 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving
Mar 20, 2026Scalable and reliable evaluation is increasingly critical in the end-to-end era of autonomous driving, where vision--language--action (VLA) policies directly map raw sensor streams to driving actions. Yet, current evaluation pipelines still rely heavily on real-world road testing, which is costly, biased toward limited scenario coverage, and difficult to reproduce. These challenges motivate a real-world simulator that can generate realistic future observations under proposed actions, while remaining controllable and stable over long horizons. We present X-World, an action-conditioned multi-camera generative world model that simulates future observations directly in video space. Given synchronized multi-view camera history and a future action sequence, X-World generates future multi-camera video streams that follow the commanded actions. To ensure reproducible and editable scene rollouts, X-World further supports optional controls over dynamic traffic agents and static road elements, and retains a text-prompt interface for appearance-level control (e.g., weather and time of day). Beyond world simulation, X-World also enables video style transfer by conditioning on appearance prompts while preserving the underlying action and scene dynamics. At the core of X-World is a multi-view latent video generator designed to explicitly encourage cross-view geometric consistency and temporal coherence under diverse control signals. Experiments show that X-World achieves high-quality multi-view video generation with (i) strong view consistency across cameras, (ii) stable temporal dynamics over long rollouts, and (iii) high controllability with strict action following and faithful adherence to optional scene controls. These properties make X-World a practical foundation for scalable and reproducible evaluation.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025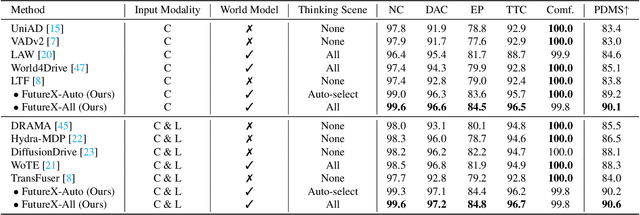
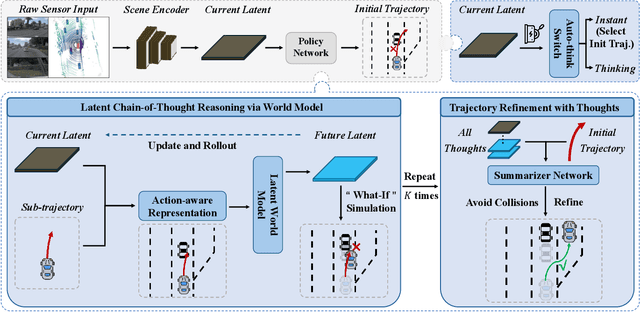

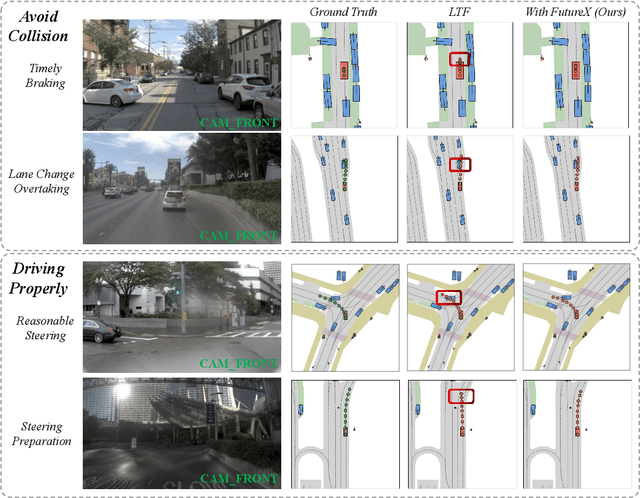
In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
CogAD: Cognitive-Hierarchy Guided End-to-End Autonomous Driving
May 27, 2025While end-to-end autonomous driving has advanced significantly, prevailing methods remain fundamentally misaligned with human cognitive principles in both perception and planning. In this paper, we propose CogAD, a novel end-to-end autonomous driving model that emulates the hierarchical cognition mechanisms of human drivers. CogAD implements dual hierarchical mechanisms: global-to-local context processing for human-like perception and intent-conditioned multi-mode trajectory generation for cognitively-inspired planning. The proposed method demonstrates three principal advantages: comprehensive environmental understanding through hierarchical perception, robust planning exploration enabled by multi-level planning, and diverse yet reasonable multi-modal trajectory generation facilitated by dual-level uncertainty modeling. Extensive experiments on nuScenes and Bench2Drive demonstrate that CogAD achieves state-of-the-art performance in end-to-end planning, exhibiting particular superiority in long-tail scenarios and robust generalization to complex real-world driving conditions.
