 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Test-time Adaptation with Multi-level Consistency for Robust Classification
Jun 05, 2023



Deep classifiers may encounter significant performance degradation when processing unseen testing data from varying centers, vendors, and protocols. Ensuring the robustness of deep models against these domain shifts is crucial for their widespread clinical application. In this study, we propose a novel approach called Fourier Test-time Adaptation (FTTA), which employs a dual-adaptation design to integrate input and model tuning, thereby jointly improving the model robustness. The main idea of FTTA is to build a reliable multi-level consistency measurement of paired inputs for achieving self-correction of prediction. Our contribution is two-fold. First, we encourage consistency in global features and local attention maps between the two transformed images of the same input. Here, the transformation refers to Fourier-based input adaptation, which can transfer one unseen image into source style to reduce the domain gap. Furthermore, we leverage style-interpolated images to enhance the global and local features with learnable parameters, which can smooth the consistency measurement and accelerate convergence. Second, we introduce a regularization technique that utilizes style interpolation consistency in the frequency space to encourage self-consistency in the logit space of the model output. This regularization provides strong self-supervised signals for robustness enhancement. FTTA was extensively validated on three large classification datasets with different modalities and organs. Experimental results show that FTTA is general and outperforms other strong state-of-the-art methods.
Online Reflective Learning for Robust Medical Image Segmentation
Jul 01, 2022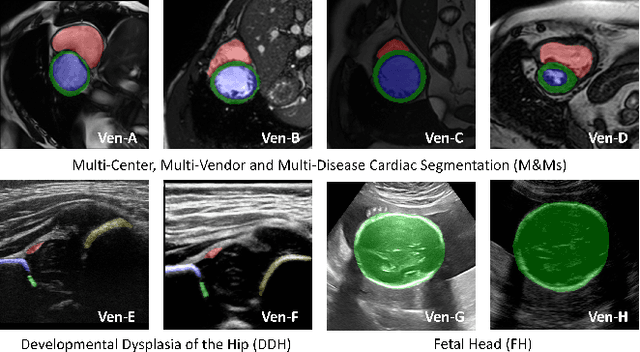
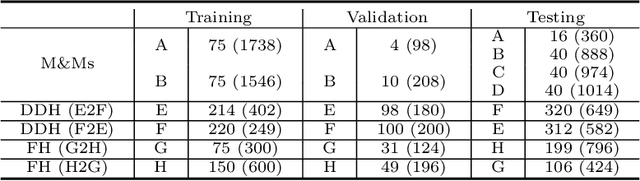
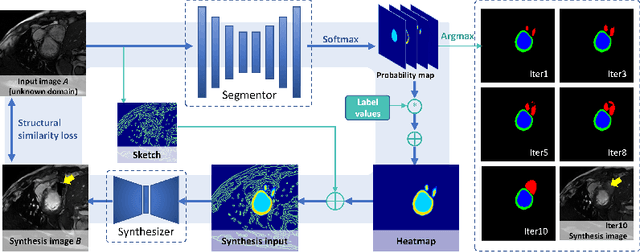
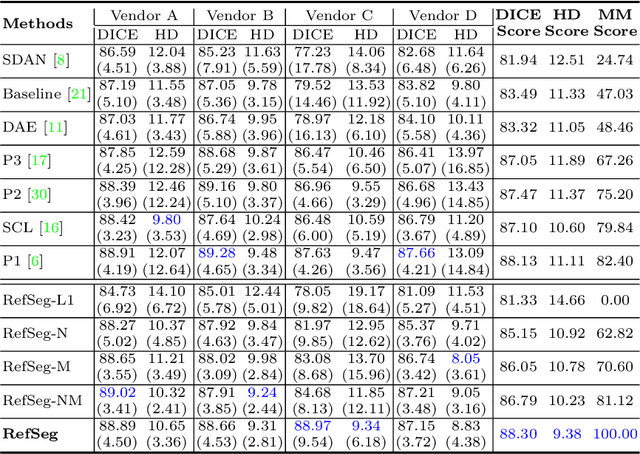
Deep segmentation models often face the failure risks when the testing image presents unseen distributions. Improving model robustness against these risks is crucial for the large-scale clinical application of deep models. In this study, inspired by human learning cycle, we propose a novel online reflective learning framework (RefSeg) to improve segmentation robustness. Based on the reflection-on-action conception, our RefSeg firstly drives the deep model to take action to obtain semantic segmentation. Then, RefSeg triggers the model to reflect itself. Because making deep models realize their segmentation failures during testing is challenging, RefSeg synthesizes a realistic proxy image from the semantic mask to help deep models build intuitive and effective reflections. This proxy translates and emphasizes the segmentation flaws. By maximizing the structural similarity between the raw input and the proxy, the reflection-on-action loop is closed with segmentation robustness improved. RefSeg runs in the testing phase and is general for segmentation models. Extensive validation on three medical image segmentation tasks with a public cardiac MR dataset and two in-house large ultrasound datasets show that our RefSeg remarkably improves model robustness and reports state-of-the-art performance over strong competitors.
