 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune-Your-Style: Intensity-tunable 3D Style Transfer with Gaussian Splatting
Jan 31, 20263D style transfer refers to the artistic stylization of 3D assets based on reference style images. Recently, 3DGS-based stylization methods have drawn considerable attention, primarily due to their markedly enhanced training and rendering speeds. However, a vital challenge for 3D style transfer is to strike a balance between the content and the patterns and colors of the style. Although the existing methods strive to achieve relatively balanced outcomes, the fixed-output paradigm struggles to adapt to the diverse content-style balance requirements from different users. In this work, we introduce a creative intensity-tunable 3D style transfer paradigm, dubbed \textbf{Tune-Your-Style}, which allows users to flexibly adjust the style intensity injected into the scene to match their desired content-style balance, thus enhancing the customizability of 3D style transfer. To achieve this goal, we first introduce Gaussian neurons to explicitly model the style intensity and parameterize a learnable style tuner to achieve intensity-tunable style injection. To facilitate the learning of tunable stylization, we further propose the tunable stylization guidance, which obtains multi-view consistent stylized views from diffusion models through cross-view style alignment, and then employs a two-stage optimization strategy to provide stable and efficient guidance by modulating the balance between full-style guidance from the stylized views and zero-style guidance from the initial rendering. Extensive experiments demonstrate that our method not only delivers visually appealing results, but also exhibits flexible customizability for 3D style transfer. Project page is available at https://zhao-yian.github.io/TuneStyle.
iSegMan: Interactive Segment-and-Manipulate 3D Gaussians
May 17, 2025



The efficient rendering and explicit nature of 3DGS promote the advancement of 3D scene manipulation. However, existing methods typically encounter challenges in controlling the manipulation region and are unable to furnish the user with interactive feedback, which inevitably leads to unexpected results. Intuitively, incorporating interactive 3D segmentation tools can compensate for this deficiency. Nevertheless, existing segmentation frameworks impose a pre-processing step of scene-specific parameter training, which limits the efficiency and flexibility of scene manipulation. To deliver a 3D region control module that is well-suited for scene manipulation with reliable efficiency, we propose interactive Segment-and-Manipulate 3D Gaussians (iSegMan), an interactive segmentation and manipulation framework that only requires simple 2D user interactions in any view. To propagate user interactions to other views, we propose Epipolar-guided Interaction Propagation (EIP), which innovatively exploits epipolar constraint for efficient and robust interaction matching. To avoid scene-specific training to maintain efficiency, we further propose the novel Visibility-based Gaussian Voting (VGV), which obtains 2D segmentations from SAM and models the region extraction as a voting game between 2D Pixels and 3D Gaussians based on Gaussian visibility. Taking advantage of the efficient and precise region control of EIP and VGV, we put forth a Manipulation Toolbox to implement various functions on selected regions, enhancing the controllability, flexibility and practicality of scene manipulation. Extensive results on 3D scene manipulation and segmentation tasks fully demonstrate the significant advantages of iSegMan. Project page is available at https://zhao-yian.github.io/iSegMan.
