 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnUVS: Online Feature Decoupling Framework for High-Fidelity Ultrasound Video Synthesis
Aug 16, 2023



Ultrasound (US) imaging is indispensable in clinical practice. To diagnose certain diseases, sonographers must observe corresponding dynamic anatomic structures to gather comprehensive information. However, the limited availability of specific US video cases causes teaching difficulties in identifying corresponding diseases, which potentially impacts the detection rate of such cases. The synthesis of US videos may represent a promising solution to this issue. Nevertheless, it is challenging to accurately animate the intricate motion of dynamic anatomic structures while preserving image fidelity. To address this, we present a novel online feature-decoupling framework called OnUVS for high-fidelity US video synthesis. Our highlights can be summarized by four aspects. First, we introduced anatomic information into keypoint learning through a weakly-supervised training strategy, resulting in improved preservation of anatomical integrity and motion while minimizing the labeling burden. Second, to better preserve the integrity and textural information of US images, we implemented a dual-decoder that decouples the content and textural features in the generator. Third, we adopted a multiple-feature discriminator to extract a comprehensive range of visual cues, thereby enhancing the sharpness and fine details of the generated videos. Fourth, we constrained the motion trajectories of keypoints during online learning to enhance the fluidity of generated videos. Our validation and user studies on in-house echocardiographic and pelvic floor US videos showed that OnUVS synthesizes US videos with high fidelity.
Online Reflective Learning for Robust Medical Image Segmentation
Jul 01, 2022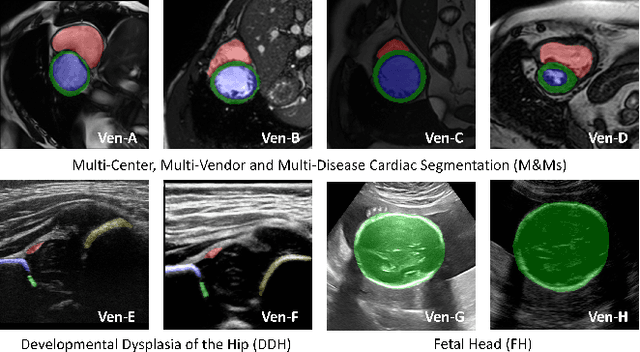
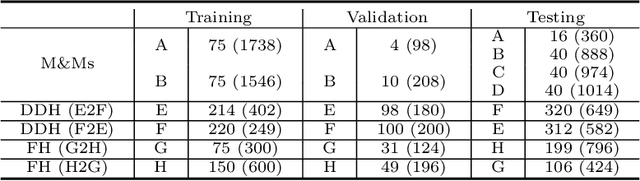
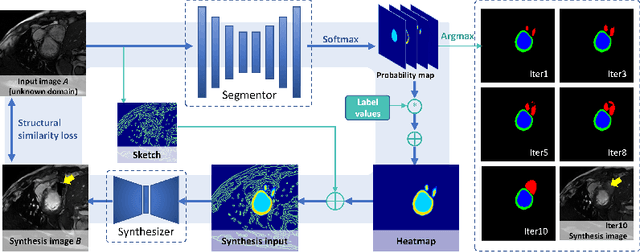
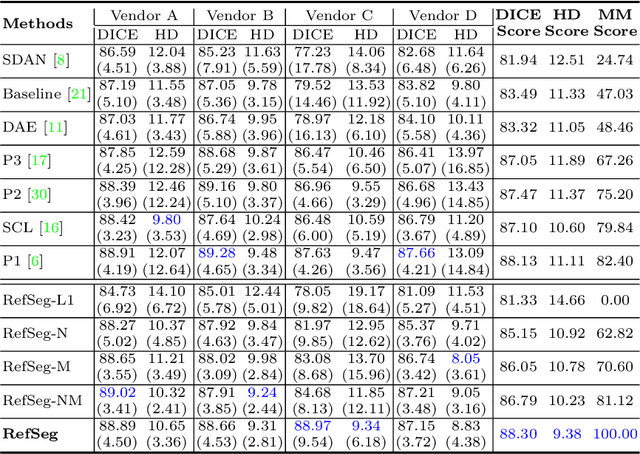
Deep segmentation models often face the failure risks when the testing image presents unseen distributions. Improving model robustness against these risks is crucial for the large-scale clinical application of deep models. In this study, inspired by human learning cycle, we propose a novel online reflective learning framework (RefSeg) to improve segmentation robustness. Based on the reflection-on-action conception, our RefSeg firstly drives the deep model to take action to obtain semantic segmentation. Then, RefSeg triggers the model to reflect itself. Because making deep models realize their segmentation failures during testing is challenging, RefSeg synthesizes a realistic proxy image from the semantic mask to help deep models build intuitive and effective reflections. This proxy translates and emphasizes the segmentation flaws. By maximizing the structural similarity between the raw input and the proxy, the reflection-on-action loop is closed with segmentation robustness improved. RefSeg runs in the testing phase and is general for segmentation models. Extensive validation on three medical image segmentation tasks with a public cardiac MR dataset and two in-house large ultrasound datasets show that our RefSeg remarkably improves model robustness and reports state-of-the-art performance over strong competitors.