Self Context and Shape Prior for Sensorless Freehand 3D Ultrasound Reconstruction
Aug 18, 2021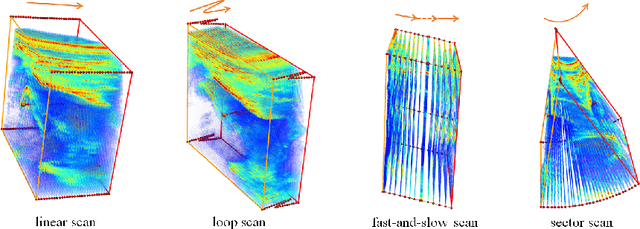

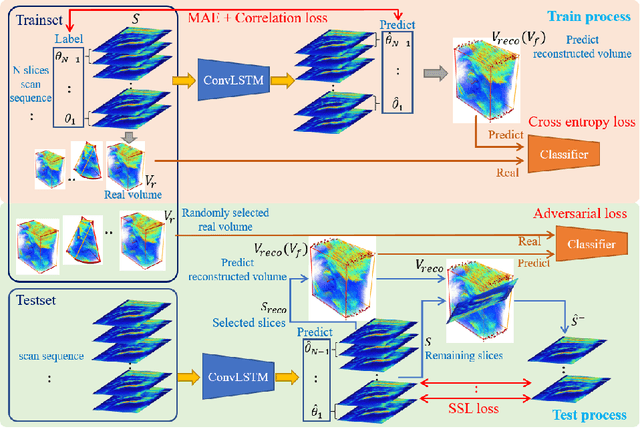
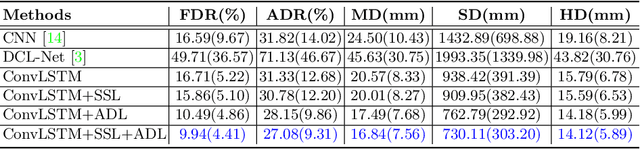
3D ultrasound (US) is widely used for its rich diagnostic information. However, it is criticized for its limited field of view. 3D freehand US reconstruction is promising in addressing the problem by providing broad range and freeform scan. The existing deep learning based methods only focus on the basic cases of skill sequences, and the model relies on the training data heavily. The sequences in real clinical practice are a mix of diverse skills and have complex scanning paths. Besides, deep models should adapt themselves to the testing cases with prior knowledge for better robustness, rather than only fit to the training cases. In this paper, we propose a novel approach to sensorless freehand 3D US reconstruction considering the complex skill sequences. Our contribution is three-fold. First, we advance a novel online learning framework by designing a differentiable reconstruction algorithm. It realizes an end-to-end optimization from section sequences to the reconstructed volume. Second, a self-supervised learning method is developed to explore the context information that reconstructed by the testing data itself, promoting the perception of the model. Third, inspired by the effectiveness of shape prior, we also introduce adversarial training to strengthen the learning of anatomical shape prior in the reconstructed volume. By mining the context and structural cues of the testing data, our online learning methods can drive the model to handle complex skill sequences. Experimental results on developmental dysplasia of the hip US and fetal US datasets show that, our proposed method can outperform the start-of-the-art methods regarding the shift errors and path similarities.