GraCo: Granularity-Controllable Interactive Segmentation
May 01, 2024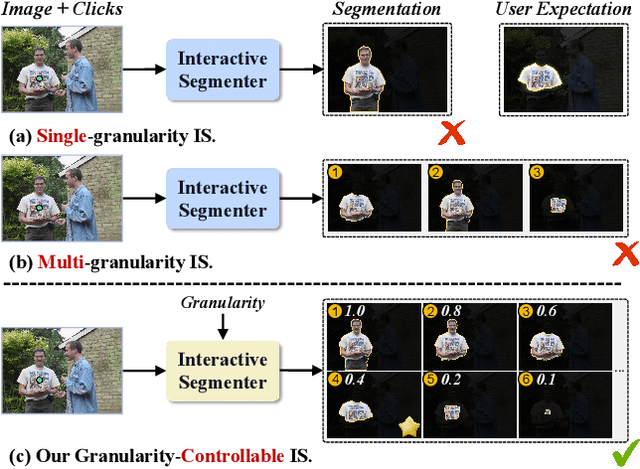
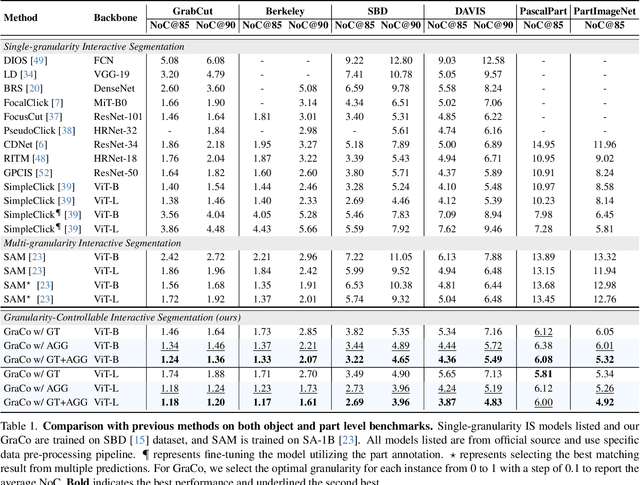
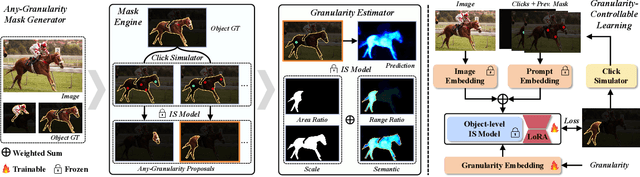
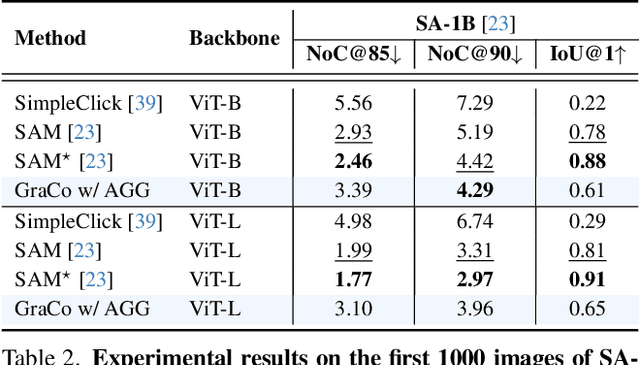
Interactive Segmentation (IS) segments specific objects or parts in the image according to user input. Current IS pipelines fall into two categories: single-granularity output and multi-granularity output. The latter aims to alleviate the spatial ambiguity present in the former. However, the multi-granularity output pipeline suffers from limited interaction flexibility and produces redundant results. In this work, we introduce Granularity-Controllable Interactive Segmentation (GraCo), a novel approach that allows precise control of prediction granularity by introducing additional parameters to input. This enhances the customization of the interactive system and eliminates redundancy while resolving ambiguity. Nevertheless, the exorbitant cost of annotating multi-granularity masks and the lack of available datasets with granularity annotations make it difficult for models to acquire the necessary guidance to control output granularity. To address this problem, we design an any-granularity mask generator that exploits the semantic property of the pre-trained IS model to automatically generate abundant mask-granularity pairs without requiring additional manual annotation. Based on these pairs, we propose a granularity-controllable learning strategy that efficiently imparts the granularity controllability to the IS model. Extensive experiments on intricate scenarios at object and part levels demonstrate that our GraCo has significant advantages over previous methods. This highlights the potential of GraCo to be a flexible annotation tool, capable of adapting to diverse segmentation scenarios. The project page: https://zhao-yian.github.io/GraCo.
FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
Mar 11, 2024

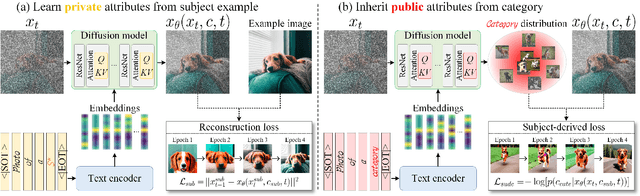

Subject-driven generation has garnered significant interest recently due to its ability to personalize text-to-image generation. Typical works focus on learning the new subject's private attributes. However, an important fact has not been taken seriously that a subject is not an isolated new concept but should be a specialization of a certain category in the pre-trained model. This results in the subject failing to comprehensively inherit the attributes in its category, causing poor attribute-related generations. In this paper, motivated by object-oriented programming, we model the subject as a derived class whose base class is its semantic category. This modeling enables the subject to inherit public attributes from its category while learning its private attributes from the user-provided example. Specifically, we propose a plug-and-play method, Subject-Derived regularization (SuDe). It constructs the base-derived class modeling by constraining the subject-driven generated images to semantically belong to the subject's category. Extensive experiments under three baselines and two backbones on various subjects show that our SuDe enables imaginative attribute-related generations while maintaining subject fidelity. Codes will be open sourced soon at FaceChain (https://github.com/modelscope/facechain).
