 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Future Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Dec 09, 2025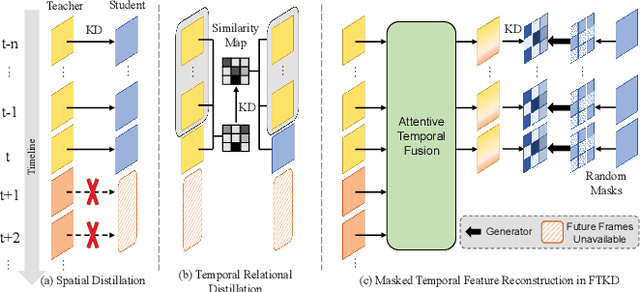
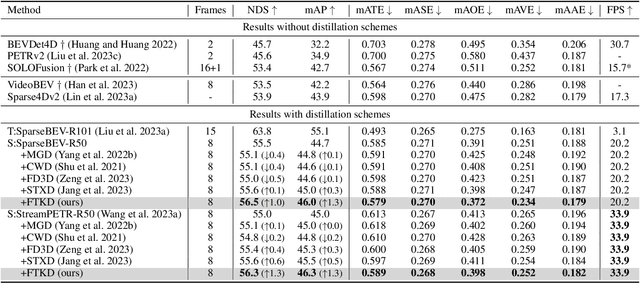
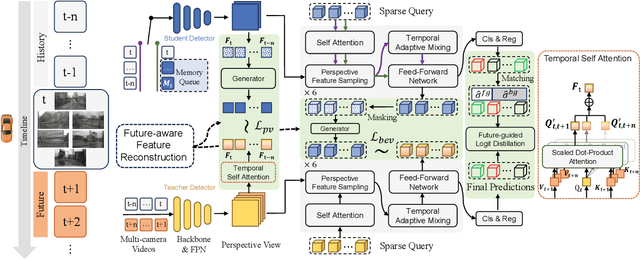
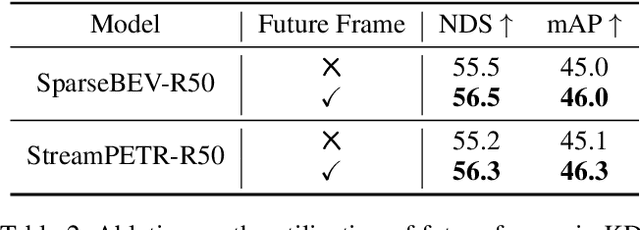
Camera-based temporal 3D object detection has shown impressive results in autonomous driving, with offline models improving accuracy by using future frames. Knowledge distillation (KD) can be an appealing framework for transferring rich information from offline models to online models. However, existing KD methods overlook future frames, as they mainly focus on spatial feature distillation under strict frame alignment or on temporal relational distillation, thereby making it challenging for online models to effectively learn future knowledge. To this end, we propose a sparse query-based approach, Future Temporal Knowledge Distillation (FTKD), which effectively transfers future frame knowledge from an offline teacher model to an online student model. Specifically, we present a future-aware feature reconstruction strategy to encourage the student model to capture future features without strict frame alignment. In addition, we further introduce future-guided logit distillation to leverage the teacher's stable foreground and background context. FTKD is applied to two high-performing 3D object detection baselines, achieving up to 1.3 mAP and 1.3 NDS gains on the nuScenes dataset, as well as the most accurate velocity estimation, without increasing inference cost.
HMVLM: Multistage Reasoning-Enhanced Vision-Language Model for Long-Tailed Driving Scenarios
Jun 06, 2025We present HaoMo Vision-Language Model (HMVLM), an end-to-end driving framework that implements the slow branch of a cognitively inspired fast-slow architecture. A fast controller outputs low-level steering, throttle, and brake commands, while a slow planner-a large vision-language model-generates high-level intents such as "yield to pedestrian" or "merge after the truck" without compromising latency. HMVLM introduces three upgrades: (1) selective five-view prompting with an embedded 4s history of ego kinematics, (2) multi-stage chain-of-thought (CoT) prompting that enforces a Scene Understanding -> Driving Decision -> Trajectory Inference reasoning flow, and (3) spline-based trajectory post-processing that removes late-stage jitter and sharp turns. Trained on the Waymo Open Dataset, these upgrades enable HMVLM to achieve a Rater Feedback Score (RFS) of 7.7367, securing 2nd place in the 2025 Waymo Vision-based End-to-End (E2E) Driving Challenge and surpassing the public baseline by 2.77%.
HMAD: Advancing E2E Driving with Anchored Offset Proposals and Simulation-Supervised Multi-target Scoring
May 29, 2025End-to-end autonomous driving faces persistent challenges in both generating diverse, rule-compliant trajectories and robustly selecting the optimal path from these options via learned, multi-faceted evaluation. To address these challenges, we introduce HMAD, a framework integrating a distinctive Bird's-Eye-View (BEV) based trajectory proposal mechanism with learned multi-criteria scoring. HMAD leverages BEVFormer and employs learnable anchored queries, initialized from a trajectory dictionary and refined via iterative offset decoding (inspired by DiffusionDrive), to produce numerous diverse and stable candidate trajectories. A key innovation, our simulation-supervised scorer module, then evaluates these proposals against critical metrics including no at-fault collisions, drivable area compliance, comfortableness, and overall driving quality (i.e., extended PDM score). Demonstrating its efficacy, HMAD achieves a 44.5% driving score on the CVPR 2025 private test set. This work highlights the benefits of effectively decoupling robust trajectory generation from comprehensive, safety-aware learned scoring for advanced autonomous driving.
CogAD: Cognitive-Hierarchy Guided End-to-End Autonomous Driving
May 27, 2025While end-to-end autonomous driving has advanced significantly, prevailing methods remain fundamentally misaligned with human cognitive principles in both perception and planning. In this paper, we propose CogAD, a novel end-to-end autonomous driving model that emulates the hierarchical cognition mechanisms of human drivers. CogAD implements dual hierarchical mechanisms: global-to-local context processing for human-like perception and intent-conditioned multi-mode trajectory generation for cognitively-inspired planning. The proposed method demonstrates three principal advantages: comprehensive environmental understanding through hierarchical perception, robust planning exploration enabled by multi-level planning, and diverse yet reasonable multi-modal trajectory generation facilitated by dual-level uncertainty modeling. Extensive experiments on nuScenes and Bench2Drive demonstrate that CogAD achieves state-of-the-art performance in end-to-end planning, exhibiting particular superiority in long-tail scenarios and robust generalization to complex real-world driving conditions.
Diffusion-Based Planning for Autonomous Driving with Flexible Guidance
Jan 26, 2025



