 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable and Controllable Motion Curve Guided Cardiac Ultrasound Video Generation
Jul 31, 2024Echocardiography video is a primary modality for diagnosing heart diseases, but the limited data poses challenges for both clinical teaching and machine learning training. Recently, video generative models have emerged as a promising strategy to alleviate this issue. However, previous methods often relied on holistic conditions during generation, hindering the flexible movement control over specific cardiac structures. In this context, we propose an explainable and controllable method for echocardiography video generation, taking an initial frame and a motion curve as guidance. Our contributions are three-fold. First, we extract motion information from each heart substructure to construct motion curves, enabling the diffusion model to synthesize customized echocardiography videos by modifying these curves. Second, we propose the structure-to-motion alignment module, which can map semantic features onto motion curves across cardiac structures. Third, The position-aware attention mechanism is designed to enhance video consistency utilizing Gaussian masks with structural position information. Extensive experiments on three echocardiography datasets show that our method outperforms others regarding fidelity and consistency. The full code will be released at https://github.com/mlmi-2024-72/ECM.
Fine-grained Context and Multi-modal Alignment for Freehand 3D Ultrasound Reconstruction
Jul 05, 2024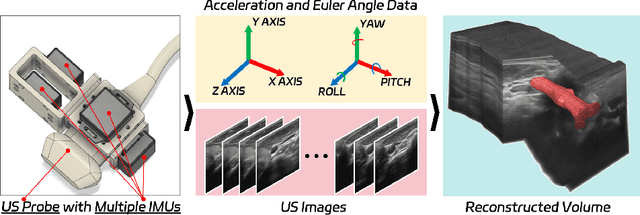


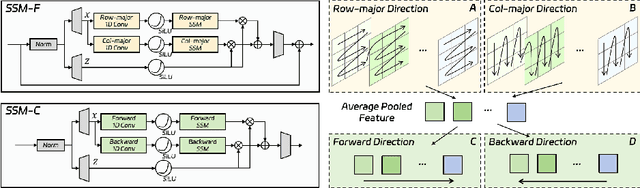
Fine-grained spatio-temporal learning is crucial for freehand 3D ultrasound reconstruction. Previous works mainly resorted to the coarse-grained spatial features and the separated temporal dependency learning and struggles for fine-grained spatio-temporal learning. Mining spatio-temporal information in fine-grained scales is extremely challenging due to learning difficulties in long-range dependencies. In this context, we propose a novel method to exploit the long-range dependency management capabilities of the state space model (SSM) to address the above challenge. Our contribution is three-fold. First, we propose ReMamba, which mines multi-scale spatio-temporal information by devising a multi-directional SSM. Second, we propose an adaptive fusion strategy that introduces multiple inertial measurement units as auxiliary temporal information to enhance spatio-temporal perception. Last, we design an online alignment strategy that encodes the temporal information as pseudo labels for multi-modal alignment to further improve reconstruction performance. Extensive experimental validations on two large-scale datasets show remarkable improvement from our method over competitors.
Thyroid ultrasound diagnosis improvement via multi-view self-supervised learning and two-stage pre-training
Feb 18, 2024Thyroid nodule classification and segmentation in ultrasound images are crucial for computer-aided diagnosis; however, they face limitations owing to insufficient labeled data. In this study, we proposed a multi-view contrastive self-supervised method to improve thyroid nodule classification and segmentation performance with limited manual labels. Our method aligns the transverse and longitudinal views of the same nodule, thereby enabling the model to focus more on the nodule area. We designed an adaptive loss function that eliminates the limitations of the paired data. Additionally, we adopted a two-stage pre-training to exploit the pre-training on ImageNet and thyroid ultrasound images. Extensive experiments were conducted on a large-scale dataset collected from multiple centers. The results showed that the proposed method significantly improves nodule classification and segmentation performance with limited manual labels and outperforms state-of-the-art self-supervised methods. The two-stage pre-training also significantly exceeded ImageNet pre-training.
FFPN: Fourier Feature Pyramid Network for Ultrasound Image Segmentation
Aug 26, 2023
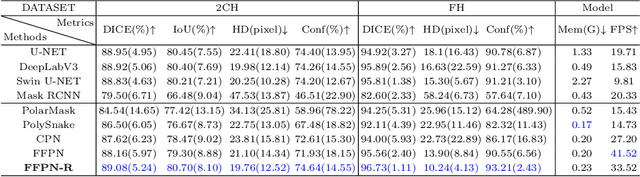
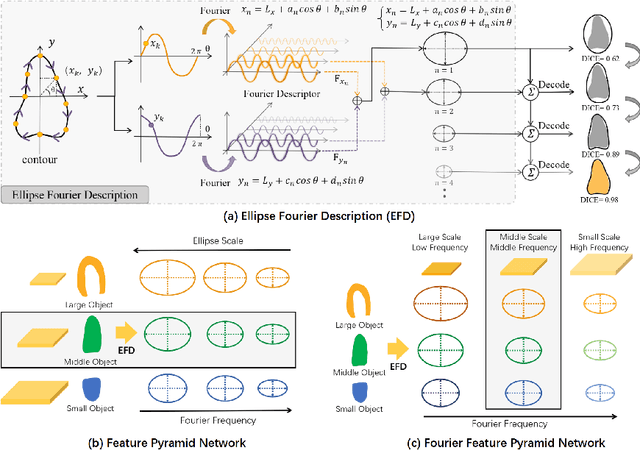
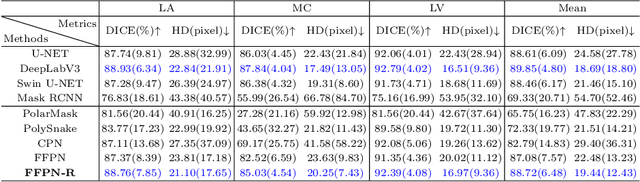
Ultrasound (US) image segmentation is an active research area that requires real-time and highly accurate analysis in many scenarios. The detect-to-segment (DTS) frameworks have been recently proposed to balance accuracy and efficiency. However, existing approaches may suffer from inadequate contour encoding or fail to effectively leverage the encoded results. In this paper, we introduce a novel Fourier-anchor-based DTS framework called Fourier Feature Pyramid Network (FFPN) to address the aforementioned issues. The contributions of this paper are two fold. First, the FFPN utilizes Fourier Descriptors to adequately encode contours. Specifically, it maps Fourier series with similar amplitudes and frequencies into the same layer of the feature map, thereby effectively utilizing the encoded Fourier information. Second, we propose a Contour Sampling Refinement (CSR) module based on the contour proposals and refined features produced by the FFPN. This module extracts rich features around the predicted contours to further capture detailed information and refine the contours. Extensive experimental results on three large and challenging datasets demonstrate that our method outperforms other DTS methods in terms of accuracy and efficiency. Furthermore, our framework can generalize well to other detection or segmentation tasks.
OnUVS: Online Feature Decoupling Framework for High-Fidelity Ultrasound Video Synthesis
Aug 16, 2023