Out-of-Distributed Semantic Pruning for Robust Semi-Supervised Learning
May 30, 2023Recent advances in robust semi-supervised learning (SSL) typically filter out-of-distribution (OOD) information at the sample level. We argue that an overlooked problem of robust SSL is its corrupted information on semantic level, practically limiting the development of the field. In this paper, we take an initial step to explore and propose a unified framework termed OOD Semantic Pruning (OSP), which aims at pruning OOD semantics out from in-distribution (ID) features. Specifically, (i) we propose an aliasing OOD matching module to pair each ID sample with an OOD sample with semantic overlap. (ii) We design a soft orthogonality regularization, which first transforms each ID feature by suppressing its semantic component that is collinear with paired OOD sample. It then forces the predictions before and after soft orthogonality decomposition to be consistent. Being practically simple, our method shows a strong performance in OOD detection and ID classification on challenging benchmarks. In particular, OSP surpasses the previous state-of-the-art by 13.7% on accuracy for ID classification and 5.9% on AUROC for OOD detection on TinyImageNet dataset. The source codes are publicly available at https://github.com/rain305f/OSP.
Out-of-Candidate Rectification for Weakly Supervised Semantic Segmentation
Nov 22, 2022Weakly supervised semantic segmentation is typically inspired by class activation maps, which serve as pseudo masks with class-discriminative regions highlighted. Although tremendous efforts have been made to recall precise and complete locations for each class, existing methods still commonly suffer from the unsolicited Out-of-Candidate (OC) error predictions that not belongs to the label candidates, which could be avoidable since the contradiction with image-level class tags is easy to be detected. In this paper, we develop a group ranking-based Out-of-Candidate Rectification (OCR) mechanism in a plug-and-play fashion. Firstly, we adaptively split the semantic categories into In-Candidate (IC) and OC groups for each OC pixel according to their prior annotation correlation and posterior prediction correlation. Then, we derive a differentiable rectification loss to force OC pixels to shift to the IC group. Incorporating our OCR with seminal baselines (e.g., AffinityNet, SEAM, MCTformer), we can achieve remarkable performance gains on both Pascal VOC (+3.2%, +3.3%, +0.8% mIoU) and MS COCO (+1.0%, +1.3%, +0.5% mIoU) datasets with negligible extra training overhead, which justifies the effectiveness and generality of our OCR.
PCR: Pessimistic Consistency Regularization for Semi-Supervised Segmentation
Oct 16, 2022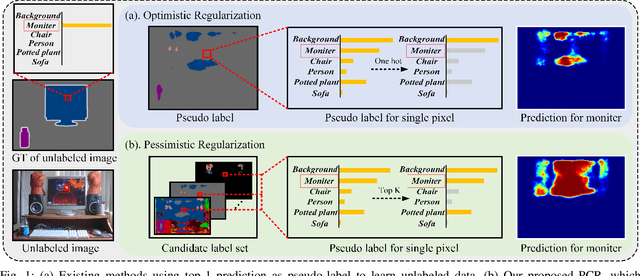
Currently, state-of-the-art semi-supervised learning (SSL) segmentation methods employ pseudo labels to train their models, which is an optimistic training manner that supposes the predicted pseudo labels are correct. However, their models will be optimized incorrectly when the above assumption does not hold. In this paper, we propose a Pessimistic Consistency Regularization (PCR) which considers a pessimistic case that pseudo labels are not always correct. PCR makes it possible for our model to learn the ground truth (GT) in pessimism by adaptively providing a candidate label set containing K proposals for each unlabeled pixel. Specifically, we propose a pessimistic consistency loss which trains our model to learn the possible GT from multiple candidate labels. In addition, we develop a candidate label proposal method to adaptively decide which pseudo labels are provided for each pixel. Our method is easy to implement and could be applied to existing baselines without changing their frameworks. Theoretical analysis and experiments on various benchmarks demonstrate the superiority of our approach to state-of-the-art alternatives.
