 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3D-Stereo: A Multiple-Medium and Multiple-Degradation Dataset for Stereo Image Restoration
Apr 14, 2026Image restoration under adverse conditions, such as underwater, haze or fog, and low-light environments, remains a highly challenging problem due to complex physical degradations and severe information loss. Existing datasets are predominantly limited to a single degradation type or heavily rely on synthetic data without stereo consistency, inherently restricting their applicability in real-world scenarios. To address this, we introduce M3D-Stereo, a stereo dataset with 7904 high-resolution image pairs for image restoration research acquired in multiple media with multiple controlled degradation levels. It encompasses four degradation scenarios: underwater scatter, haze/fog, underwater low-light, and haze low-light. Each scenario forms a subset, and is divided into six levels of progressive degradation, allowing fine-grained evaluations of restoration methods with increasing severity of degradation. Collected via a laboratory setup, the dataset provides aligned stereo image pairs along with their pixel-wise consistent clear ground truths. Two restoration tasks, single-level and mixed-level degradation, were performed to verify its validity. M3D-Stereo establishes a better controlled and more realistic benchmark to evaluate image restoration and stereo matching methods in complex degradation environments. It is made public under LGPLv3 license.
EchoONE: Segmenting Multiple echocardiography Planes in One Model
Dec 04, 2024In clinical practice of echocardiography examinations, multiple planes containing the heart structures of different view are usually required in screening, diagnosis and treatment of cardiac disease. AI models for echocardiography have to be tailored for each specific plane due to the dramatic structure differences, thus resulting in repetition development and extra complexity. Effective solution for such a multi-plane segmentation (MPS) problem is highly demanded for medical images, yet has not been well investigated. In this paper, we propose a novel solution, EchoONE, for this problem with a SAM-based segmentation architecture, a prior-composable mask learning (PC-Mask) module