 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Class Tokens: LLM-guided Dominant Property Mining for Few-shot Classification
Jul 28, 2025Few-shot Learning (FSL), which endeavors to develop the generalization ability for recognizing novel classes using only a few images, faces significant challenges due to data scarcity. Recent CLIP-like methods based on contrastive language-image pertaining mitigate the issue by leveraging textual representation of the class name for unseen image discovery. Despite the achieved success, simply aligning visual representations to class name embeddings would compromise the visual diversity for novel class discrimination. To this end, we proposed a novel Few-Shot Learning (FSL) method (BCT-CLIP) that explores \textbf{dominating properties} via contrastive learning beyond simply using class tokens. Through leveraging LLM-based prior knowledge, our method pushes forward FSL with comprehensive structural image representations, including both global category representation and the patch-aware property embeddings. In particular, we presented a novel multi-property generator (MPG) with patch-aware cross-attentions to generate multiple visual property tokens, a Large-Language Model (LLM)-assistant retrieval procedure with clustering-based pruning to obtain dominating property descriptions, and a new contrastive learning strategy for property-token learning. The superior performances on the 11 widely used datasets demonstrate that our investigation of dominating properties advances discriminative class-specific representation learning and few-shot classification.
3D Heart Reconstruction from Sparse Pose-agnostic 2D Echocardiographic Slices
Jul 03, 2025Echocardiography (echo) plays an indispensable role in the clinical practice of heart diseases. However, ultrasound imaging typically provides only two-dimensional (2D) cross-sectional images from a few specific views, making it challenging to interpret and inaccurate for estimation of clinical parameters like the volume of left ventricle (LV). 3D ultrasound imaging provides an alternative for 3D quantification, but is still limited by the low spatial and temporal resolution and the highly demanding manual delineation. To address these challenges, we propose an innovative framework for reconstructing personalized 3D heart anatomy from 2D echo slices that are frequently used in clinical practice. Specifically, a novel 3D reconstruction pipeline is designed, which alternatively optimizes between the 3D pose estimation of these 2D slices and the 3D integration of these slices using an implicit neural network, progressively transforming a prior 3D heart shape into a personalized 3D heart model. We validate the method with two datasets. When six planes are used, the reconstructed 3D heart can lead to a significant improvement for LV volume estimation over the bi-plane method (error in percent: 1.98\% VS. 20.24\%). In addition, the whole reconstruction framework makes even an important breakthrough that can estimate RV volume from 2D echo slices (with an error of 5.75\% ). This study provides a new way for personalized 3D structure and function analysis from cardiac ultrasound and is of great potential in clinical practice.
Personalized Subgraph Federated Learning with Differentiable Auxiliary Projections
May 29, 2025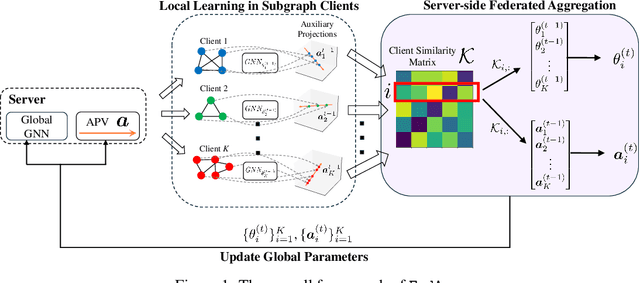
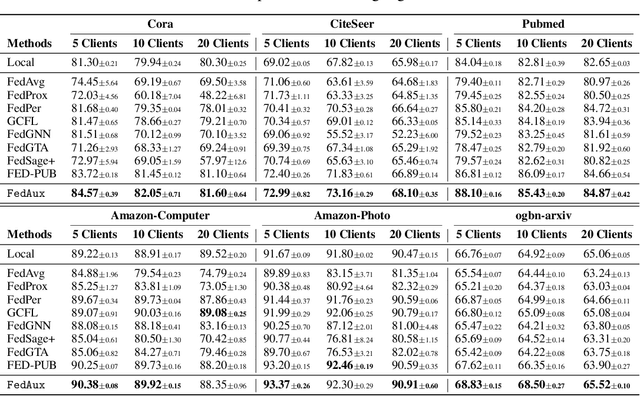
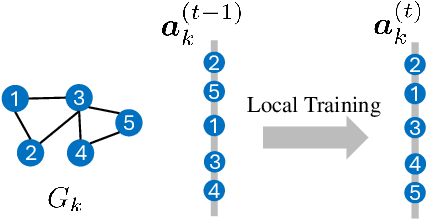
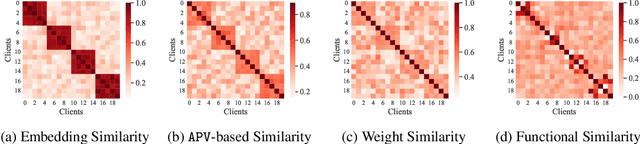
