 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASL-Net: Tri-Attention Selective Learning Network for Intelligent Diagnosis of Bimodal Ultrasound Video
Sep 03, 2024In the intelligent diagnosis of bimodal (gray-scale and contrast-enhanced) ultrasound videos, medical domain knowledge such as the way sonographers browse videos, the particular areas they emphasize, and the features they pay special attention to, plays a decisive role in facilitating precise diagnosis. Embedding medical knowledge into the deep learning network can not only enhance performance but also boost clinical confidence and reliability of the network. However, it is an intractable challenge to automatically focus on these person- and disease-specific features in videos and to enable networks to encode bimodal information comprehensively and efficiently. This paper proposes a novel Tri-Attention Selective Learning Network (TASL-Net) to tackle this challenge and automatically embed three types of diagnostic attention of sonographers into a mutual transformer framework for intelligent diagnosis of bimodal ultrasound videos. Firstly, a time-intensity-curve-based video selector is designed to mimic the temporal attention of sonographers, thus removing a large amount of redundant information while improving computational efficiency of TASL-Net. Then, to introduce the spatial attention of the sonographers for contrast-enhanced video analysis, we propose the earliest-enhanced position detector based on structural similarity variation, on which the TASL-Net is made to focus on the differences of perfusion variation inside and outside the lesion. Finally, by proposing a mutual encoding strategy that combines convolution and transformer, TASL-Net possesses bimodal attention to structure features on gray-scale videos and to perfusion variations on contrast-enhanced videos. These modules work collaboratively and contribute to superior performance. We conduct a detailed experimental validation of TASL-Net's performance on three datasets, including lung, breast, and liver.
Thyroid ultrasound diagnosis improvement via multi-view self-supervised learning and two-stage pre-training
Feb 18, 2024Thyroid nodule classification and segmentation in ultrasound images are crucial for computer-aided diagnosis; however, they face limitations owing to insufficient labeled data. In this study, we proposed a multi-view contrastive self-supervised method to improve thyroid nodule classification and segmentation performance with limited manual labels. Our method aligns the transverse and longitudinal views of the same nodule, thereby enabling the model to focus more on the nodule area. We designed an adaptive loss function that eliminates the limitations of the paired data. Additionally, we adopted a two-stage pre-training to exploit the pre-training on ImageNet and thyroid ultrasound images. Extensive experiments were conducted on a large-scale dataset collected from multiple centers. The results showed that the proposed method significantly improves nodule classification and segmentation performance with limited manual labels and outperforms state-of-the-art self-supervised methods. The two-stage pre-training also significantly exceeded ImageNet pre-training.
Automatic nodule identification and differentiation in ultrasound videos to facilitate per-nodule examination
Oct 10, 2023



Ultrasound is a vital diagnostic technique in health screening, with the advantages of non-invasive, cost-effective, and radiation free, and therefore is widely applied in the diagnosis of nodules. However, it relies heavily on the expertise and clinical experience of the sonographer. In ultrasound images, a single nodule might present heterogeneous appearances in different cross-sectional views which makes it hard to perform per-nodule examination. Sonographers usually discriminate different nodules by examining the nodule features and the surrounding structures like gland and duct, which is cumbersome and time-consuming. To address this problem, we collected hundreds of breast ultrasound videos and built a nodule reidentification system that consists of two parts: an extractor based on the deep learning model that can extract feature vectors from the input video clips and a real-time clustering algorithm that automatically groups feature vectors by nodules. The system obtains satisfactory results and exhibits the capability to differentiate ultrasound videos. As far as we know, it's the first attempt to apply re-identification technique in the ultrasonic field.