for semantic-aware dense prompt generation, and a learnable CNN-branch with a simple yet effective local feature fusion and adaption (LFFA) module for SAM adapting. We extensively evaluated our method on multiple internal and external echocardiography datasets, and achieved consistently state-of-the-art performance for multi-source datasets with different heart planes. This is the first time that the MPS problem is solved in one model for echocardiography data. The code will be available at https://github.com/a2502503/EchoONE.
FFPN: Fourier Feature Pyramid Network for Ultrasound Image Segmentation
Aug 26, 2023
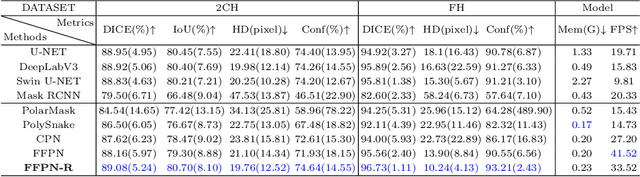
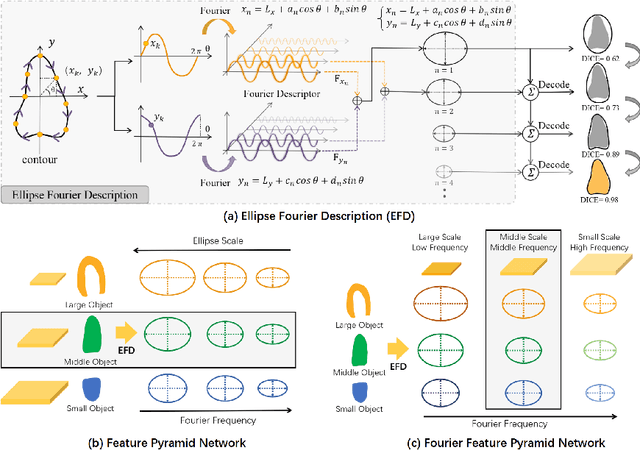
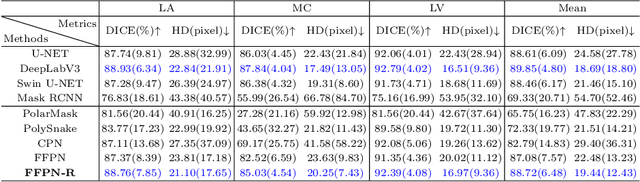
Ultrasound (US) image segmentation is an active research area that requires real-time and highly accurate analysis in many scenarios. The detect-to-segment (DTS) frameworks have been recently proposed to balance accuracy and efficiency. However, existing approaches may suffer from inadequate contour encoding or fail to effectively leverage the encoded results. In this paper, we introduce a novel Fourier-anchor-based DTS framework called Fourier Feature Pyramid Network (FFPN) to address the aforementioned issues. The contributions of this paper are two fold. First, the FFPN utilizes Fourier Descriptors to adequately encode contours. Specifically, it maps Fourier series with similar amplitudes and frequencies into the same layer of the feature map, thereby effectively utilizing the encoded Fourier information. Second, we propose a Contour Sampling Refinement (CSR) module based on the contour proposals and refined features produced by the FFPN. This module extracts rich features around the predicted contours to further capture detailed information and refine the contours. Extensive experimental results on three large and challenging datasets demonstrate that our method outperforms other DTS methods in terms of accuracy and efficiency. Furthermore, our framework can generalize well to other detection or segmentation tasks.
Deep Learning Methods for Small Molecule Drug Discovery: A Survey
Mar 05, 2023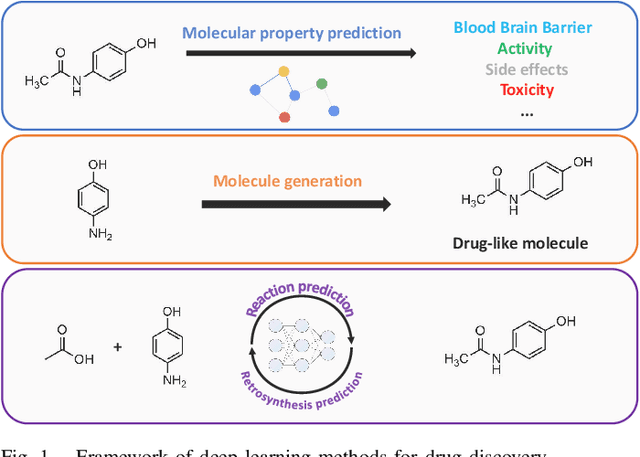
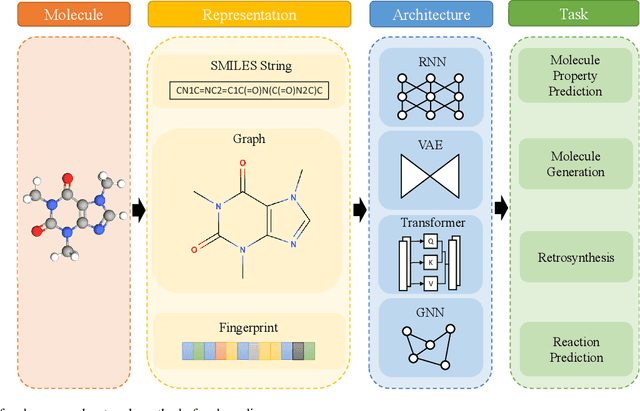
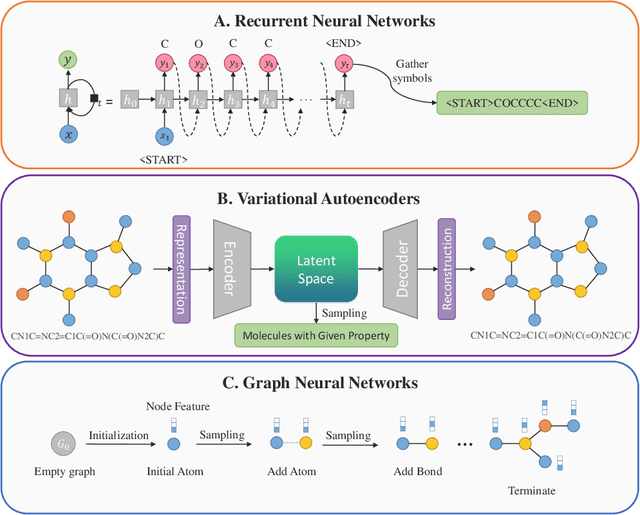