Federated learning (FL) on graph-structured data typically faces non-IID challenges, particularly in scenarios where each client holds a distinct subgraph sampled from a global graph. In this paper, we introduce Federated learning with Auxiliary projections (FedAux), a personalized subgraph FL framework that learns to align, compare, and aggregate heterogeneously distributed local models without sharing raw data or node embeddings. In FedAux, each client jointly trains (i) a local GNN and (ii) a learnable auxiliary projection vector (APV) that differentiably projects node embeddings onto a 1D space. A soft-sorting operation followed by a lightweight 1D convolution refines these embeddings in the ordered space, enabling the APV to effectively capture client-specific information. After local training, these APVs serve as compact signatures that the server uses to compute inter-client similarities and perform similarity-weighted parameter mixing, yielding personalized models while preserving cross-client knowledge transfer. Moreover, we provide rigorous theoretical analysis to establish the convergence and rationality of our design. Empirical evaluations across diverse graph benchmarks demonstrate that FedAux substantially outperforms existing baselines in both accuracy and personalization performance.
DINOv2-powered Few-Shot Semantic Segmentation: A Unified Framework via Cross-Model Distillation and 4D Correlation Mining
Apr 22, 2025Few-shot semantic segmentation has gained increasing interest due to its generalization capability, i.e., segmenting pixels of novel classes requiring only a few annotated images. Prior work has focused on meta-learning for support-query matching, with extensive development in both prototype-based and aggregation-based methods. To address data scarcity, recent approaches have turned to foundation models to enhance representation transferability for novel class segmentation. Among them, a hybrid dual-modal framework including both DINOv2 and SAM has garnered attention due to their complementary capabilities. We wonder "can we build a unified model with knowledge from both foundation models?" To this end, we propose FS-DINO, with only DINOv2's encoder and a lightweight segmenter. The segmenter features a bottleneck adapter, a meta-visual prompt generator based on dense similarities and semantic embeddings, and a decoder. Through coarse-to-fine cross-model distillation, we effectively integrate SAM's knowledge into our lightweight segmenter, which can be further enhanced by 4D correlation mining on support-query pairs. Extensive experiments on COCO-20i, PASCAL-5i, and FSS-1000 demonstrate the effectiveness and superiority of our method.
EchoONE: Segmenting Multiple echocardiography Planes in One Model
Dec 04, 2024In clinical practice of echocardiography examinations, multiple planes containing the heart structures of different view are usually required in screening, diagnosis and treatment of cardiac disease. AI models for echocardiography have to be tailored for each specific plane due to the dramatic structure differences, thus resulting in repetition development and extra complexity. Effective solution for such a multi-plane segmentation (MPS) problem is highly demanded for medical images, yet has not been well investigated. In this paper, we propose a novel solution, EchoONE, for this problem with a SAM-based segmentation architecture, a prior-composable mask learning (PC-Mask) module for semantic-aware dense prompt generation, and a learnable CNN-branch with a simple yet effective local feature fusion and adaption (LFFA) module for SAM adapting. We extensively evaluated our method on multiple internal and external echocardiography datasets, and achieved consistently state-of-the-art performance for multi-source datasets with different heart planes. This is the first time that the MPS problem is solved in one model for echocardiography data. The code will be available at https://github.com/a2502503/EchoONE.