Multi-Attribute Attention Network for Interpretable Diagnosis of Thyroid Nodules in Ultrasound Images
Jul 09, 2022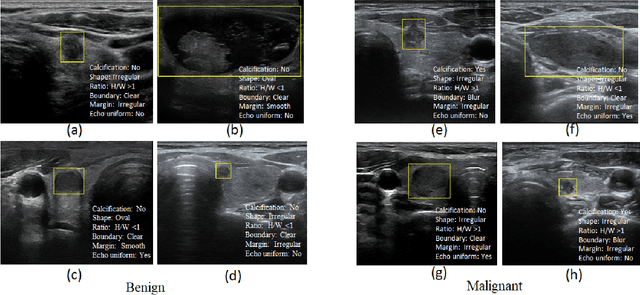
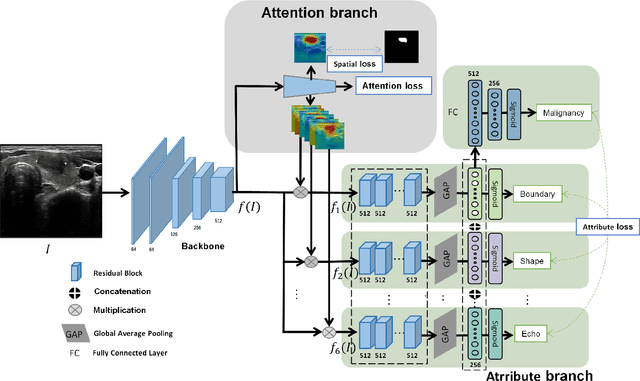
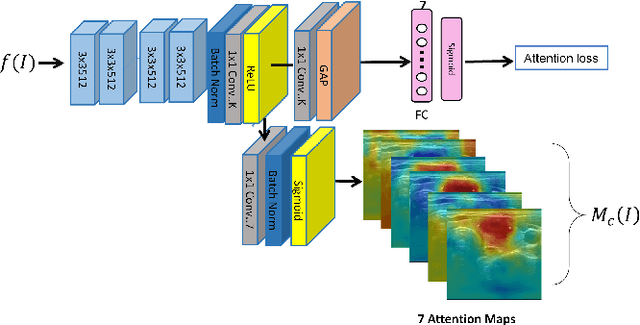
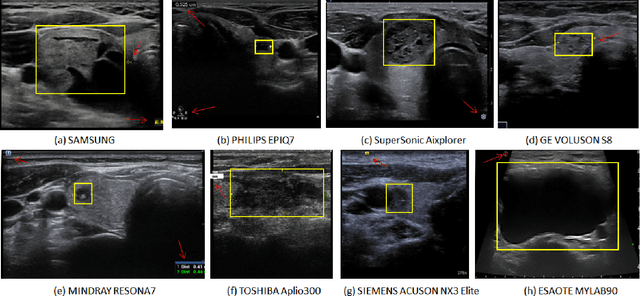
Ultrasound (US) is the primary imaging technique for the diagnosis of thyroid cancer. However, accurate identification of nodule malignancy is a challenging task that can elude less-experienced clinicians. Recently, many computer-aided diagnosis (CAD) systems have been proposed to assist this process. However, most of them do not provide the reasoning of their classification process, which may jeopardize their credibility in practical use. To overcome this, we propose a novel deep learning framework called multi-attribute attention network (MAA-Net) that is designed to mimic the clinical diagnosis process. The proposed model learns to predict nodular attributes and infer their malignancy based on these clinically-relevant features. A multi-attention scheme is adopted to generate customized attention to improve each task and malignancy diagnosis. Furthermore, MAA-Net utilizes nodule delineations as nodules spatial prior guidance for the training rather than cropping the nodules with additional models or human interventions to prevent losing the context information. Validation experiments were performed on a large and challenging dataset containing 4554 patients. Results show that the proposed method outperformed other state-of-the-art methods and provides interpretable predictions that may better suit clinical needs.