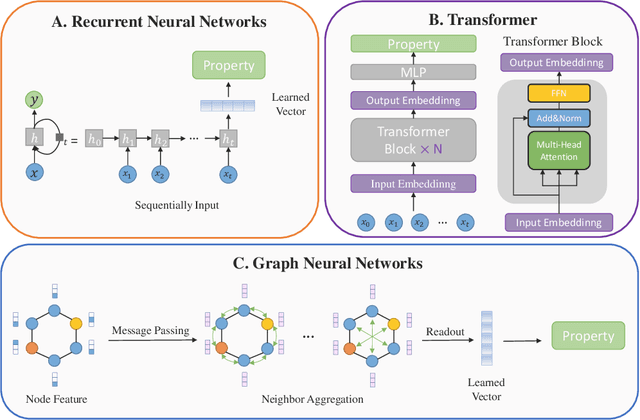
With the development of computer-assisted techniques, research communities including biochemistry and deep learning have been devoted into the drug discovery field for over a decade. Various applications of deep learning have drawn great attention in drug discovery, such as molecule generation, molecular property prediction, retrosynthesis prediction, and reaction prediction. While most existing surveys only focus on one of the applications, limiting the view of researchers in the community. In this paper, we present a comprehensive review on the aforementioned four aspects, and discuss the relationships among different applications. The latest literature and classical benchmarks are presented for better understanding the development of variety of approaches. We commence by summarizing the molecule representation format in these works, followed by an introduction of recent proposed approaches for each of the four tasks. Furthermore, we review a variety of commonly used datasets and evaluation metrics and compare the performance of deep learning-based models. Finally, we conclude by identifying remaining challenges and discussing the future trend for deep learning methods in drug discovery.
Time and Frequency Network for Human Action Detection in Videos
Mar 08, 2021
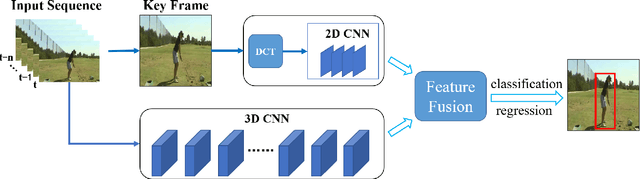
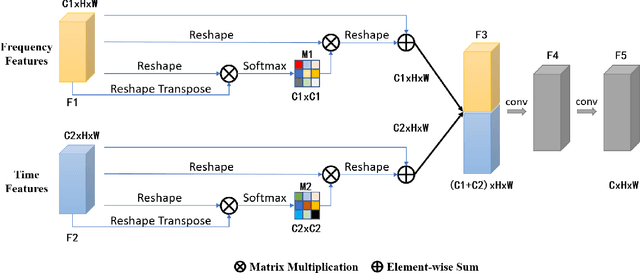

Currently, spatiotemporal features are embraced by most deep learning approaches for human action detection in videos, however, they neglect the important features in frequency domain. In this work, we propose an end-to-end network that considers the time and frequency features simultaneously, named TFNet. TFNet holds two branches, one is time branch formed of three-dimensional convolutional neural network(3D-CNN), which takes the image sequence as input to extract time features; and the other is frequency branch, extracting frequency features through two-dimensional convolutional neural network(2D-CNN) from DCT coefficients. Finally, to obtain the action patterns, these two features are deeply fused under the attention mechanism. Experimental results on the JHMDB51-21 and UCF101-24 datasets demonstrate that our approach achieves remarkable performance for frame-mAP.