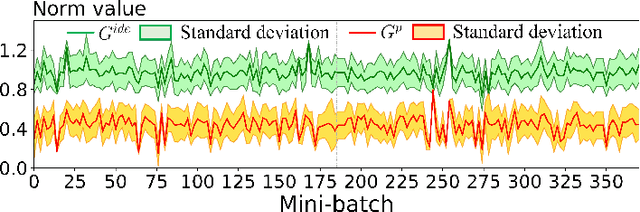
Difference in Euclidean Norm Can Cause Semantic Divergence in Batch Normalization
Jul 06, 2022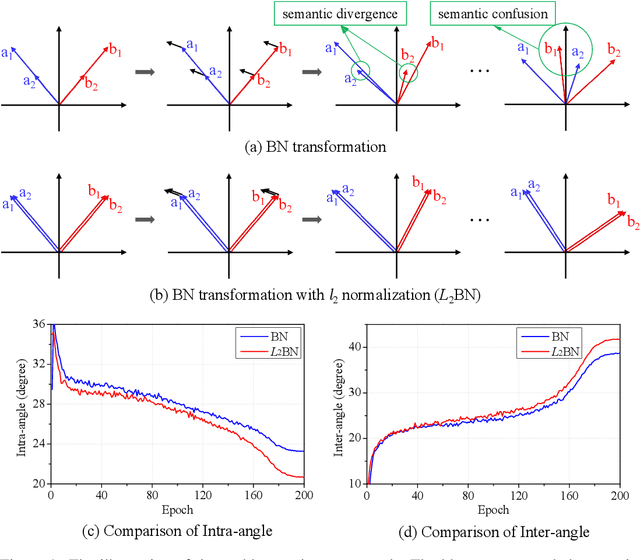

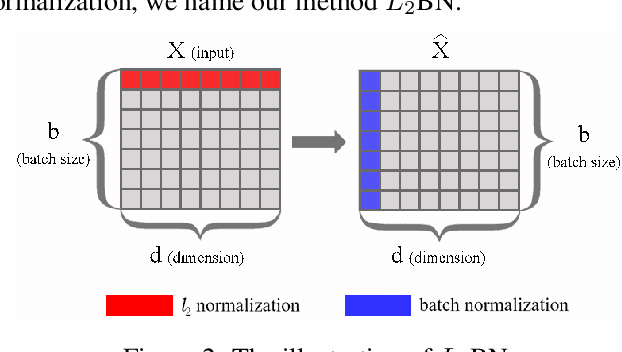
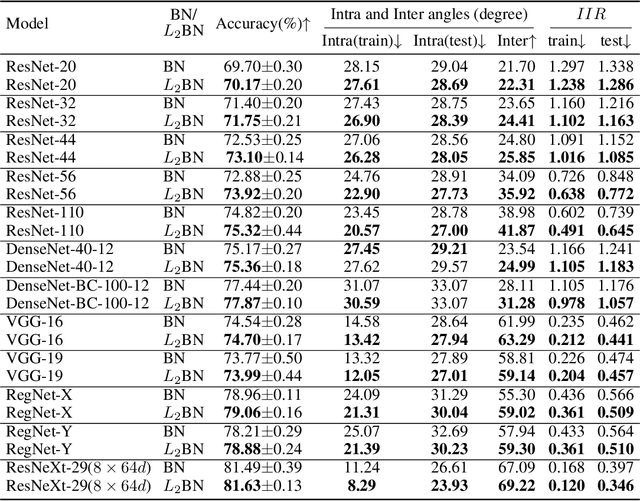
In this paper, we show that the difference in Euclidean norm of samples can make a contribution to the semantic divergence and even confusion, after the spatial translation and scaling transformation in batch normalization. To address this issue, we propose an intuitive but effective method to equalize the Euclidean norms of sample vectors. Concretely, we $l_2$-normalize each sample vector before batch normalization, and therefore the sample vectors are of the same magnitude. Since the proposed method combines the $l_2$ normalization and batch normalization, we name our method as $L_2$BN. The $L_2$BN can strengthen the compactness of intra-class features and enlarge the discrepancy of inter-class features. In addition, it can help the gradient converge to a stable scale. The $L_2$BN is easy to implement and can exert its effect without any additional parameters and hyper-parameters. Therefore, it can be used as a basic normalization method for neural networks. We evaluate the effectiveness of $L_2$BN through extensive experiments with various models on image classification and acoustic scene classification tasks. The experimental results demonstrate that the $L_2$BN is able to boost the generalization ability of various neural network models and achieve considerable performance improvements.
