 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPCD: Adaptive Path-Contrastive Decoding for Reliable Large Language Model Generation
May 10, 2026Large language models (LLMs) often suffer from hallucinations due to error accumulation in autoregressive decoding, where suboptimal early token choices misguide subsequent generation. Although multi-path decoding can improve robustness by exploring alternative trajectories, existing methods lack principled strategies for determining when to branch and how to regulate inter-path interactions. We propose Adaptive Path-Contrastive Decoding (APCD), a multi-path decoding framework that improves output reliability through adaptive exploration and controlled path interaction. APCD consists of two components: (1) Entropy-Driven Path Expansion, which delays branching until predictive uncertainty - measured by Shannon entropy over top candidate tokens - indicates multiple plausible continuations; and (2) Divergence-Aware Path Contrast, which encourages diverse reasoning trajectories while dynamically attenuating inter-path influence as prediction distributions diverge. Experiments on eight benchmarks demonstrate improved factual accuracy while maintaining decoding efficiency. Our code is available at https://github.com/zty-king/APCD.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
SeLIP: Similarity Enhanced Contrastive Language Image Pretraining for Multi-modal Head MRI
Mar 25, 2025



Despite that deep learning (DL) methods have presented tremendous potential in many medical image analysis tasks, the practical applications of medical DL models are limited due to the lack of enough data samples with manual annotations. By noting that the clinical radiology examinations are associated with radiology reports that describe the images, we propose to develop a foundation model for multi-model head MRI by using contrastive learning on the images and the corresponding radiology findings. In particular, a contrastive learning framework is proposed, where a mixed syntax and semantic similarity matching metric is integrated to reduce the thirst of extreme large dataset in conventional contrastive learning framework. Our proposed similarity enhanced contrastive language image pretraining (SeLIP) is able to effectively extract more useful features. Experiments revealed that our proposed SeLIP performs well in many downstream tasks including image-text retrieval task, classification task, and image segmentation, which highlights the importance of considering the similarities among texts describing different images in developing medical image foundation models.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
A Review of Image Processing Methods in Prostate Ultrasound
Jun 30, 2024Prostate cancer (PCa) poses a significant threat to men's health, with early diagnosis being crucial for improving prognosis and reducing mortality rates. Transrectal ultrasound (TRUS) plays a vital role in the diagnosis and image-guided intervention of PCa.To facilitate physicians with more accurate and efficient computer-assisted diagnosis and interventions, many image processing algorithms in TRUS have been proposed and achieved state-of-the-art performance in several tasks, including prostate gland segmentation, prostate image registration, PCa classification and detection, and interventional needle detection.The rapid development of these algorithms over the past two decades necessitates a comprehensive summary. In consequence, this survey provides a systematic analysis of this field, outlining the evolution of image processing methods in the context of TRUS image analysis and meanwhile highlighting their relevant contributions. Furthermore, this survey discusses current challenges and suggests future research directions to possibly advance this field further.
Towards Multi-modality Fusion and Prototype-based Feature Refinement for Clinically Significant Prostate Cancer Classification in Transrectal Ultrasound
Jun 20, 2024Prostate cancer is a highly prevalent cancer and ranks as the second leading cause of cancer-related deaths in men globally. Recently, the utilization of multi-modality transrectal ultrasound (TRUS) has gained significant traction as a valuable technique for guiding prostate biopsies. In this study, we propose a novel learning framework for clinically significant prostate cancer (csPCa) classification using multi-modality TRUS. The proposed framework employs two separate 3D ResNet-50 to extract distinctive features from B-mode and shear wave elastography (SWE). Additionally, an attention module is incorporated to effectively refine B-mode features and aggregate the extracted features from both modalities. Furthermore, we utilize few shot segmentation task to enhance the capacity of classification encoder. Due to the limited availability of csPCa masks, a prototype correction module is employed to extract representative prototypes of csPCa. The performance of the framework is assessed on a large-scale dataset consisting of 512 TRUS videos with biopsy-proved prostate cancer. The results demonstrate the strong capability in accurately identifying csPCa, achieving an area under the curve (AUC) of 0.86. Moreover, the framework generates visual class activation mapping (CAM), which can serve as valuable assistance for localizing csPCa. These CAM images may offer valuable guidance during TRUS-guided targeted biopsies, enhancing the efficacy of the biopsy procedure.The code is available at https://github.com/2313595986/SmileCode.
Efficient Multi-View Fusion and Flexible Adaptation to View Missing in Cardiovascular System Signals
Jun 13, 2024The progression of deep learning and the widespread adoption of sensors have facilitated automatic multi-view fusion (MVF) about the cardiovascular system (CVS) signals. However, prevalent MVF model architecture often amalgamates CVS signals from the same temporal step but different views into a unified representation, disregarding the asynchronous nature of cardiovascular events and the inherent heterogeneity across views, leading to catastrophic view confusion. Efficient training strategies specifically tailored for MVF models to attain comprehensive representations need simultaneous consideration. Crucially, real-world data frequently arrives with incomplete views, an aspect rarely noticed by researchers. Thus, the View-Centric Transformer (VCT) and Multitask Masked Autoencoder (M2AE) are specifically designed to emphasize the centrality of each view and harness unlabeled data to achieve superior fused representations. Additionally, we systematically define the missing-view problem for the first time and introduce prompt techniques to aid pretrained MVF models in flexibly adapting to various missing-view scenarios. Rigorous experiments involving atrial fibrillation detection, blood pressure estimation, and sleep staging-typical health monitoring tasks-demonstrate the remarkable advantage of our method in MVF compared to prevailing methodologies. Notably, the prompt technique requires finetuning less than 3% of the entire model's data, substantially fortifying the model's resilience to view missing while circumventing the need for complete retraining. The results demonstrate the effectiveness of our approaches, highlighting their potential for practical applications in cardiovascular health monitoring. Codes and models are released at URL.