Achieving human-like driving behaviors in complex open-world environments is a critical challenge in autonomous driving. Contemporary learning-based planning approaches such as imitation learning methods often struggle to balance competing objectives and lack of safety assurance,due to limited adaptability and inadequacy in learning complex multi-modal behaviors commonly exhibited in human planning, not to mention their strong reliance on the fallback strategy with predefined rules. We propose a novel transformer-based Diffusion Planner for closed-loop planning, which can effectively model multi-modal driving behavior and ensure trajectory quality without any rule-based refinement. Our model supports joint modeling of both prediction and planning tasks under the same architecture, enabling cooperative behaviors between vehicles. Moreover, by learning the gradient of the trajectory score function and employing a flexible classifier guidance mechanism, Diffusion Planner effectively achieves safe and adaptable planning behaviors. Evaluations on the large-scale real-world autonomous planning benchmark nuPlan and our newly collected 200-hour delivery-vehicle driving dataset demonstrate that Diffusion Planner achieves state-of-the-art closed-loop performance with robust transferability in diverse driving styles.
RGM: Reconstructing High-fidelity 3D Car Assets with Relightable 3D-GS Generative Model from a Single Image
Oct 10, 2024



The generation of high-quality 3D car assets is essential for various applications, including video games, autonomous driving, and virtual reality. Current 3D generation methods utilizing NeRF or 3D-GS as representations for 3D objects, generate a Lambertian object under fixed lighting and lack separated modelings for material and global illumination. As a result, the generated assets are unsuitable for relighting under varying lighting conditions, limiting their applicability in downstream tasks. To address this challenge, we propose a novel relightable 3D object generative framework that automates the creation of 3D car assets, enabling the swift and accurate reconstruction of a vehicle's geometry, texture, and material properties from a single input image. Our approach begins with introducing a large-scale synthetic car dataset comprising over 1,000 high-precision 3D vehicle models. We represent 3D objects using global illumination and relightable 3D Gaussian primitives integrating with BRDF parameters. Building on this representation, we introduce a feed-forward model that takes images as input and outputs both relightable 3D Gaussians and global illumination parameters. Experimental results demonstrate that our method produces photorealistic 3D car assets that can be seamlessly integrated into road scenes with different illuminations, which offers substantial practical benefits for industrial applications.
PRISM: PRogressive dependency maxImization for Scale-invariant image Matching
Aug 07, 2024

