 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative and Compact Structured Latents for 3D Generation
Dec 16, 2025Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
InvRGB+L: Inverse Rendering of Complex Scenes with Unified Color and LiDAR Reflectance Modeling
Jul 23, 2025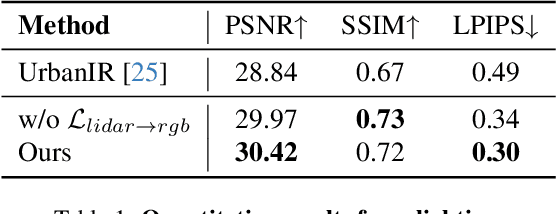

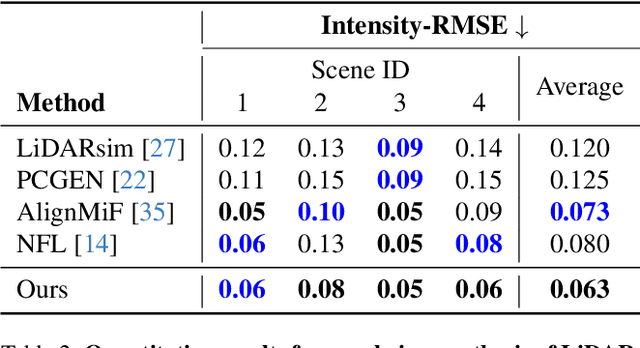
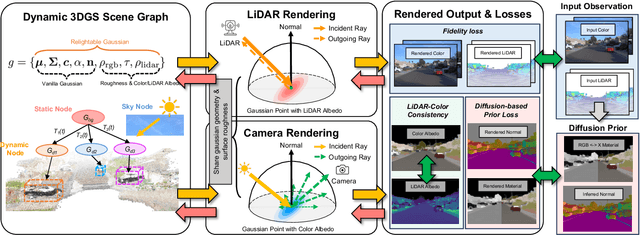
We present InvRGB+L, a novel inverse rendering model that reconstructs large, relightable, and dynamic scenes from a single RGB+LiDAR sequence. Conventional inverse graphics methods rely primarily on RGB observations and use LiDAR mainly for geometric information, often resulting in suboptimal material estimates due to visible light interference. We find that LiDAR's intensity values-captured with active illumination in a different spectral range-offer complementary cues for robust material estimation under variable lighting. Inspired by this, InvRGB+L leverages LiDAR intensity cues to overcome challenges inherent in RGB-centric inverse graphics through two key innovations: (1) a novel physics-based LiDAR shading model and (2) RGB-LiDAR material consistency losses. The model produces novel-view RGB and LiDAR renderings of urban and indoor scenes and supports relighting, night simulations, and dynamic object insertions, achieving results that surpass current state-of-the-art methods in both scene-level urban inverse rendering and LiDAR simulation.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Locate n' Rotate: Two-stage Openable Part Detection with Foundation Model Priors
Dec 17, 2024Detecting the openable parts of articulated objects is crucial for downstream applications in intelligent robotics, such as pulling a drawer. This task poses a multitasking challenge due to the necessity of understanding object categories and motion. Most existing methods are either category-specific or trained on specific datasets, lacking generalization to unseen environments and objects. In this paper, we propose a Transformer-based Openable Part Detection (OPD) framework named Multi-feature Openable Part Detection (MOPD) that incorporates perceptual grouping and geometric priors, outperforming previous methods in performance. In the first stage of the framework, we introduce a perceptual grouping feature model that provides perceptual grouping feature priors for openable part detection, enhancing detection results through a cross-attention mechanism. In the second stage, a geometric understanding feature model offers geometric feature priors for predicting motion parameters. Compared to existing methods, our proposed approach shows better performance in both detection and motion parameter prediction. Codes and models are publicly available at https://github.com/lisiqi-zju/MOPD
RGM: Reconstructing High-fidelity 3D Car Assets with Relightable 3D-GS Generative Model from a Single Image
Oct 10, 2024



The generation of high-quality 3D car assets is essential for various applications, including video games, autonomous driving, and virtual reality. Current 3D generation methods utilizing NeRF or 3D-GS as representations for 3D objects, generate a Lambertian object under fixed lighting and lack separated modelings for material and global illumination. As a result, the generated assets are unsuitable for relighting under varying lighting conditions, limiting their applicability in downstream tasks. To address this challenge, we propose a novel relightable 3D object generative framework that automates the creation of 3D car assets, enabling the swift and accurate reconstruction of a vehicle's geometry, texture, and material properties from a single input image. Our approach begins with introducing a large-scale synthetic car dataset comprising over 1,000 high-precision 3D vehicle models. We represent 3D objects using global illumination and relightable 3D Gaussian primitives integrating with BRDF parameters. Building on this representation, we introduce a feed-forward model that takes images as input and outputs both relightable 3D Gaussians and global illumination parameters. Experimental results demonstrate that our method produces photorealistic 3D car assets that can be seamlessly integrated into road scenes with different illuminations, which offers substantial practical benefits for industrial applications.
Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty
Aug 27, 2024
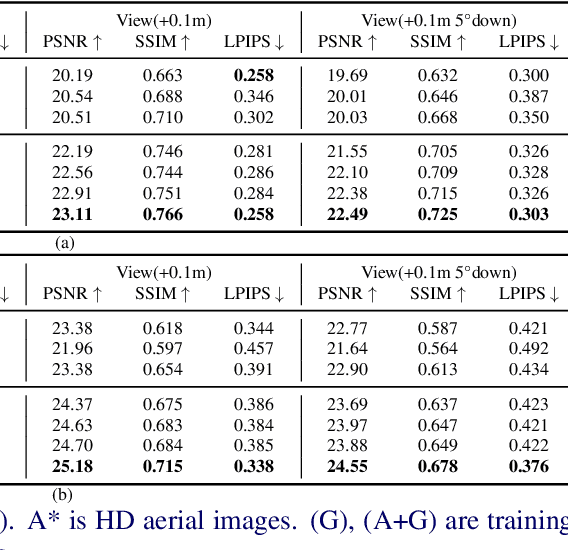
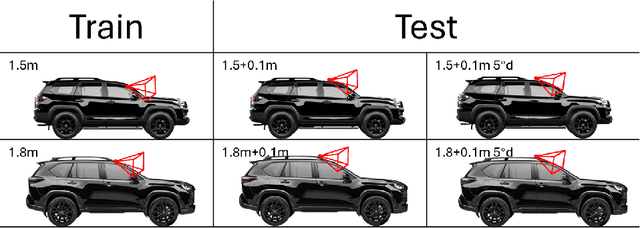
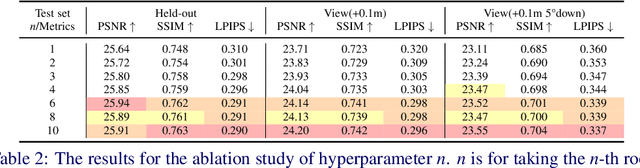
Robust and realistic rendering for large-scale road scenes is essential in autonomous driving simulation. Recently, 3D Gaussian Splatting (3D-GS) has made groundbreaking progress in neural rendering, but the general fidelity of large-scale road scene renderings is often limited by the input imagery, which usually has a narrow field of view and focuses mainly on the street-level local area. Intuitively, the data from the drone's perspective can provide a complementary viewpoint for the data from the ground vehicle's perspective, enhancing the completeness of scene reconstruction and rendering. However, training naively with aerial and ground images, which exhibit large view disparity, poses a significant convergence challenge for 3D-GS, and does not demonstrate remarkable improvements in performance on road views. In order to enhance the novel view synthesis of road views and to effectively use the aerial information, we design an uncertainty-aware training method that allows aerial images to assist in the synthesis of areas where ground images have poor learning outcomes instead of weighting all pixels equally in 3D-GS training like prior work did. We are the first to introduce the cross-view uncertainty to 3D-GS by matching the car-view ensemble-based rendering uncertainty to aerial images, weighting the contribution of each pixel to the training process. Additionally, to systematically quantify evaluation metrics, we assemble a high-quality synthesized dataset comprising both aerial and ground images for road scenes.
Rip-NeRF: Anti-aliasing Radiance Fields with Ripmap-Encoded Platonic Solids
May 03, 2024



Despite significant advancements in Neural Radiance Fields (NeRFs), the renderings may still suffer from aliasing and blurring artifacts, since it remains a fundamental challenge to effectively and efficiently characterize anisotropic areas induced by the cone-casting procedure. This paper introduces a Ripmap-Encoded Platonic Solid representation to precisely and efficiently featurize 3D anisotropic areas, achieving high-fidelity anti-aliasing renderings. Central to our approach are two key components: Platonic Solid Projection and Ripmap encoding. The Platonic Solid Projection factorizes the 3D space onto the unparalleled faces of a certain Platonic solid, such that the anisotropic 3D areas can be projected onto planes with distinguishable characterization. Meanwhile, each face of the Platonic solid is encoded by the Ripmap encoding, which is constructed by anisotropically pre-filtering a learnable feature grid, to enable featurzing the projected anisotropic areas both precisely and efficiently by the anisotropic area-sampling. Extensive experiments on both well-established synthetic datasets and a newly captured real-world dataset demonstrate that our Rip-NeRF attains state-of-the-art rendering quality, particularly excelling in the fine details of repetitive structures and textures, while maintaining relatively swift training times.