Ultrasound (US) imaging is indispensable in clinical practice. To diagnose certain diseases, sonographers must observe corresponding dynamic anatomic structures to gather comprehensive information. However, the limited availability of specific US video cases causes teaching difficulties in identifying corresponding diseases, which potentially impacts the detection rate of such cases. The synthesis of US videos may represent a promising solution to this issue. Nevertheless, it is challenging to accurately animate the intricate motion of dynamic anatomic structures while preserving image fidelity. To address this, we present a novel online feature-decoupling framework called OnUVS for high-fidelity US video synthesis. Our highlights can be summarized by four aspects. First, we introduced anatomic information into keypoint learning through a weakly-supervised training strategy, resulting in improved preservation of anatomical integrity and motion while minimizing the labeling burden. Second, to better preserve the integrity and textural information of US images, we implemented a dual-decoder that decouples the content and textural features in the generator. Third, we adopted a multiple-feature discriminator to extract a comprehensive range of visual cues, thereby enhancing the sharpness and fine details of the generated videos. Fourth, we constrained the motion trajectories of keypoints during online learning to enhance the fluidity of generated videos. Our validation and user studies on in-house echocardiographic and pelvic floor US videos showed that OnUVS synthesizes US videos with high fidelity.
Segment Anything Model for Medical Images?
May 01, 2023



The Segment Anything Model (SAM) is the first foundation model for general image segmentation. It designed a novel promotable segmentation task, ensuring zero-shot image segmentation using the pre-trained model via two main modes including automatic everything and manual prompt. SAM has achieved impressive results on various natural image segmentation tasks. However, medical image segmentation (MIS) is more challenging due to the complex modalities, fine anatomical structures, uncertain and complex object boundaries, and wide-range object scales. Meanwhile, zero-shot and efficient MIS can well reduce the annotation time and boost the development of medical image analysis. Hence, SAM seems to be a potential tool and its performance on large medical datasets should be further validated. We collected and sorted 52 open-source datasets, and built a large medical segmentation dataset with 16 modalities, 68 objects, and 553K slices. We conducted a comprehensive analysis of different SAM testing strategies on the so-called COSMOS 553K dataset. Extensive experiments validate that SAM performs better with manual hints like points and boxes for object perception in medical images, leading to better performance in prompt mode compared to everything mode. Additionally, SAM shows remarkable performance in some specific objects and modalities, but is imperfect or even totally fails in other situations. Finally, we analyze the influence of different factors (e.g., the Fourier-based boundary complexity and size of the segmented objects) on SAM's segmentation performance. Extensive experiments validate that SAM's zero-shot segmentation capability is not sufficient to ensure its direct application to the MIS.