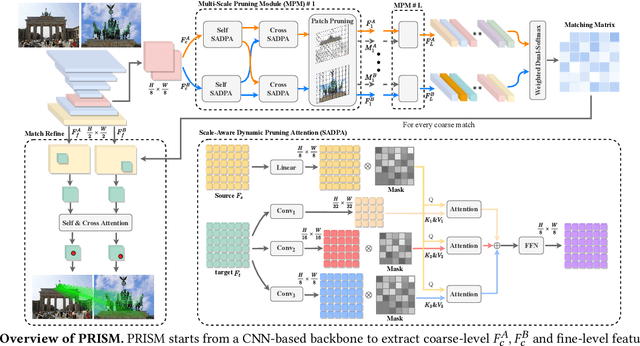

Image matching aims at identifying corresponding points between a pair of images. Currently, detector-free methods have shown impressive performance in challenging scenarios, thanks to their capability of generating dense matches and global receptive field. However, performing feature interaction and proposing matches across the entire image is unnecessary, because not all image regions contribute to the matching process. Interacting and matching in unmatchable areas can introduce errors, reducing matching accuracy and efficiency. Meanwhile, the scale discrepancy issue still troubles existing methods. To address above issues, we propose PRogressive dependency maxImization for Scale-invariant image Matching (PRISM), which jointly prunes irrelevant patch features and tackles the scale discrepancy. To do this, we firstly present a Multi-scale Pruning Module (MPM) to adaptively prune irrelevant features by maximizing the dependency between the two feature sets. Moreover, we design the Scale-Aware Dynamic Pruning Attention (SADPA) to aggregate information from different scales via a hierarchical design. Our method's superior matching performance and generalization capability are confirmed by leading accuracy across various evaluation benchmarks and downstream tasks. The code is publicly available at https://github.com/Master-cai/PRISM.
S4TP: Social-Suitable and Safety-Sensitive Trajectory Planning for Autonomous Vehicles
Apr 18, 2024



In public roads, autonomous vehicles (AVs) face the challenge of frequent interactions with human-driven vehicles (HDVs), which render uncertain driving behavior due to varying social characteristics among humans. To effectively assess the risks prevailing in the vicinity of AVs in social interactive traffic scenarios and achieve safe autonomous driving, this article proposes a social-suitable and safety-sensitive trajectory planning (S4TP) framework. Specifically, S4TP integrates the Social-Aware Trajectory Prediction (SATP) and Social-Aware Driving Risk Field (SADRF) modules. SATP utilizes Transformers to effectively encode the driving scene and incorporates an AV's planned trajectory during the prediction decoding process. SADRF assesses the expected surrounding risk degrees during AVs-HDVs interactions, each with different social characteristics, visualized as two-dimensional heat maps centered on the AV. SADRF models the driving intentions of the surrounding HDVs and predicts trajectories based on the representation of vehicular interactions. S4TP employs an optimization-based approach for motion planning, utilizing the predicted HDVs'trajectories as input. With the integration of SADRF, S4TP executes real-time online optimization of the planned trajectory of AV within lowrisk regions, thus improving the safety and the interpretability of the planned trajectory. We have conducted comprehensive tests of the proposed method using the SMARTS simulator. Experimental results in complex social scenarios, such as unprotected left turn intersections, merging, cruising, and overtaking, validate the superiority of our proposed S4TP in terms of safety and rationality. S4TP achieves a pass rate of 100% across all scenarios, surpassing the current state-of-the-art methods Fanta of 98.25% and Predictive-Decision of 94.75%.
SA-GS: Scale-Adaptive Gaussian Splatting for Training-Free Anti-Aliasing
Mar 28, 2024



In this paper, we present a Scale-adaptive method for Anti-aliasing Gaussian Splatting (SA-GS). While the state-of-the-art method Mip-Splatting needs modifying the training procedure of Gaussian splatting, our method functions at test-time and is training-free. Specifically, SA-GS can be applied to any pretrained Gaussian splatting field as a plugin to significantly improve the field's anti-alising performance. The core technique is to apply 2D scale-adaptive filters to each Gaussian during test time. As pointed out by Mip-Splatting, observing Gaussians at different frequencies leads to mismatches between the Gaussian scales during training and testing. Mip-Splatting resolves this issue using 3D smoothing and 2D Mip filters, which are unfortunately not aware of testing frequency. In this work, we show that a 2D scale-adaptive filter that is informed of testing frequency can effectively match the Gaussian scale, thus making the Gaussian primitive distribution remain consistent across different testing frequencies. When scale inconsistency is eliminated, sampling rates smaller than the scene frequency result in conventional jaggedness, and we propose to integrate the projected 2D Gaussian within each pixel during testing. This integration is actually a limiting case of super-sampling, which significantly improves anti-aliasing performance over vanilla Gaussian Splatting. Through extensive experiments using various settings and both bounded and unbounded scenes, we show SA-GS performs comparably with or better than Mip-Splatting. Note that super-sampling and integration are only effective when our scale-adaptive filtering is activated. Our codes, data and models are available at https://github.com/zsy1987/SA-GS.
ModaLink: Unifying Modalities for Efficient Image-to-PointCloud Place Recognition
Mar 27, 2024



Place recognition is an important task for robots and autonomous cars to localize themselves and close loops in pre-built maps. While single-modal sensor-based methods have shown satisfactory performance, cross-modal place recognition that retrieving images from a point-cloud database remains a challenging problem. Current cross-modal methods transform images into 3D points using depth estimation for modality conversion, which are usually computationally intensive and need expensive labeled data for depth supervision. In this work, we introduce a fast and lightweight framework to encode images and point clouds into place-distinctive descriptors. We propose an effective Field of View (FoV) transformation module to convert point clouds into an analogous modality as images. This module eliminates the necessity for depth estimation and helps subsequent modules achieve real-time performance. We further design a non-negative factorization-based encoder to extract mutually consistent semantic features between point clouds and images. This encoder yields more distinctive global descriptors for retrieval. Experimental results on the KITTI dataset show that our proposed methods achieve state-of-the-art performance while running in real time. Additional evaluation on the HAOMO dataset covering a 17 km trajectory further shows the practical generalization capabilities. We have released the implementation of our methods as open source at: https://github.com/haomo-ai/ModaLink.git.