Spectrally Pruned Gaussian Fields with Neural Compensation
May 01, 2024Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mar 18, 2024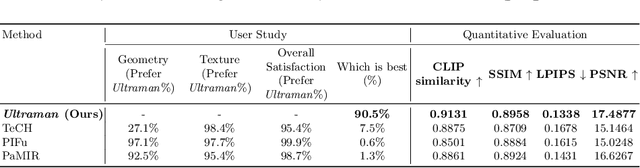
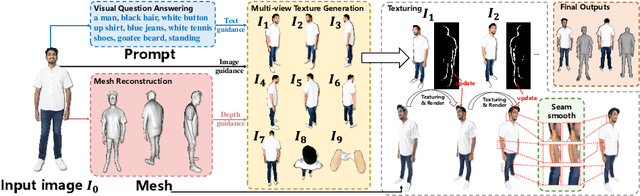
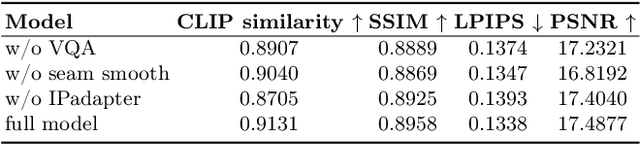
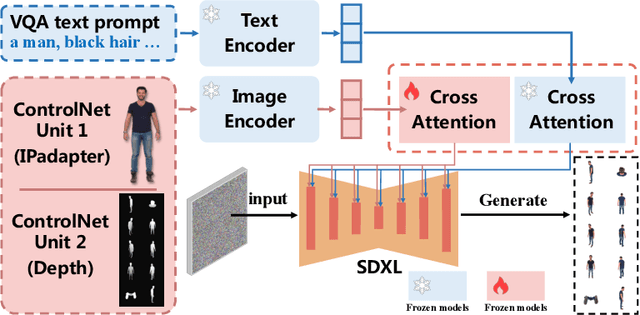
3D human body reconstruction has been a challenge in the field of computer vision. Previous methods are often time-consuming and difficult to capture the detailed appearance of the human body. In this paper, we propose a new method called \emph{Ultraman} for fast reconstruction of textured 3D human models from a single image. Compared to existing techniques, \emph{Ultraman} greatly improves the reconstruction speed and accuracy while preserving high-quality texture details. We present a set of new frameworks for human reconstruction consisting of three parts, geometric reconstruction, texture generation and texture mapping. Firstly, a mesh reconstruction framework is used, which accurately extracts 3D human shapes from a single image. At the same time, we propose a method to generate a multi-view consistent image of the human body based on a single image. This is finally combined with a novel texture mapping method to optimize texture details and ensure color consistency during reconstruction. Through extensive experiments and evaluations, we demonstrate the superior performance of \emph{Ultraman} on various standard datasets. In addition, \emph{Ultraman} outperforms state-of-the-art methods in terms of human rendering quality and speed. Upon acceptance of the article, we will make the code and data publicly available.
NeRRF: 3D Reconstruction and View Synthesis for Transparent and Specular Objects with Neural Refractive-Reflective Fields
Sep 22, 2023



Neural radiance fields (NeRF) have revolutionized the field of image-based view synthesis. However, NeRF uses straight rays and fails to deal with complicated light path changes caused by refraction and reflection. This prevents NeRF from successfully synthesizing transparent or specular objects, which are ubiquitous in real-world robotics and A/VR applications. In this paper, we introduce the refractive-reflective field. Taking the object silhouette as input, we first utilize marching tetrahedra with a progressive encoding to reconstruct the geometry of non-Lambertian objects and then model refraction and reflection effects of the object in a unified framework using Fresnel terms. Meanwhile, to achieve efficient and effective anti-aliasing, we propose a virtual cone supersampling technique. We benchmark our method on different shapes, backgrounds and Fresnel terms on both real-world and synthetic datasets. We also qualitatively and quantitatively benchmark the rendering results of various editing applications, including material editing, object replacement/insertion, and environment illumination estimation. Codes and data are publicly available at https://github.com/dawning77/NeRRF.