Style Curriculum Learning for Robust Medical Image Segmentation
Aug 01, 2021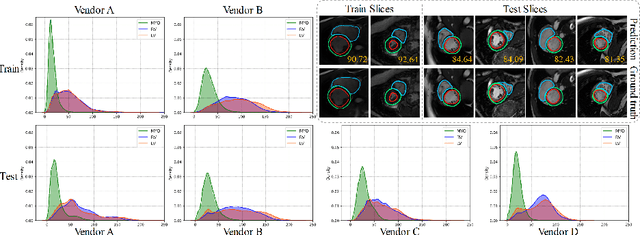

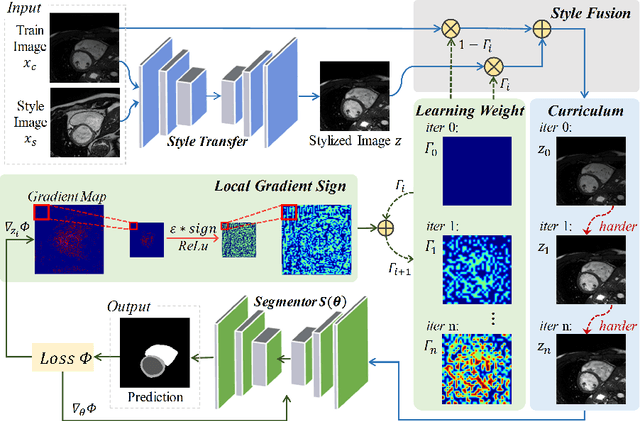

The performance of deep segmentation models often degrades due to distribution shifts in image intensities between the training and test data sets. This is particularly pronounced in multi-centre studies involving data acquired using multi-vendor scanners, with variations in acquisition protocols. It is challenging to address this degradation because the shift is often not known \textit{a priori} and hence difficult to model. We propose a novel framework to ensure robust segmentation in the presence of such distribution shifts. Our contribution is three-fold. First, inspired by the spirit of curriculum learning, we design a novel style curriculum to train the segmentation models using an easy-to-hard mode. A style transfer model with style fusion is employed to generate the curriculum samples. Gradually focusing on complex and adversarial style samples can significantly boost the robustness of the models. Second, instead of subjectively defining the curriculum complexity, we adopt an automated gradient manipulation method to control the hard and adversarial sample generation process. Third, we propose the Local Gradient Sign strategy to aggregate the gradient locally and stabilise training during gradient manipulation. The proposed framework can generalise to unknown distribution without using any target data. Extensive experiments on the public M\&Ms Challenge dataset demonstrate that our proposed framework can generalise deep models well to unknown distributions and achieve significant improvements in segmentation accuracy.
Searching Collaborative Agents for Multi-plane Localization in 3D Ultrasound
May 22, 2021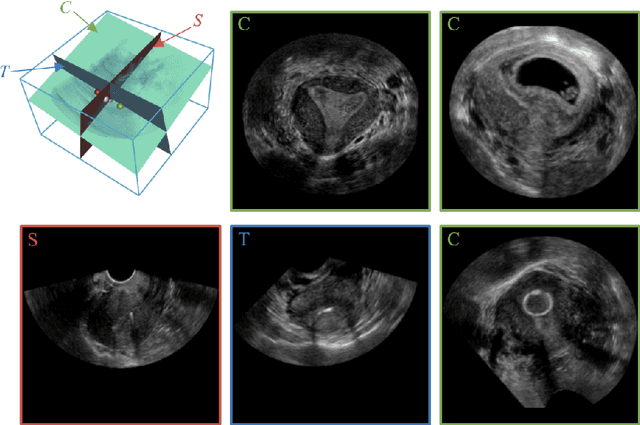
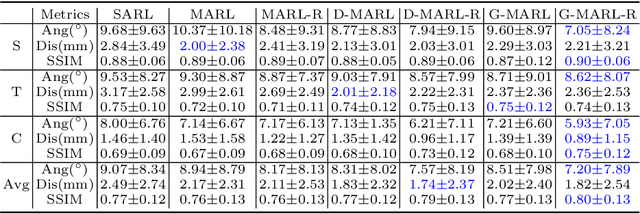
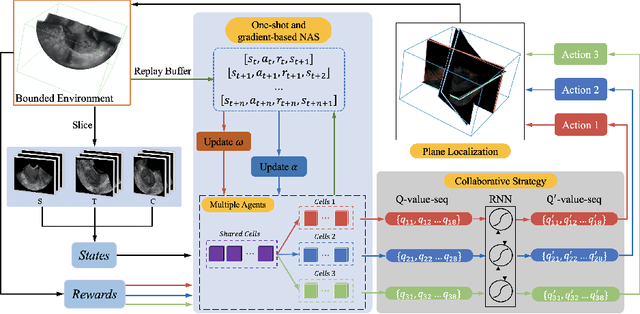

3D ultrasound (US) has become prevalent due to its rich spatial and diagnostic information not contained in 2D US. Moreover, 3D US can contain multiple standard planes (SPs) in one shot. Thus, automatically localizing SPs in 3D US has the potential to improve user-independence and scanning-efficiency. However, manual SP localization in 3D US is challenging because of the low image quality, huge search space and large anatomical variability. In this work, we propose a novel multi-agent reinforcement learning (MARL) framework to simultaneously localize multiple SPs in 3D US. Our contribution is four-fold. First, our proposed method is general and it can accurately localize multiple SPs in different challenging US datasets. Second, we equip the MARL system with a recurrent neural network (RNN) based collaborative module, which can strengthen the communication among agents and learn the spatial relationship among planes effectively. Third, we explore to adopt the neural architecture search (NAS) to automatically design the network architecture of both the agents and the collaborative module. Last, we believe we are the first to realize automatic SP localization in pelvic US volumes, and note that our approach can handle both normal and abnormal uterus cases. Extensively validated on two challenging datasets of the uterus and fetal brain, our proposed method achieves the average localization accuracy of 7.03 degrees/1.59mm and 9.75 degrees/1.19mm. Experimental results show that our light-weight MARL model has higher accuracy than state-of-the-art methods.