Text-Video Retrieval with Disentangled Conceptualization and Set-to-Set Alignment
May 20, 2023Text-video retrieval is a challenging cross-modal task, which aims to align visual entities with natural language descriptions. Current methods either fail to leverage the local details or are computationally expensive. What's worse, they fail to leverage the heterogeneous concepts in data. In this paper, we propose the Disentangled Conceptualization and Set-to-set Alignment (DiCoSA) to simulate the conceptualizing and reasoning process of human beings. For disentangled conceptualization, we divide the coarse feature into multiple latent factors related to semantic concepts. For set-to-set alignment, where a set of visual concepts correspond to a set of textual concepts, we propose an adaptive pooling method to aggregate semantic concepts to address the partial matching. In particular, since we encode concepts independently in only a few dimensions, DiCoSA is superior at efficiency and granularity, ensuring fine-grained interactions using a similar computational complexity as coarse-grained alignment. Extensive experiments on five datasets, including MSR-VTT, LSMDC, MSVD, ActivityNet, and DiDeMo, demonstrate that our method outperforms the existing state-of-the-art methods.
TG-VQA: Ternary Game of Video Question Answering
May 18, 2023Video question answering aims at answering a question about the video content by reasoning the alignment semantics within them. However, since relying heavily on human instructions, i.e., annotations or priors, current contrastive learning-based VideoQA methods remains challenging to perform fine-grained visual-linguistic alignments. In this work, we innovatively resort to game theory, which can simulate complicated relationships among multiple players with specific interaction strategies, e.g., video, question, and answer as ternary players, to achieve fine-grained alignment for VideoQA task. Specifically, we carefully design a VideoQA-specific interaction strategy to tailor the characteristics of VideoQA, which can mathematically generate the fine-grained visual-linguistic alignment label without label-intensive efforts. Our TG-VQA outperforms existing state-of-the-art by a large margin (more than 5%) on long-term and short-term VideoQA datasets, verifying its effectiveness and generalization ability. Thanks to the guidance of game-theoretic interaction, our model impressively convergences well on limited data (${10}^4 ~videos$), surpassing most of those pre-trained on large-scale data ($10^7~videos$).
Multi-granularity Interaction Simulation for Unsupervised Interactive Segmentation
Mar 23, 2023



Interactive segmentation enables users to segment as needed by providing cues of objects, which introduces human-computer interaction for many fields, such as image editing and medical image analysis. Typically, massive and expansive pixel-level annotations are spent to train deep models by object-oriented interactions with manually labeled object masks. In this work, we reveal that informative interactions can be made by simulation with semantic-consistent yet diverse region exploration in an unsupervised paradigm. Concretely, we introduce a Multi-granularity Interaction Simulation (MIS) approach to open up a promising direction for unsupervised interactive segmentation. Drawing on the high-quality dense features produced by recent self-supervised models, we propose to gradually merge patches or regions with similar features to form more extensive regions and thus, every merged region serves as a semantic-meaningful multi-granularity proposal. By randomly sampling these proposals and simulating possible interactions based on them, we provide meaningful interaction at multiple granularities to teach the model to understand interactions. Our MIS significantly outperforms non-deep learning unsupervised methods and is even comparable with some previous deep-supervised methods without any annotation.