Partitioning Message Passing for Graph Fraud Detection
Nov 16, 2024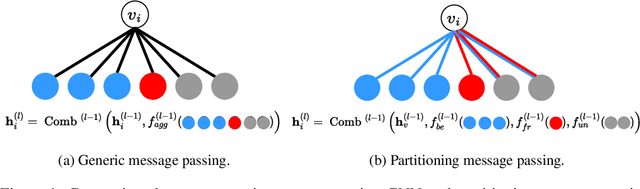
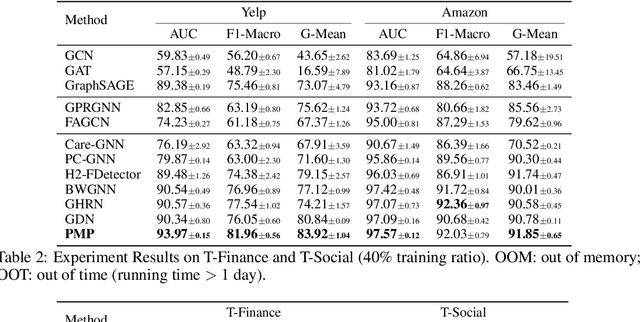
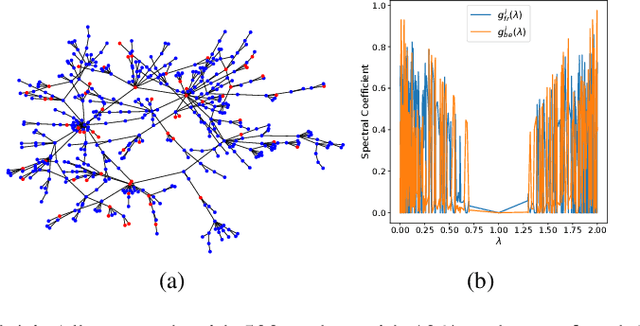
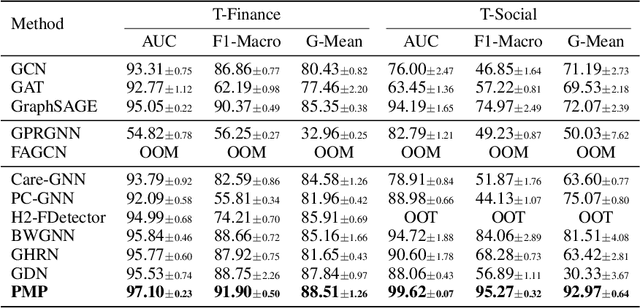
Label imbalance and homophily-heterophily mixture are the fundamental problems encountered when applying Graph Neural Networks (GNNs) to Graph Fraud Detection (GFD) tasks. Existing GNN-based GFD models are designed to augment graph structure to accommodate the inductive bias of GNNs towards homophily, by excluding heterophilic neighbors during message passing. In our work, we argue that the key to applying GNNs for GFD is not to exclude but to {\em distinguish} neighbors with different labels. Grounded in this perspective, we introduce Partitioning Message Passing (PMP), an intuitive yet effective message passing paradigm expressly crafted for GFD. Specifically, in the neighbor aggregation stage of PMP, neighbors with different classes are aggregated with distinct node-specific aggregation functions. By this means, the center node can adaptively adjust the information aggregated from its heterophilic and homophilic neighbors, thus avoiding the model gradient being dominated by benign nodes which occupy the majority of the population. We theoretically establish a connection between the spatial formulation of PMP and spectral analysis to characterize that PMP operates an adaptive node-specific spectral graph filter, which demonstrates the capability of PMP to handle heterophily-homophily mixed graphs. Extensive experimental results show that PMP can significantly boost the performance on GFD tasks.