Weakly-supervised High-fidelity Ultrasound Video Synthesis with Feature Decoupling
Jul 01, 2022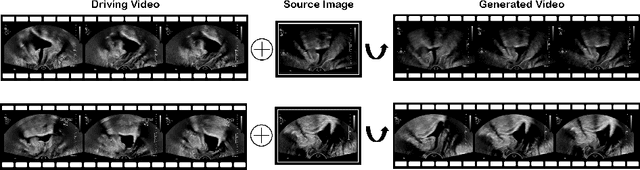
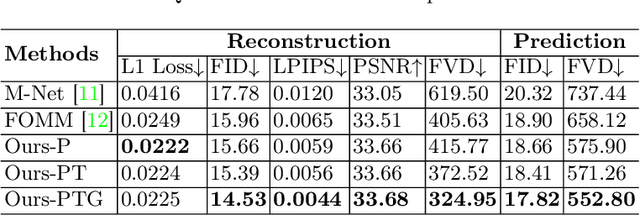
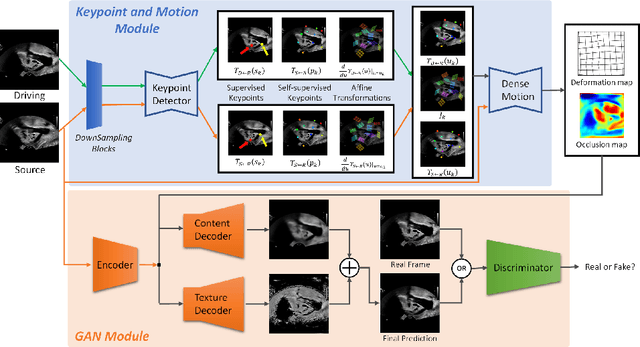

Ultrasound (US) is widely used for its advantages of real-time imaging, radiation-free and portability. In clinical practice, analysis and diagnosis often rely on US sequences rather than a single image to obtain dynamic anatomical information. This is challenging for novices to learn because practicing with adequate videos from patients is clinically unpractical. In this paper, we propose a novel framework to synthesize high-fidelity US videos. Specifically, the synthesis videos are generated by animating source content images based on the motion of given driving videos. Our highlights are three-fold. First, leveraging the advantages of self- and fully-supervised learning, our proposed system is trained in weakly-supervised manner for keypoint detection. These keypoints then provide vital information for handling complex high dynamic motions in US videos. Second, we decouple content and texture learning using the dual decoders to effectively reduce the model learning difficulty. Last, we adopt the adversarial training strategy with GAN losses for further improving the sharpness of the generated videos, narrowing the gap between real and synthesis videos. We validate our method on a large in-house pelvic dataset with high dynamic motion. Extensive evaluation metrics and user study prove the effectiveness of our proposed method.
Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
Apr 19, 2022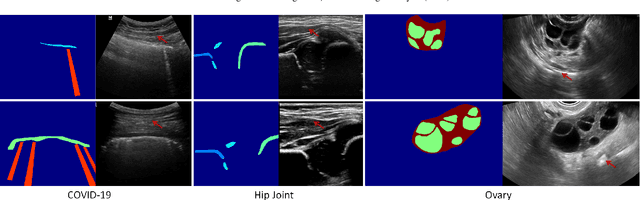
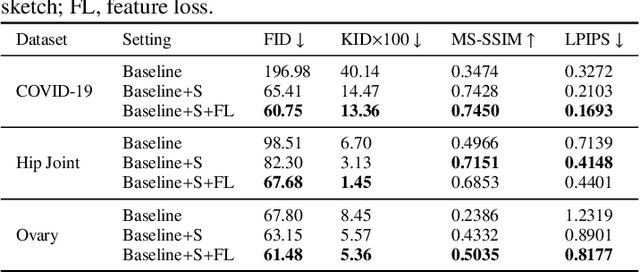
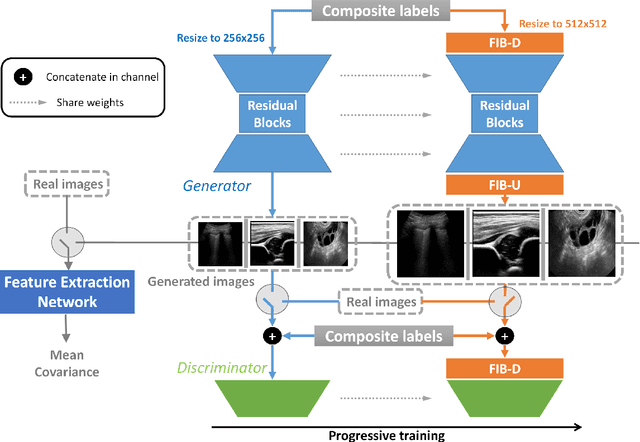

Ultrasound (US) imaging is widely used for anatomical structure inspection in clinical diagnosis. The training of new sonographers and deep learning based algorithms for US image analysis usually requires a large amount of data. However, obtaining and labeling large-scale US imaging data are not easy tasks, especially for diseases with low incidence. Realistic US image synthesis can alleviate this problem to a great extent. In this paper, we propose a generative adversarial network (GAN) based image synthesis framework. Our main contributions include: 1) we present the first work that can synthesize realistic B-mode US images with high-resolution and customized texture editing features; 2) to enhance structural details of generated images, we propose to introduce auxiliary sketch guidance into a conditional GAN. We superpose the edge sketch onto the object mask and use the composite mask as the network input; 3) to generate high-resolution US images, we adopt a progressive training strategy to gradually generate high-resolution images from low-resolution images. In addition, a feature loss is proposed to minimize the difference of high-level features between the generated and real images, which further improves the quality of generated images; 4) the proposed US image synthesis method is quite universal and can also be generalized to the US images of other anatomical structures besides the three ones tested in our study (lung, hip joint, and ovary); 5) extensive experiments on three large US image datasets are conducted to validate our method. Ablation studies, customized texture editing, user studies, and segmentation tests demonstrate promising results of our method in synthesizing realistic US images.
Contrastive Rendering for Ultrasound Image Segmentation
Oct 10, 2020
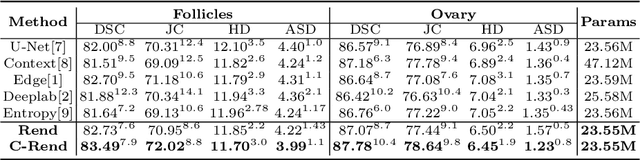
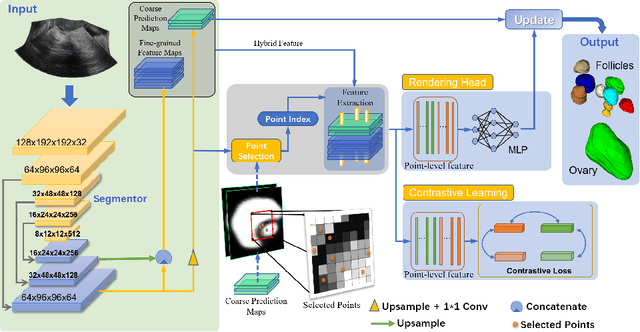
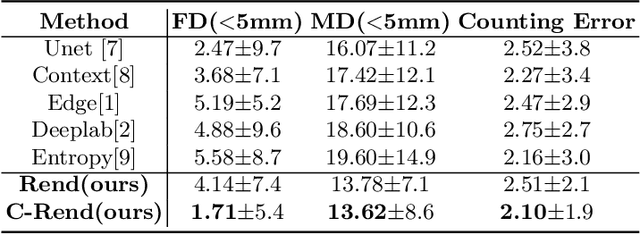
Ultrasound (US) image segmentation embraced its significant improvement in deep learning era. However, the lack of sharp boundaries in US images still remains an inherent challenge for segmentation. Previous methods often resort to global context, multi-scale cues or auxiliary guidance to estimate the boundaries. It is hard for these methods to approach pixel-level learning for fine-grained boundary generating. In this paper, we propose a novel and effective framework to improve boundary estimation in US images. Our work has three highlights. First, we propose to formulate the boundary estimation as a rendering task, which can recognize ambiguous points (pixels/voxels) and calibrate the boundary prediction via enriched feature representation learning. Second, we introduce point-wise contrastive learning to enhance the similarity of points from the same class and contrastively decrease the similarity of points from different classes. Boundary ambiguities are therefore further addressed. Third, both rendering and contrastive learning tasks contribute to consistent improvement while reducing network parameters. As a proof-of-concept, we performed validation experiments on a challenging dataset of 86 ovarian US volumes. Results show that our proposed method outperforms state-of-the-art methods and has the potential to be used in clinical practice.