Position Embedding Needs an Independent Layer Normalization
Dec 22, 2022



The Position Embedding (PE) is critical for Vision Transformers (VTs) due to the permutation-invariance of self-attention operation. By analyzing the input and output of each encoder layer in VTs using reparameterization and visualization, we find that the default PE joining method (simply adding the PE and patch embedding together) operates the same affine transformation to token embedding and PE, which limits the expressiveness of PE and hence constrains the performance of VTs. To overcome this limitation, we propose a simple, effective, and robust method. Specifically, we provide two independent layer normalizations for token embeddings and PE for each layer, and add them together as the input of each layer's Muti-Head Self-Attention module. Since the method allows the model to adaptively adjust the information of PE for different layers, we name it as Layer-adaptive Position Embedding, abbreviated as LaPE. Extensive experiments demonstrate that LaPE can improve various VTs with different types of PE and make VTs robust to PE types. For example, LaPE improves 0.94% accuracy for ViT-Lite on Cifar10, 0.98% for CCT on Cifar100, and 1.72% for DeiT on ImageNet-1K, which is remarkable considering the negligible extra parameters, memory and computational cost brought by LaPE. The code is publicly available at https://github.com/Ingrid725/LaPE.
PCR: Pessimistic Consistency Regularization for Semi-Supervised Segmentation
Oct 16, 2022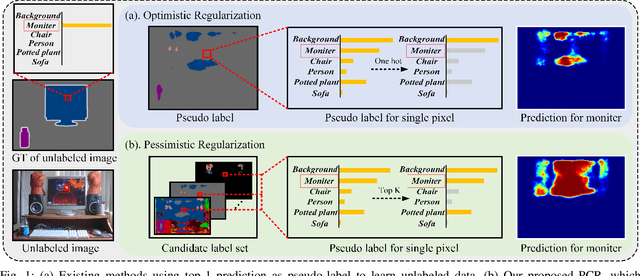
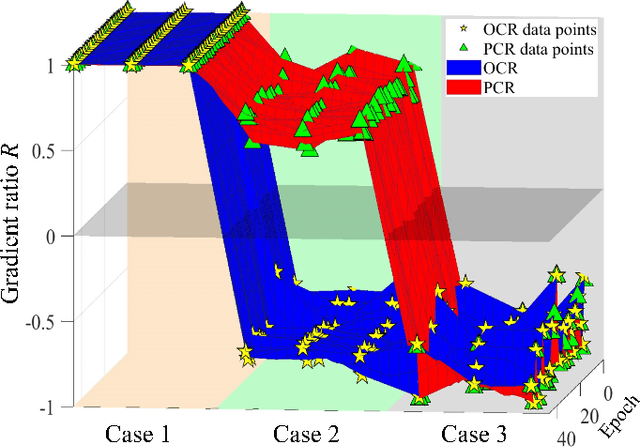
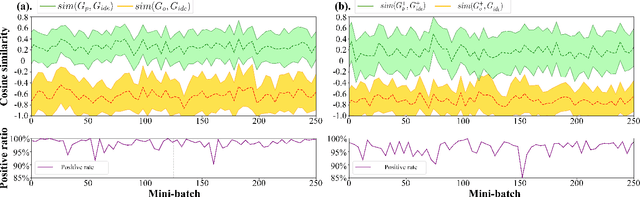
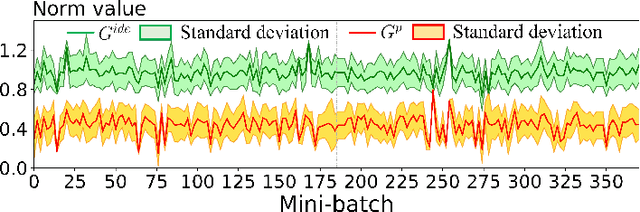
Currently, state-of-the-art semi-supervised learning (SSL) segmentation methods employ pseudo labels to train their models, which is an optimistic training manner that supposes the predicted pseudo labels are correct. However, their models will be optimized incorrectly when the above assumption does not hold. In this paper, we propose a Pessimistic Consistency Regularization (PCR) which considers a pessimistic case that pseudo labels are not always correct. PCR makes it possible for our model to learn the ground truth (GT) in pessimism by adaptively providing a candidate label set containing K proposals for each unlabeled pixel. Specifically, we propose a pessimistic consistency loss which trains our model to learn the possible GT from multiple candidate labels. In addition, we develop a candidate label proposal method to adaptively decide which pseudo labels are provided for each pixel. Our method is easy to implement and could be applied to existing baselines without changing their frameworks. Theoretical analysis and experiments on various benchmarks demonstrate the superiority of our approach to state-of-the-art alternatives.
