 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Radar Camera Alignment by Contrastive Learning for 3D Object Detection
Apr 23, 2025Recently, 3D object detection algorithms based on radar and camera fusion have shown excellent performance, setting the stage for their application in autonomous driving perception tasks. Existing methods have focused on dealing with feature misalignment caused by the domain gap between radar and camera. However, existing methods either neglect inter-modal features interaction during alignment or fail to effectively align features at the same spatial location across modalities. To alleviate the above problems, we propose a new alignment model called Radar Camera Alignment (RCAlign). Specifically, we design a Dual-Route Alignment (DRA) module based on contrastive learning to align and fuse the features between radar and camera. Moreover, considering the sparsity of radar BEV features, a Radar Feature Enhancement (RFE) module is proposed to improve the densification of radar BEV features with the knowledge distillation loss. Experiments show RCAlign achieves a new state-of-the-art on the public nuScenes benchmark in radar camera fusion for 3D Object Detection. Furthermore, the RCAlign achieves a significant performance gain (4.3\% NDS and 8.4\% mAP) in real-time 3D detection compared to the latest state-of-the-art method (RCBEVDet).
COMET: Towards Partical W4A4KV4 LLMs Serving
Oct 16, 2024



Quantization is a widely-used compression technology to reduce the overhead of serving large language models (LLMs) on terminal devices and in cloud data centers. However, prevalent quantization methods, such as 8-bit weight-activation or 4-bit weight-only quantization, achieve limited performance improvements due to poor support for low-precision (e.g., 4-bit) activation. This work, for the first time, realizes practical W4A4KV4 serving for LLMs, fully utilizing the INT4 tensor cores on modern GPUs and reducing the memory bottleneck caused by the KV cache. Specifically, we propose a novel fine-grained mixed-precision quantization algorithm (FMPQ) that compresses most activations into 4-bit with negligible accuracy loss. To support mixed-precision matrix multiplication for W4A4 and W4A8, we develop a highly optimized W4Ax kernel. Our approach introduces a novel mixed-precision data layout to facilitate access and fast dequantization for activation and weight tensors, utilizing the GPU's software pipeline to hide the overhead of data loading and conversion. Additionally, we propose fine-grained streaming multiprocessor (SM) scheduling to achieve load balance across different SMs. We integrate the optimized W4Ax kernel into our inference framework, COMET, and provide efficient management to support popular LLMs such as LLaMA-3-70B. Extensive evaluations demonstrate that, when running LLaMA family models on a single A100-80G-SMX4, COMET achieves a kernel-level speedup of \textbf{$2.88\times$} over cuBLAS and a \textbf{$2.02 \times$} throughput improvement compared to TensorRT-LLM from an end-to-end framework perspective.
Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism
Aug 20, 2024



Pre-trained language models (PLMs) are engineered to be robust in contextual understanding and exhibit outstanding performance in various natural language processing tasks. However, their considerable size incurs significant computational and storage costs. Modern pruning strategies employ one-shot techniques to compress PLMs without the need for retraining on task-specific or otherwise general data; however, these approaches often lead to an indispensable reduction in performance. In this paper, we propose SDS, a Sparse-Dense-Sparse pruning framework to enhance the performance of the pruned PLMs from a weight distribution optimization perspective. We outline the pruning process in three steps. Initially, we prune less critical connections in the model using conventional one-shot pruning methods. Next, we reconstruct a dense model featuring a pruning-friendly weight distribution by reactivating pruned connections with sparse regularization. Finally, we perform a second pruning round, yielding a superior pruned model compared to the initial pruning. Experimental results demonstrate that SDS outperforms the state-of-the-art pruning techniques SparseGPT and Wanda under an identical sparsity configuration. For instance, SDS reduces perplexity by 9.13 on Raw-Wikitext2 and improves accuracy by an average of 2.05% across multiple zero-shot benchmarks for OPT-125M with 2:4 sparsity.
Mitral Regurgitation Recogniton based on Unsupervised Out-of-Distribution Detection with Residual Diffusion Amplification
Jul 31, 2024



Mitral regurgitation (MR) is a serious heart valve disease. Early and accurate diagnosis of MR via ultrasound video is critical for timely clinical decision-making and surgical intervention. However, manual MR diagnosis heavily relies on the operator's experience, which may cause misdiagnosis and inter-observer variability. Since MR data is limited and has large intra-class variability, we propose an unsupervised out-of-distribution (OOD) detection method to identify MR rather than building a deep classifier. To our knowledge, we are the first to explore OOD in MR ultrasound videos. Our method consists of a feature extractor, a feature reconstruction model, and a residual accumulation amplification algorithm. The feature extractor obtains features from the video clips and feeds them into the feature reconstruction model to restore the original features. The residual accumulation amplification algorithm then iteratively performs noise feature reconstruction, amplifying the reconstructed error of OOD features. This algorithm is straightforward yet efficient and can seamlessly integrate as a plug-and-play component in reconstruction-based OOD detection methods. We validated the proposed method on a large ultrasound dataset containing 893 non-MR and 267 MR videos. Experimental results show that our OOD detection method can effectively identify MR samples.
Fine-grained Context and Multi-modal Alignment for Freehand 3D Ultrasound Reconstruction
Jul 05, 2024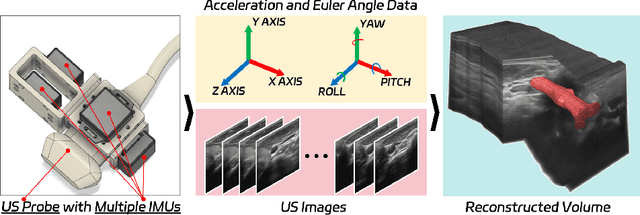