Synthesis and Edition of Ultrasound Images via Sketch Guided Progressive Growing GANs
Apr 01, 2020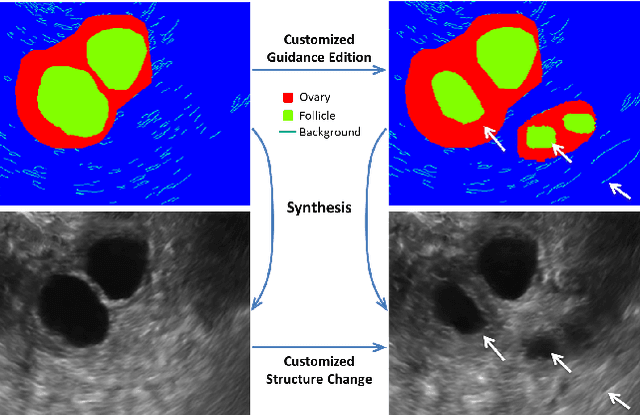
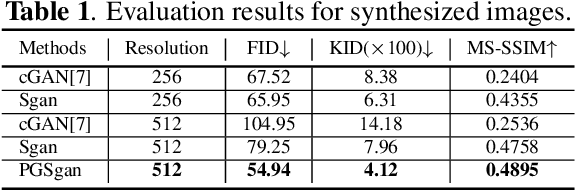
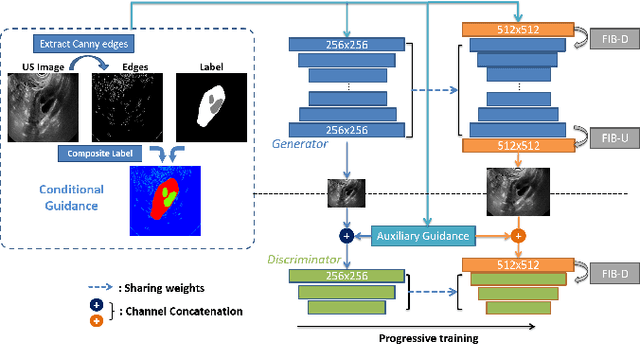
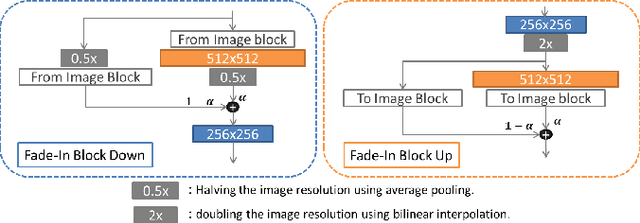
Ultrasound (US) is widely accepted in clinic for anatomical structure inspection. However, lacking in resources to practice US scan, novices often struggle to learn the operation skills. Also, in the deep learning era, automated US image analysis is limited by the lack of annotated samples. Efficiently synthesizing realistic, editable and high resolution US images can solve the problems. The task is challenging and previous methods can only partially complete it. In this paper, we devise a new framework for US image synthesis. Particularly, we firstly adopt a sketch generative adversarial networks (Sgan) to introduce background sketch upon object mask in a conditioned generative adversarial network. With enriched sketch cues, Sgan can generate realistic US images with editable and fine-grained structure details. Although effective, Sgan is hard to generate high resolution US images. To achieve this, we further implant the Sgan into a progressive growing scheme (PGSgan). By smoothly growing both generator and discriminator, PGSgan can gradually synthesize US images from low to high resolution. By synthesizing ovary and follicle US images, our extensive perceptual evaluation, user study and segmentation results prove the promising efficacy and efficiency of the proposed PGSgan.