Personalized Diagnostic Tool for Thyroid Cancer Classification using Multi-view Ultrasound
Jul 01, 2022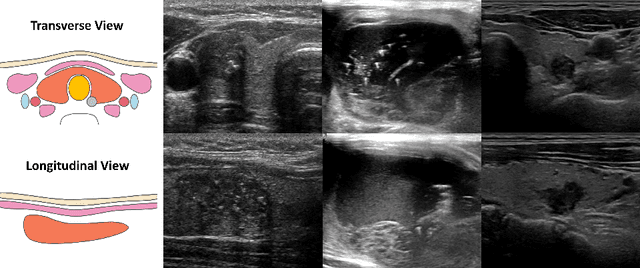
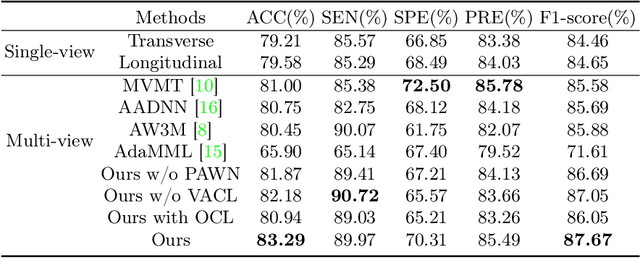
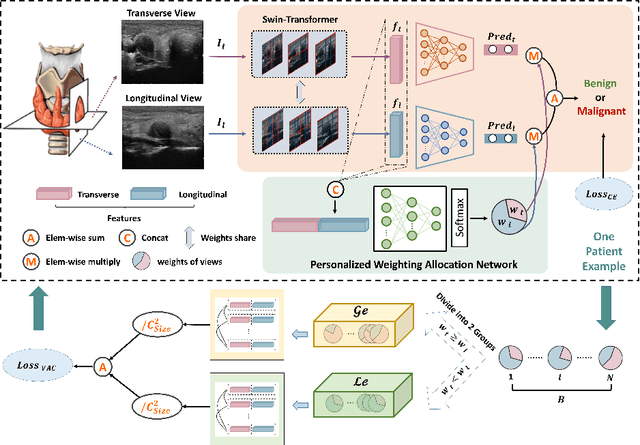
Over the past decades, the incidence of thyroid cancer has been increasing globally. Accurate and early diagnosis allows timely treatment and helps to avoid over-diagnosis. Clinically, a nodule is commonly evaluated from both transverse and longitudinal views using thyroid ultrasound. However, the appearance of the thyroid gland and lesions can vary dramatically across individuals. Identifying key diagnostic information from both views requires specialized expertise. Furthermore, finding an optimal way to integrate multi-view information also relies on the experience of clinicians and adds further difficulty to accurate diagnosis. To address these, we propose a personalized diagnostic tool that can customize its decision-making process for different patients. It consists of a multi-view classification module for feature extraction and a personalized weighting allocation network that generates optimal weighting for different views. It is also equipped with a self-supervised view-aware contrastive loss to further improve the model robustness towards different patient groups. Experimental results show that the proposed framework can better utilize multi-view information and outperform the competing methods.
Flip Learning: Erase to Segment
Aug 02, 2021
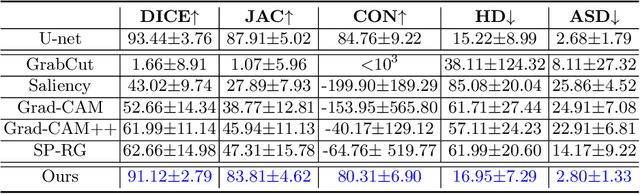
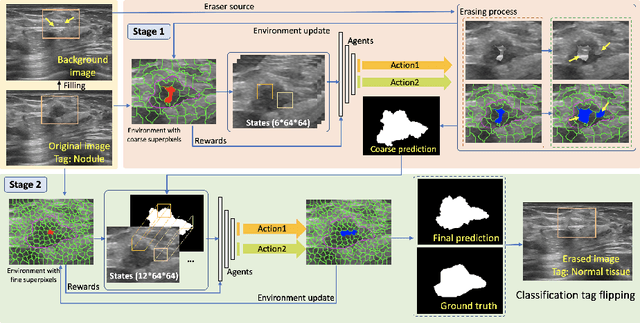
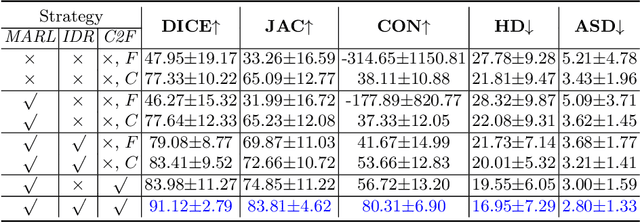
Nodule segmentation from breast ultrasound images is challenging yet essential for the diagnosis. Weakly-supervised segmentation (WSS) can help reduce time-consuming and cumbersome manual annotation. Unlike existing weakly-supervised approaches, in this study, we propose a novel and general WSS framework called Flip Learning, which only needs the box annotation. Specifically, the target in the label box will be erased gradually to flip the classification tag, and the erased region will be considered as the segmentation result finally. Our contribution is three-fold. First, our proposed approach erases on superpixel level using a Multi-agent Reinforcement Learning framework to exploit the prior boundary knowledge and accelerate the learning process. Second, we design two rewards: classification score and intensity distribution reward, to avoid under- and over-segmentation, respectively. Third, we adopt a coarse-to-fine learning strategy to reduce the residual errors and improve the segmentation performance. Extensively validated on a large dataset, our proposed approach achieves competitive performance and shows great potential to narrow the gap between fully-supervised and weakly-supervised learning.