and the bit of each layer. We observe that the edge information can be an effective metric for the selected bit. Therefore, we design a strategy to build an Edge-to-Bit lookup table that maps the edge score of a patch to the bit of each layer during inference. The bit configuration of SR network can be determined by the lookup tables of all layers. Our strategy can find better bit configuration, resulting in more efficient mixed precision networks. We conduct detailed experiments to demonstrate the generalization ability of our method. The code will be released.
Learning to Manipulate a Commitment Optimizer
Feb 26, 2023
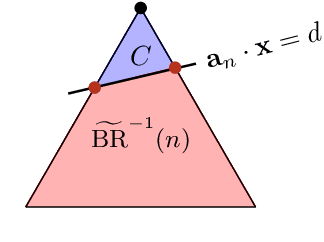

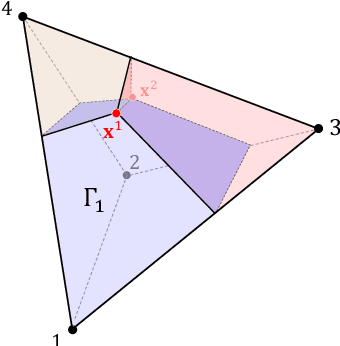
It is shown in recent studies that in a Stackelberg game the follower can manipulate the leader by deviating from their true best-response behavior. Such manipulations are computationally tractable and can be highly beneficial for the follower. Meanwhile, they may result in significant payoff losses for the leader, sometimes completely defeating their first-mover advantage. A warning to commitment optimizers, the risk these findings indicate appears to be alleviated to some extent by a strict information advantage the manipulations rely on. That is, the follower knows the full information about both players' payoffs whereas the leader only knows their own payoffs. In this paper, we study the manipulation problem with this information advantage relaxed. We consider the scenario where the follower is not given any information about the leader's payoffs to begin with but has to learn to manipulate by interacting with the leader. The follower can gather necessary information by querying the leader's optimal commitments against contrived best-response behaviors. Our results indicate that the information advantage is not entirely indispensable to the follower's manipulations: the follower can learn the optimal way to manipulate in polynomial time with polynomially many queries of the leader's optimal commitment.
From Semi-supervised to Omni-supervised Room Layout Estimation Using Point Clouds
Jan 31, 2023Room layout estimation is a long-existing robotic vision task that benefits both environment sensing and motion planning. However, layout estimation using point clouds (PCs) still suffers from data scarcity due to annotation difficulty. As such, we address the semi-supervised setting of this task based upon the idea of model exponential moving averaging. But adapting this scheme to the state-of-the-art (SOTA) solution for PC-based layout estimation is not straightforward. To this end, we define a quad set matching strategy and several consistency losses based upon metrics tailored for layout quads. Besides, we propose a new online pseudo-label harvesting algorithm that decomposes the distribution of a hybrid distance measure between quads and PC into two components. This technique does not need manual threshold selection and intuitively encourages quads to align with reliable layout points. Surprisingly, this framework also works for the fully-supervised setting, achieving a new SOTA on the ScanNet benchmark. Last but not least, we also push the semi-supervised setting to the realistic omni-supervised setting, demonstrating significantly promoted performance on a newly annotated ARKitScenes testing set. Our codes, data and models are released in this repository.