 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Real is Your Jailbreak? Fine-grained Jailbreak Evaluation with Anchored Reference
Jan 04, 2026Jailbreak attacks present a significant challenge to the safety of Large Language Models (LLMs), yet current automated evaluation methods largely rely on coarse classifications that focus mainly on harmfulness, leading to substantial overestimation of attack success. To address this problem, we propose FJAR, a fine-grained jailbreak evaluation framework with anchored references. We first categorized jailbreak responses into five fine-grained categories: Rejective, Irrelevant, Unhelpful, Incorrect, and Successful, based on the degree to which the response addresses the malicious intent of the query. This categorization serves as the basis for FJAR. Then, we introduce a novel harmless tree decomposition approach to construct high-quality anchored references by breaking down the original queries. These references guide the evaluator in determining whether the response genuinely fulfills the original query. Extensive experiments demonstrate that FJAR achieves the highest alignment with human judgment and effectively identifies the root causes of jailbreak failures, providing actionable guidance for improving attack strategies.
Feint and Attack: Attention-Based Strategies for Jailbreaking and Protecting LLMs
Oct 18, 2024



Jailbreak attack can be used to access the vulnerabilities of Large Language Models (LLMs) by inducing LLMs to generate the harmful content. And the most common method of the attack is to construct semantically ambiguous prompts to confuse and mislead the LLMs. To access the security and reveal the intrinsic relation between the input prompt and the output for LLMs, the distribution of attention weight is introduced to analyze the underlying reasons. By using statistical analysis methods, some novel metrics are defined to better describe the distribution of attention weight, such as the Attention Intensity on Sensitive Words (Attn_SensWords), the Attention-based Contextual Dependency Score (Attn_DepScore) and Attention Dispersion Entropy (Attn_Entropy). By leveraging the distinct characteristics of these metrics, the beam search algorithm and inspired by the military strategy "Feint and Attack", an effective jailbreak attack strategy named as Attention-Based Attack (ABA) is proposed. In the ABA, nested attack prompts are employed to divert the attention distribution of the LLMs. In this manner, more harmless parts of the input can be used to attract the attention of the LLMs. In addition, motivated by ABA, an effective defense strategy called as Attention-Based Defense (ABD) is also put forward. Compared with ABA, the ABD can be used to enhance the robustness of LLMs by calibrating the attention distribution of the input prompt. Some comparative experiments have been given to demonstrate the effectiveness of ABA and ABD. Therefore, both ABA and ABD can be used to access the security of the LLMs. The comparative experiment results also give a logical explanation that the distribution of attention weight can bring great influence on the output for LLMs.
Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
Apr 19, 2022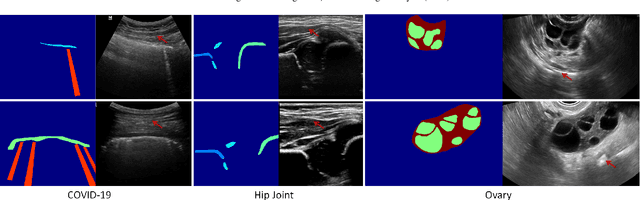
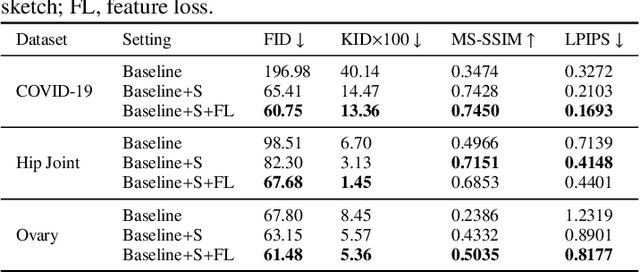
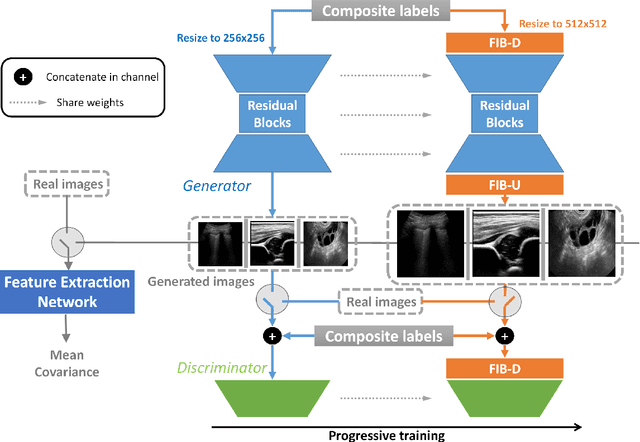