Orthogonal Hyper-category Guided Multi-interest Elicitation for Micro-video Matching
Jul 20, 2024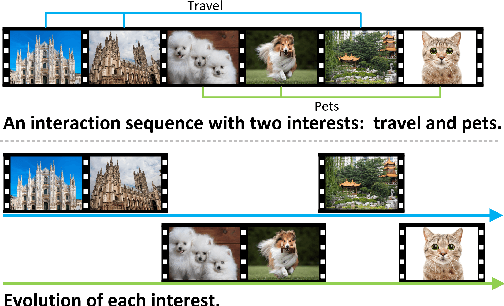
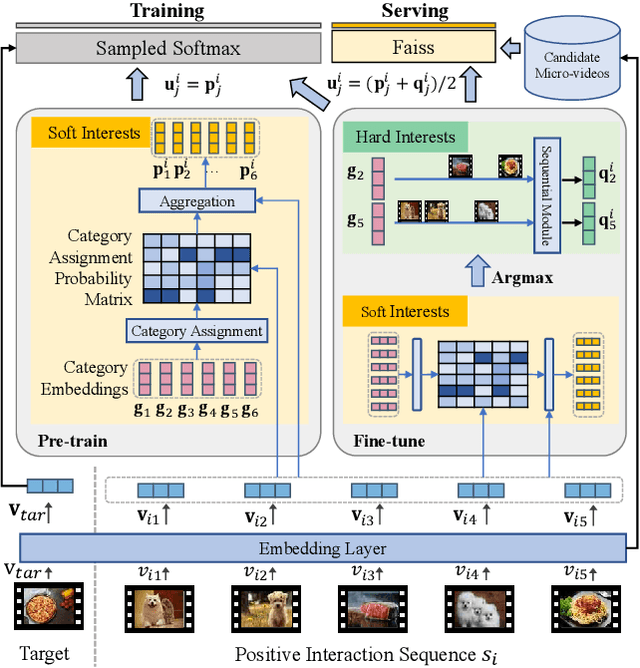
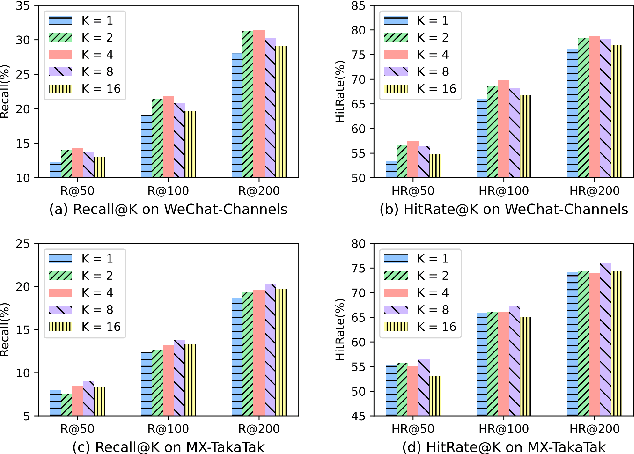
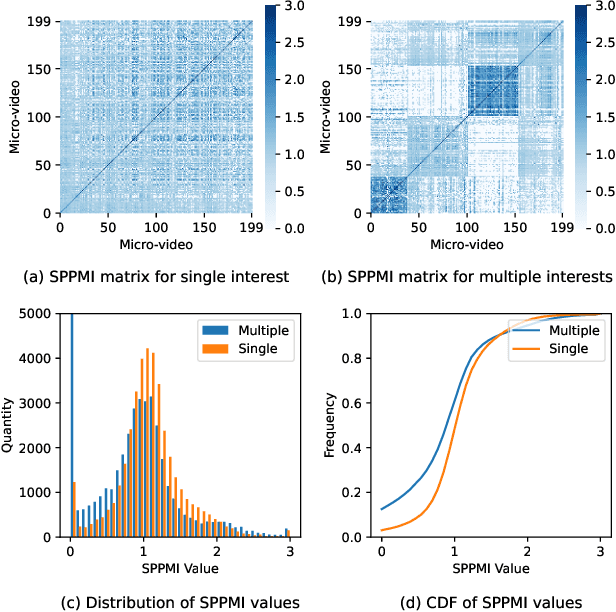
Watching micro-videos is becoming a part of public daily life. Usually, user watching behaviors are thought to be rooted in their multiple different interests. In the paper, we propose a model named OPAL for micro-video matching, which elicits a user's multiple heterogeneous interests by disentangling multiple soft and hard interest embeddings from user interactions. Moreover, OPAL employs a two-stage training strategy, in which the pre-train is to generate soft interests from historical interactions under the guidance of orthogonal hyper-categories of micro-videos and the fine-tune is to reinforce the degree of disentanglement among the interests and learn the temporal evolution of each interest of each user. We conduct extensive experiments on two real-world datasets. The results show that OPAL not only returns diversified micro-videos but also outperforms six state-of-the-art models in terms of recall and hit rate.