Multi-modality transrectal ultrasound video classification for identification of clinically significant prostate cancer
Feb 17, 2024

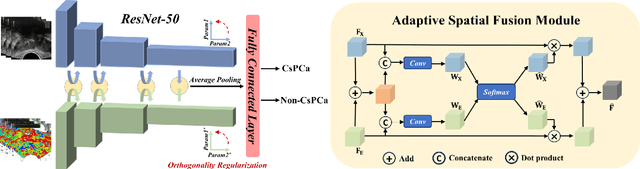
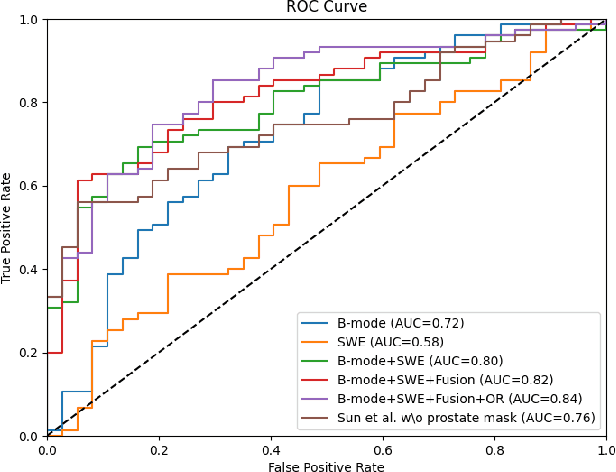
Prostate cancer is the most common noncutaneous cancer in the world. Recently, multi-modality transrectal ultrasound (TRUS) has increasingly become an effective tool for the guidance of prostate biopsies. With the aim of effectively identifying prostate cancer, we propose a framework for the classification of clinically significant prostate cancer (csPCa) from multi-modality TRUS videos. The framework utilizes two 3D ResNet-50 models to extract features from B-mode images and shear wave elastography images, respectively. An adaptive spatial fusion module is introduced to aggregate two modalities' features. An orthogonal regularized loss is further used to mitigate feature redundancy. The proposed framework is evaluated on an in-house dataset containing 512 TRUS videos, and achieves favorable performance in identifying csPCa with an area under curve (AUC) of 0.84. Furthermore, the visualized class activation mapping (CAM) images generated from the proposed framework may provide valuable guidance for the localization of csPCa, thus facilitating the TRUS-guided targeted biopsy. Our code is publicly available at https://github.com/2313595986/ProstateTRUS.
A Prototype-Based Neural Network for Image Anomaly Detection and Localization
Oct 04, 2023Image anomaly detection and localization perform not only image-level anomaly classification but also locate pixel-level anomaly regions. Recently, it has received much research attention due to its wide application in various fields. This paper proposes ProtoAD, a prototype-based neural network for image anomaly detection and localization. First, the patch features of normal images are extracted by a deep network pre-trained on nature images. Then, the prototypes of the normal patch features are learned by non-parametric clustering. Finally, we construct an image anomaly localization network (ProtoAD) by appending the feature extraction network with $L2$ feature normalization, a $1\times1$ convolutional layer, a channel max-pooling, and a subtraction operation. We use the prototypes as the kernels of the $1\times1$ convolutional layer; therefore, our neural network does not need a training phase and can conduct anomaly detection and localization in an end-to-end manner. Extensive experiments on two challenging industrial anomaly detection datasets, MVTec AD and BTAD, demonstrate that ProtoAD achieves competitive performance compared to the state-of-the-art methods with a higher inference speed. The source code is available at: https://github.com/98chao/ProtoAD.
A Unified and Efficient Coordinating Framework for Autonomous DBMS Tuning
Mar 10, 2023Recently using machine learning (ML) based techniques to optimize modern database management systems has attracted intensive interest from both industry and academia. With an objective to tune a specific component of a DBMS (e.g., index selection, knobs tuning), the ML-based tuning agents have shown to be able to find better configurations than experienced database administrators. However, one critical yet challenging question remains unexplored -- how to make those ML-based tuning agents work collaboratively. Existing methods do not consider the dependencies among the multiple agents, and the model used by each agent only studies the effect of changing the configurations in a single component. To tune different components for DBMS, a coordinating mechanism is needed to make the multiple agents cognizant of each other. Also, we need to decide how to allocate the limited tuning budget among the agents to maximize the performance. Such a decision is difficult to make since the distribution of the reward for each agent is unknown and non-stationary. In this paper, we study the above question and present a unified coordinating framework to efficiently utilize existing ML-based agents. First, we propose a message propagation protocol that specifies the collaboration behaviors for agents and encapsulates the global tuning messages in each agent's model. Second, we combine Thompson Sampling, a well-studied reinforcement learning algorithm with a memory buffer so that our framework can allocate budget judiciously in a non-stationary environment. Our framework defines the interfaces adapted to a broad class of ML-based tuning agents, yet simple enough for integration with existing implementations and future extensions. We show that it can effectively utilize different ML-based agents and find better configurations with 1.4~14.1X speedups on the workload execution time compared with baselines.