Ultrasound (US) imaging is widely used for anatomical structure inspection in clinical diagnosis. The training of new sonographers and deep learning based algorithms for US image analysis usually requires a large amount of data. However, obtaining and labeling large-scale US imaging data are not easy tasks, especially for diseases with low incidence. Realistic US image synthesis can alleviate this problem to a great extent. In this paper, we propose a generative adversarial network (GAN) based image synthesis framework. Our main contributions include: 1) we present the first work that can synthesize realistic B-mode US images with high-resolution and customized texture editing features; 2) to enhance structural details of generated images, we propose to introduce auxiliary sketch guidance into a conditional GAN. We superpose the edge sketch onto the object mask and use the composite mask as the network input; 3) to generate high-resolution US images, we adopt a progressive training strategy to gradually generate high-resolution images from low-resolution images. In addition, a feature loss is proposed to minimize the difference of high-level features between the generated and real images, which further improves the quality of generated images; 4) the proposed US image synthesis method is quite universal and can also be generalized to the US images of other anatomical structures besides the three ones tested in our study (lung, hip joint, and ovary); 5) extensive experiments on three large US image datasets are conducted to validate our method. Ablation studies, customized texture editing, user studies, and segmentation tests demonstrate promising results of our method in synthesizing realistic US images.
Bootstrap Representation Learning for Segmentation on Medical Volumes and Sequences
Jun 23, 2021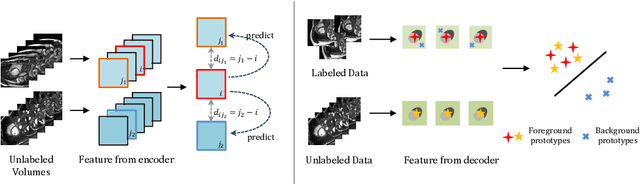
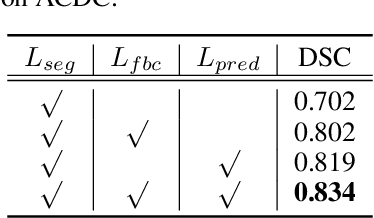
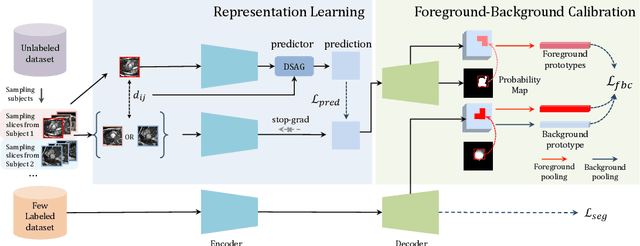

In this work, we propose a novel straightforward method for medical volume and sequence segmentation with limited annotations. To avert laborious annotating, the recent success of self-supervised learning(SSL) motivates the pre-training on unlabeled data. Despite its success, it is still challenging to adapt typical SSL methods to volume/sequence segmentation, due to their lack of mining on local semantic discrimination and rare exploitation on volume and sequence structures. Based on the continuity between slices/frames and the common spatial layout of organs across volumes/sequences, we introduced a novel bootstrap self-supervised representation learning method by leveraging the predictable possibility of neighboring slices. At the core of our method is a simple and straightforward dense self-supervision on the predictions of local representations and a strategy of predicting locals based on global context, which enables stable and reliable supervision for both global and local representation mining among volumes. Specifically, we first proposed an asymmetric network with an attention-guided predictor to enforce distance-specific prediction and supervision on slices within and across volumes/sequences. Secondly, we introduced a novel prototype-based foreground-background calibration module to enhance representation consistency. The two parts are trained jointly on labeled and unlabeled data. When evaluated on three benchmark datasets of medical volumes and sequences, our model outperforms existing methods with a large margin of 4.5\% DSC on ACDC, 1.7\% on Prostate, and 2.3\% on CAMUS. Intensive evaluations reveals the effectiveness and superiority of our method.
Style-invariant Cardiac Image Segmentation with Test-time Augmentation
Sep 24, 2020



Deep models often suffer from severe performance drop due to the appearance shift in the real clinical setting. Most of the existing learning-based methods rely on images from multiple sites/vendors or even corresponding labels. However, collecting enough unknown data to robustly model segmentation cannot always hold since the complex appearance shift caused by imaging factors in daily application. In this paper, we propose a novel style-invariant method for cardiac image segmentation. Based on the zero-shot style transfer to remove appearance shift and test-time augmentation to explore diverse underlying anatomy, our proposed method is effective in combating the appearance shift. Our contribution is three-fold. First, inspired by the spirit of universal style transfer, we develop a zero-shot stylization for content images to generate stylized images that appearance similarity to the style images. Second, we build up a robust cardiac segmentation model based on the U-Net structure. Our framework mainly consists of two networks during testing: the ST network for removing appearance shift and the segmentation network. Third, we investigate test-time augmentation to explore transformed versions of the stylized image for prediction and the results are merged. Notably, our proposed framework is fully test-time adaptation. Experiment results demonstrate that our methods are promising and generic for generalizing deep segmentation models.