Automated Segmentation of Brain Gray Matter Nuclei on Quantitative Susceptibility Mapping Using Deep Convolutional Neural Network
Aug 03, 2020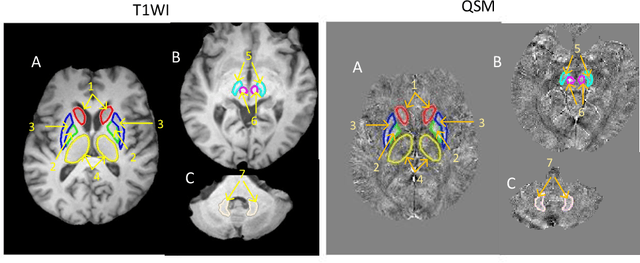
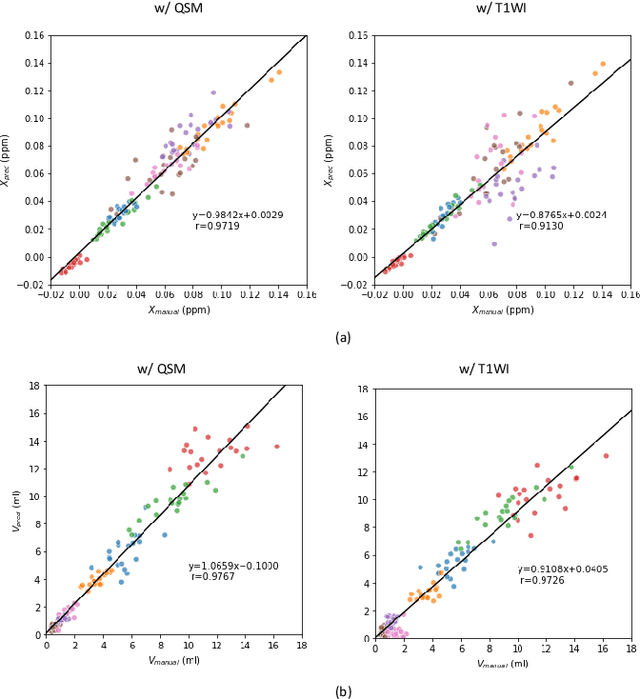
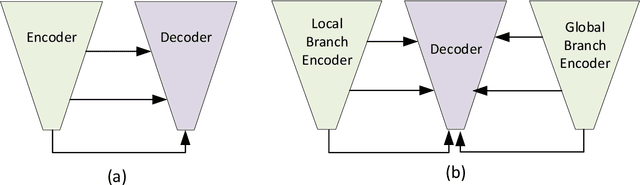
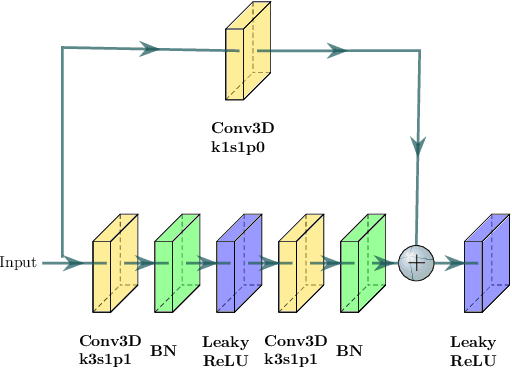
Abnormal iron accumulation in the brain subcortical nuclei has been reported to be correlated to various neurodegenerative diseases, which can be measured through the magnetic susceptibility from the quantitative susceptibility mapping (QSM). To quantitively measure the magnetic susceptibility, the nuclei should be accurately segmented, which is a tedious task for clinicians. In this paper, we proposed a double-branch residual-structured U-Net (DB-ResUNet) based on 3D convolutional neural network (CNN) to automatically segment such brain gray matter nuclei. To better tradeoff between segmentation accuracy and the memory efficiency, the proposed DB-ResUNet fed image patches with high resolution and the patches with low resolution but larger field of view into the local and global branches, respectively. Experimental results revealed that by jointly using QSM and T$_\text{1}$ weighted imaging (T$_\text{1}$WI) as inputs, the proposed method was able to achieve better segmentation accuracy over its single-branch counterpart, as well as the conventional atlas-based method and the classical 3D-UNet structure. The susceptibility values and the volumes were also measured, which indicated that the measurements from the proposed DB-ResUNet are able to present high correlation with values from the manually annotated regions of interest.