Generalize Ultrasound Image Segmentation via Instant and Plug & Play Style Transfer
Jan 11, 2021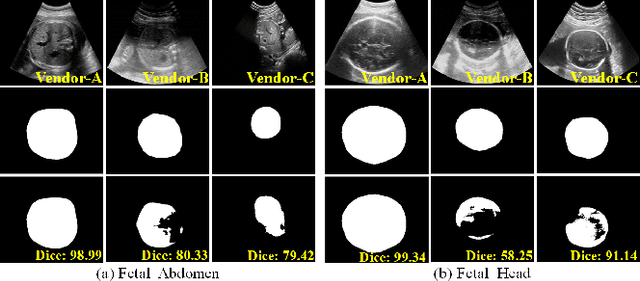
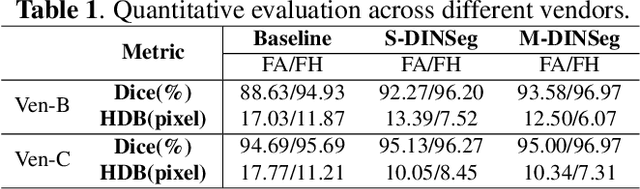
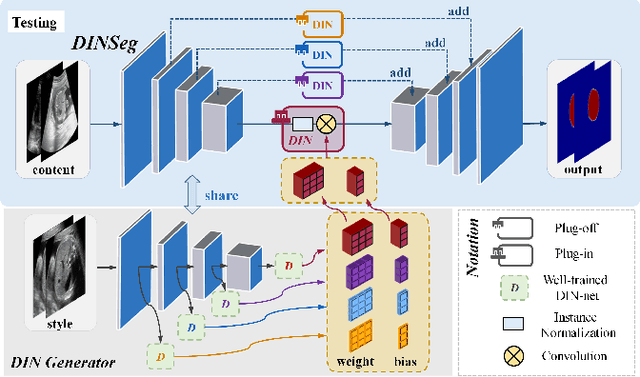
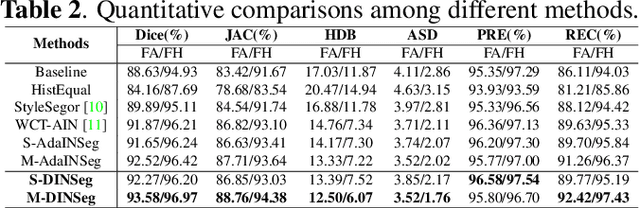
Deep segmentation models that generalize to images with unknown appearance are important for real-world medical image analysis. Retraining models leads to high latency and complex pipelines, which are impractical in clinical settings. The situation becomes more severe for ultrasound image analysis because of their large appearance shifts. In this paper, we propose a novel method for robust segmentation under unknown appearance shifts. Our contribution is three-fold. First, we advance a one-stage plug-and-play solution by embedding hierarchical style transfer units into a segmentation architecture. Our solution can remove appearance shifts and perform segmentation simultaneously. Second, we adopt Dynamic Instance Normalization to conduct precise and dynamic style transfer in a learnable manner, rather than previously fixed style normalization. Third, our solution is fast and lightweight for routine clinical adoption. Given 400*400 image input, our solution only needs an additional 0.2ms and 1.92M FLOPs to handle appearance shifts compared to the baseline pipeline. Extensive experiments are conducted on a large dataset from three vendors demonstrate our proposed method enhances the robustness of deep segmentation models.
Style-invariant Cardiac Image Segmentation with Test-time Augmentation
Sep 24, 2020



Deep models often suffer from severe performance drop due to the appearance shift in the real clinical setting. Most of the existing learning-based methods rely on images from multiple sites/vendors or even corresponding labels. However, collecting enough unknown data to robustly model segmentation cannot always hold since the complex appearance shift caused by imaging factors in daily application. In this paper, we propose a novel style-invariant method for cardiac image segmentation. Based on the zero-shot style transfer to remove appearance shift and test-time augmentation to explore diverse underlying anatomy, our proposed method is effective in combating the appearance shift. Our contribution is three-fold. First, inspired by the spirit of universal style transfer, we develop a zero-shot stylization for content images to generate stylized images that appearance similarity to the style images. Second, we build up a robust cardiac segmentation model based on the U-Net structure. Our framework mainly consists of two networks during testing: the ST network for removing appearance shift and the segmentation network. Third, we investigate test-time augmentation to explore transformed versions of the stylized image for prediction and the results are merged. Notably, our proposed framework is fully test-time adaptation. Experiment results demonstrate that our methods are promising and generic for generalizing deep segmentation models.