Commute Graph Neural Networks
Jun 30, 2024Graph Neural Networks (GNNs) have shown remarkable success in learning from graph-structured data. However, their application to directed graphs (digraphs) presents unique challenges, primarily due to the inherent asymmetry in node relationships. Traditional GNNs are adept at capturing unidirectional relations but fall short in encoding the mutual path dependencies between nodes, such as asymmetrical shortest paths typically found in digraphs. Recognizing this gap, we introduce Commute Graph Neural Networks (CGNN), an approach that seamlessly integrates node-wise commute time into the message passing scheme. The cornerstone of CGNN is an efficient method for computing commute time using a newly formulated digraph Laplacian. Commute time information is then integrated into the neighborhood aggregation process, with neighbor contributions weighted according to their respective commute time to the central node in each layer. It enables CGNN to directly capture the mutual, asymmetric relationships in digraphs.
Efficient Graph Similarity Computation with Alignment Regularization
Jun 21, 2024We consider the graph similarity computation (GSC) task based on graph edit distance (GED) estimation. State-of-the-art methods treat GSC as a learning-based prediction task using Graph Neural Networks (GNNs). To capture fine-grained interactions between pair-wise graphs, these methods mostly contain a node-level matching module in the end-to-end learning pipeline, which causes high computational costs in both the training and inference stages. We show that the expensive node-to-node matching module is not necessary for GSC, and high-quality learning can be attained with a simple yet powerful regularization technique, which we call the Alignment Regularization (AReg). In the training stage, the AReg term imposes a node-graph correspondence constraint on the GNN encoder. In the inference stage, the graph-level representations learned by the GNN encoder are directly used to compute the similarity score without using AReg again to speed up inference. We further propose a multi-scale GED discriminator to enhance the expressive ability of the learned representations. Extensive experiments on real-world datasets demonstrate the effectiveness, efficiency and transferability of our approach.
APSeg: Auto-Prompt Network for Cross-Domain Few-Shot Semantic Segmentatio
Jun 12, 2024Few-shot semantic segmentation (FSS) endeavors to segment unseen classes with only a few labeled samples. Current FSS methods are commonly built on the assumption that their training and application scenarios share similar domains, and their performances degrade significantly while applied to a distinct domain. To this end, we propose to leverage the cutting-edge foundation model, the Segment Anything Model (SAM), for generalization enhancement. The SAM however performs unsatisfactorily on domains that are distinct from its training data, which primarily comprise natural scene images, and it does not support automatic segmentation of specific semantics due to its interactive prompting mechanism. In our work, we introduce APSeg, a novel auto-prompt network for cross-domain few-shot semantic segmentation (CD-FSS), which is designed to be auto-prompted for guiding cross-domain segmentation. Specifically, we propose a Dual Prototype Anchor Transformation (DPAT) module that fuses pseudo query prototypes extracted based on cycle-consistency with support prototypes, allowing features to be transformed into a more stable domain-agnostic space. Additionally, a Meta Prompt Generator (MPG) module is introduced to automatically generate prompt embeddings, eliminating the need for manual visual prompts. We build an efficient model which can be applied directly to target domains without fine-tuning. Extensive experiments on four cross-domain datasets show that our model outperforms the state-of-the-art CD-FSS method by 5.24% and 3.10% in average accuracy on 1-shot and 5-shot settings, respectively.