Dynamic Clustering Network for Unsupervised Semantic Segmentation
Oct 12, 2022



Recently, the ability of self-supervised Vision Transformer (ViT) to represent pixel-level semantic relationships promotes the development of unsupervised dense prediction tasks. In this work, we investigate transferring self-supervised ViT to unsupervised semantic segmentation task. According to the analysis that the pixel-level representations of self-supervised ViT within a single image achieve good intra-class compactness and inter-class discrimination, we propose the Dynamic Clustering Network (DCN) to dynamically infer the underlying cluster centers for different images. By training with the proposed modularity loss, the DCN learns to project a set of prototypes to cluster centers for pixel representations in each image and assign pixels to different clusters, resulting on dividing each image to class-agnostic regions. For achieving unsupervised semantic segmentation task, we treat it as a region classification problem. Based on the regions produced by the DCN, we explore different ways to extract region-level representations and classify them in an unsupervised manner. We demonstrate the effectiveness of the proposed method trough experiments on unsupervised semantic segmentation, and achieve state-of-the-art performance on PASCAL VOC 2012 unsupervised semantic segmentation task.
Locality Guidance for Improving Vision Transformers on Tiny Datasets
Jul 20, 2022


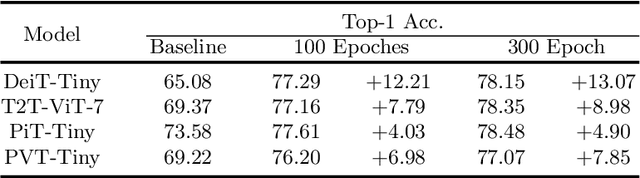
While the Vision Transformer (VT) architecture is becoming trendy in computer vision, pure VT models perform poorly on tiny datasets. To address this issue, this paper proposes the locality guidance for improving the performance of VTs on tiny datasets. We first analyze that the local information, which is of great importance for understanding images, is hard to be learned with limited data due to the high flexibility and intrinsic globality of the self-attention mechanism in VTs. To facilitate local information, we realize the locality guidance for VTs by imitating the features of an already trained convolutional neural network (CNN), inspired by the built-in local-to-global hierarchy of CNN. Under our dual-task learning paradigm, the locality guidance provided by a lightweight CNN trained on low-resolution images is adequate to accelerate the convergence and improve the performance of VTs to a large extent. Therefore, our locality guidance approach is very simple and efficient, and can serve as a basic performance enhancement method for VTs on tiny datasets. Extensive experiments demonstrate that our method can significantly improve VTs when training from scratch on tiny datasets and is compatible with different kinds of VTs and datasets. For example, our proposed method can boost the performance of various VTs on tiny datasets (e.g., 13.07% for DeiT, 8.98% for T2T and 7.85% for PVT), and enhance even stronger baseline PVTv2 by 1.86% to 79.30%, showing the potential of VTs on tiny datasets. The code is available at https://github.com/lkhl/tiny-transformers.