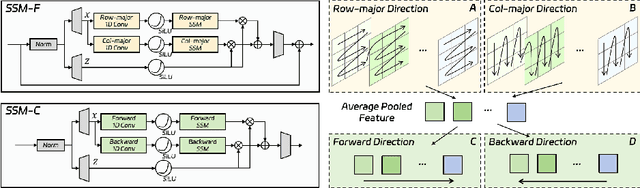
Fine-grained spatio-temporal learning is crucial for freehand 3D ultrasound reconstruction. Previous works mainly resorted to the coarse-grained spatial features and the separated temporal dependency learning and struggles for fine-grained spatio-temporal learning. Mining spatio-temporal information in fine-grained scales is extremely challenging due to learning difficulties in long-range dependencies. In this context, we propose a novel method to exploit the long-range dependency management capabilities of the state space model (SSM) to address the above challenge. Our contribution is three-fold. First, we propose ReMamba, which mines multi-scale spatio-temporal information by devising a multi-directional SSM. Second, we propose an adaptive fusion strategy that introduces multiple inertial measurement units as auxiliary temporal information to enhance spatio-temporal perception. Last, we design an online alignment strategy that encodes the temporal information as pseudo labels for multi-modal alignment to further improve reconstruction performance. Extensive experimental validations on two large-scale datasets show remarkable improvement from our method over competitors.
Thyroid ultrasound diagnosis improvement via multi-view self-supervised learning and two-stage pre-training
Feb 18, 2024Thyroid nodule classification and segmentation in ultrasound images are crucial for computer-aided diagnosis; however, they face limitations owing to insufficient labeled data. In this study, we proposed a multi-view contrastive self-supervised method to improve thyroid nodule classification and segmentation performance with limited manual labels. Our method aligns the transverse and longitudinal views of the same nodule, thereby enabling the model to focus more on the nodule area. We designed an adaptive loss function that eliminates the limitations of the paired data. Additionally, we adopted a two-stage pre-training to exploit the pre-training on ImageNet and thyroid ultrasound images. Extensive experiments were conducted on a large-scale dataset collected from multiple centers. The results showed that the proposed method significantly improves nodule classification and segmentation performance with limited manual labels and outperforms state-of-the-art self-supervised methods. The two-stage pre-training also significantly exceeded ImageNet pre-training.
GarchingSim: An Autonomous Driving Simulator with Photorealistic Scenes and Minimalist Workflow
Jan 30, 2024



Conducting real road testing for autonomous driving algorithms can be expensive and sometimes impractical, particularly for small startups and research institutes. Thus, simulation becomes an important method for evaluating these algorithms. However, the availability of free and open-source simulators is limited, and the installation and configuration process can be daunting for beginners and interdisciplinary researchers. We introduce an autonomous driving simulator with photorealistic scenes, meanwhile keeping a user-friendly workflow. The simulator is able to communicate with external algorithms through ROS2 or Socket.IO, making it compatible with existing software stacks. Furthermore, we implement a highly accurate vehicle dynamics model within the simulator to enhance the realism of the vehicle's physical effects. The simulator is able to serve various functions, including generating synthetic data and driving with machine learning-based algorithms. Moreover, we prioritize simplicity in the deployment process, ensuring that beginners find it approachable and user-friendly.
A Foundation Model for General Moving Object Segmentation in Medical Images
Oct 04, 2023



Medical image segmentation aims to delineate the anatomical or pathological structures of interest, playing a crucial role in clinical diagnosis. A substantial amount of high-quality annotated data is crucial for constructing high-precision deep segmentation models. However, medical annotation is highly cumbersome and time-consuming, especially for medical videos or 3D volumes, due to the huge labeling space and poor inter-frame consistency. Recently, a fundamental task named Moving Object Segmentation (MOS) has made significant advancements in natural images. Its objective is to delineate moving objects from the background within image sequences, requiring only minimal annotations. In this paper, we propose the first foundation model, named iMOS, for MOS in medical images. Extensive experiments on a large multi-modal medical dataset validate the effectiveness of the proposed iMOS. Specifically, with the annotation of only a small number of images in the sequence, iMOS can achieve satisfactory tracking and segmentation performance of moving objects throughout the entire sequence in bi-directions. We hope that the proposed iMOS can help accelerate the annotation speed of experts, and boost the development of medical foundation models.
OnUVS: Online Feature Decoupling Framework for High-Fidelity Ultrasound Video Synthesis
Aug 16, 2023



