 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASL-Net: Tri-Attention Selective Learning Network for Intelligent Diagnosis of Bimodal Ultrasound Video
Sep 03, 2024In the intelligent diagnosis of bimodal (gray-scale and contrast-enhanced) ultrasound videos, medical domain knowledge such as the way sonographers browse videos, the particular areas they emphasize, and the features they pay special attention to, plays a decisive role in facilitating precise diagnosis. Embedding medical knowledge into the deep learning network can not only enhance performance but also boost clinical confidence and reliability of the network. However, it is an intractable challenge to automatically focus on these person- and disease-specific features in videos and to enable networks to encode bimodal information comprehensively and efficiently. This paper proposes a novel Tri-Attention Selective Learning Network (TASL-Net) to tackle this challenge and automatically embed three types of diagnostic attention of sonographers into a mutual transformer framework for intelligent diagnosis of bimodal ultrasound videos. Firstly, a time-intensity-curve-based video selector is designed to mimic the temporal attention of sonographers, thus removing a large amount of redundant information while improving computational efficiency of TASL-Net. Then, to introduce the spatial attention of the sonographers for contrast-enhanced video analysis, we propose the earliest-enhanced position detector based on structural similarity variation, on which the TASL-Net is made to focus on the differences of perfusion variation inside and outside the lesion. Finally, by proposing a mutual encoding strategy that combines convolution and transformer, TASL-Net possesses bimodal attention to structure features on gray-scale videos and to perfusion variations on contrast-enhanced videos. These modules work collaboratively and contribute to superior performance. We conduct a detailed experimental validation of TASL-Net's performance on three datasets, including lung, breast, and liver.
Towards Multi-modality Fusion and Prototype-based Feature Refinement for Clinically Significant Prostate Cancer Classification in Transrectal Ultrasound
Jun 20, 2024Prostate cancer is a highly prevalent cancer and ranks as the second leading cause of cancer-related deaths in men globally. Recently, the utilization of multi-modality transrectal ultrasound (TRUS) has gained significant traction as a valuable technique for guiding prostate biopsies. In this study, we propose a novel learning framework for clinically significant prostate cancer (csPCa) classification using multi-modality TRUS. The proposed framework employs two separate 3D ResNet-50 to extract distinctive features from B-mode and shear wave elastography (SWE). Additionally, an attention module is incorporated to effectively refine B-mode features and aggregate the extracted features from both modalities. Furthermore, we utilize few shot segmentation task to enhance the capacity of classification encoder. Due to the limited availability of csPCa masks, a prototype correction module is employed to extract representative prototypes of csPCa. The performance of the framework is assessed on a large-scale dataset consisting of 512 TRUS videos with biopsy-proved prostate cancer. The results demonstrate the strong capability in accurately identifying csPCa, achieving an area under the curve (AUC) of 0.86. Moreover, the framework generates visual class activation mapping (CAM), which can serve as valuable assistance for localizing csPCa. These CAM images may offer valuable guidance during TRUS-guided targeted biopsies, enhancing the efficacy of the biopsy procedure.The code is available at https://github.com/2313595986/SmileCode.
Multi-modality transrectal ultrasound video classification for identification of clinically significant prostate cancer
Feb 17, 2024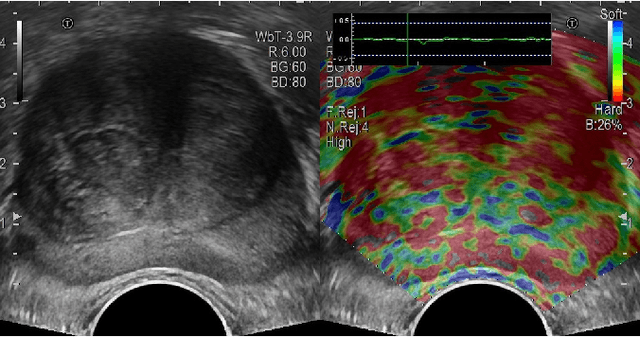

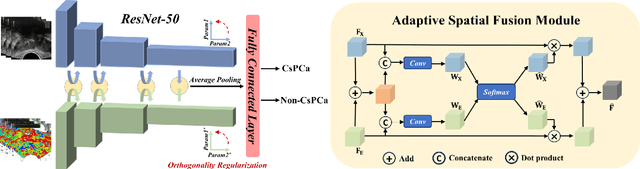
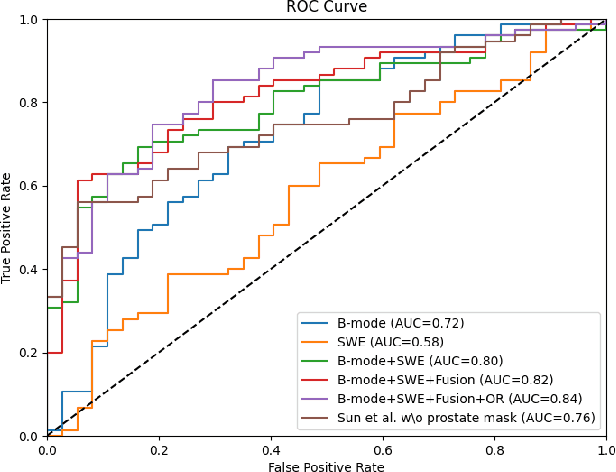
Prostate cancer is the most common noncutaneous cancer in the world. Recently, multi-modality transrectal ultrasound (TRUS) has increasingly become an effective tool for the guidance of prostate biopsies. With the aim of effectively identifying prostate cancer, we propose a framework for the classification of clinically significant prostate cancer (csPCa) from multi-modality TRUS videos. The framework utilizes two 3D ResNet-50 models to extract features from B-mode images and shear wave elastography images, respectively. An adaptive spatial fusion module is introduced to aggregate two modalities' features. An orthogonal regularized loss is further used to mitigate feature redundancy. The proposed framework is evaluated on an in-house dataset containing 512 TRUS videos, and achieves favorable performance in identifying csPCa with an area under curve (AUC) of 0.84. Furthermore, the visualized class activation mapping (CAM) images generated from the proposed framework may provide valuable guidance for the localization of csPCa, thus facilitating the TRUS-guided targeted biopsy. Our code is publicly available at https://github.com/2313595986/ProstateTRUS.
AI-Generated Content Enhanced Computer-Aided Diagnosis Model for Thyroid Nodules: A ChatGPT-Style Assistant
Feb 04, 2024An artificial intelligence-generated content-enhanced computer-aided diagnosis (AIGC-CAD) model, designated as ThyGPT, has been developed. This model, inspired by the architecture of ChatGPT, could assist radiologists in assessing the risk of thyroid nodules through semantic-level human-machine interaction. A dataset comprising 19,165 thyroid nodule ultrasound cases from Zhejiang Cancer Hospital was assembled to facilitate the training and validation of the model. After training, ThyGPT could automatically evaluate thyroid nodule and engage in effective communication with physicians through human-computer interaction. The performance of ThyGPT was rigorously quantified using established metrics such as the receiver operating characteristic (ROC) curve, area under the curve (AUC), sensitivity, and specificity. The empirical findings revealed that radiologists, when supplemented with ThyGPT, markedly surpassed the diagnostic acumen of their peers utilizing traditional methods as well as the performance of the model in isolation. These findings suggest that AIGC-CAD systems, exemplified by ThyGPT, hold the promise to fundamentally transform the diagnostic workflows of radiologists in forthcoming years.