Ultrasound (US) imaging is indispensable in clinical practice. To diagnose certain diseases, sonographers must observe corresponding dynamic anatomic structures to gather comprehensive information. However, the limited availability of specific US video cases causes teaching difficulties in identifying corresponding diseases, which potentially impacts the detection rate of such cases. The synthesis of US videos may represent a promising solution to this issue. Nevertheless, it is challenging to accurately animate the intricate motion of dynamic anatomic structures while preserving image fidelity. To address this, we present a novel online feature-decoupling framework called OnUVS for high-fidelity US video synthesis. Our highlights can be summarized by four aspects. First, we introduced anatomic information into keypoint learning through a weakly-supervised training strategy, resulting in improved preservation of anatomical integrity and motion while minimizing the labeling burden. Second, to better preserve the integrity and textural information of US images, we implemented a dual-decoder that decouples the content and textural features in the generator. Third, we adopted a multiple-feature discriminator to extract a comprehensive range of visual cues, thereby enhancing the sharpness and fine details of the generated videos. Fourth, we constrained the motion trajectories of keypoints during online learning to enhance the fluidity of generated videos. Our validation and user studies on in-house echocardiographic and pelvic floor US videos showed that OnUVS synthesizes US videos with high fidelity.
Instructive Feature Enhancement for Dichotomous Medical Image Segmentation
Jun 06, 2023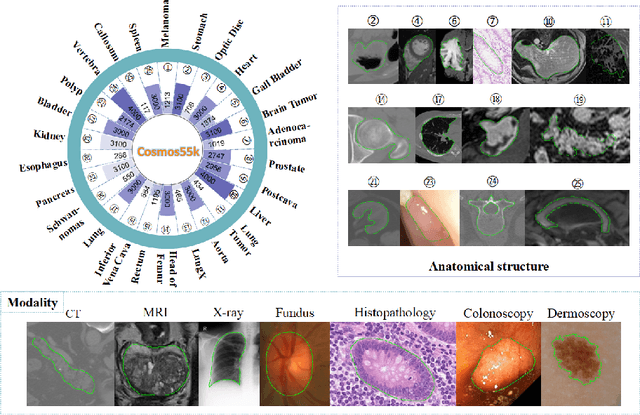

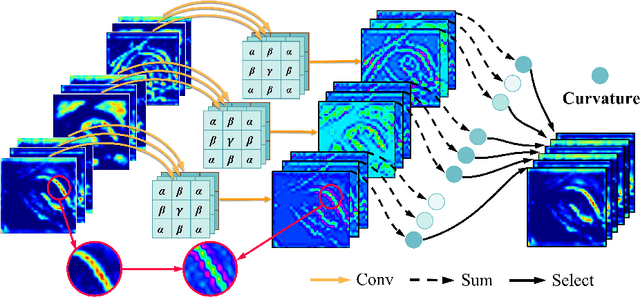
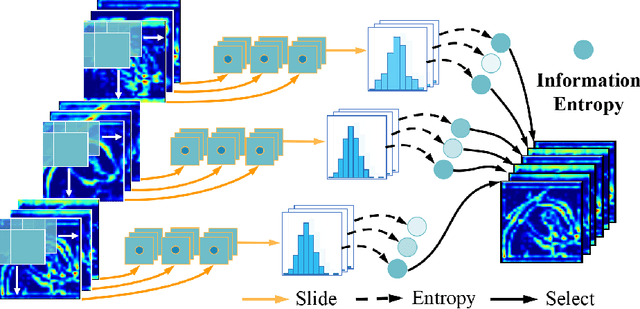
Deep neural networks have been widely applied in dichotomous medical image segmentation (DMIS) of many anatomical structures in several modalities, achieving promising performance. However, existing networks tend to struggle with task-specific, heavy and complex designs to improve accuracy. They made little instructions to which feature channels would be more beneficial for segmentation, and that may be why the performance and universality of these segmentation models are hindered. In this study, we propose an instructive feature enhancement approach, namely IFE, to adaptively select feature channels with rich texture cues and strong discriminability to enhance raw features based on local curvature or global information entropy criteria. Being plug-and-play and applicable for diverse DMIS tasks, IFE encourages the model to focus on texture-rich features which are especially important for the ambiguous and challenging boundary identification, simultaneously achieving simplicity, universality, and certain interpretability. To evaluate the proposed IFE, we constructed the first large-scale DMIS dataset Cosmos55k, which contains 55,023 images from 7 modalities and 26 anatomical structures. Extensive experiments show that IFE can improve the performance of classic segmentation networks across different anatomies and modalities with only slight modifications. Code is available at https://github.com/yezi-66/IFE