 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenDeepThink: Parallel Reasoning via Bradley--Terry Aggregation
May 14, 2026Test-time compute scaling is a primary axis for improving LLM reasoning. Existing methods primarily scale depth by extending a single reasoning trace. Scaling breadth by sampling multiple candidates in parallel is straightforward, but introduces a selection bottleneck: choosing the best candidate without a ground-truth verifier, since pointwise LLM judging is noisy and biased. To address this, we introduce OpenDeepThink, a population-based test-time compute framework that selects via pairwise Bradley-Terry comparison. Each generation, the LLM judges random pairs of candidates and aggregates votes via Bradley-Terry into a global ranking; top-ranked candidates are preserved and the top three quarters are mutated using the natural-language critiques produced during comparison; the bottom quarter is discarded. OpenDeepThink raises Gemini 3.1 Pro's effective Codeforces Elo by +405 points in eight sequential LLM-call rounds (~27 minutes wall-clock). The pipeline transfers across weaker and stronger models without retuning, and on the multi-domain HLE benchmark, gains appear concentrated in objectively verifiable domains and reverse in subjective ones. We release CF-73, a curated set of 73 expert-rated Codeforces problems with International Grandmaster annotation and 99% local-evaluation agreement against the official verdict.
FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
May 14, 2026Many real-world coding challenges are open-ended and admit no known optimal solution. Yet, recent progress in LLM coding has focused on well-defined tasks such as feature implementation, bug fixing, and competitive programming. Open-ended coding remains a weak spot for LLMs, largely because open-ended training problems are scarce and expensive to construct. Our goal is to synthesize open-ended coding problems at scale to train stronger LLM coders. We introduce FrontierSmith, an automated system for iteratively evolving open-ended problems from existing closed-ended coding tasks. Starting from competitive programming problems, FrontierSmith generates candidate open-ended variants by changing the problems'goals, restricting outputs, and generalizing inputs. It then uses a quantitative idea divergence metric to select problems that elicit genuinely diverse approaches from different solvers. Agents then generate test cases and verifiers for the surviving candidates. On two open-ended coding benchmarks, training on our synthesized data yields substantial gains over the base models: Qwen3.5-9B improves by +8.82 score on FrontierCS and +306.36 (Elo-rating-based performance) on ALE-bench; Qwen3.5-27B improves by +12.12 and +309.12, respectively. The synthesized problems also make agents take more turns and use more tokens, similar to human-curated ones, suggesting that closed-ended seeds can be a practical starting point for long-horizon coding data.
VisionFoundry: Teaching VLMs Visual Perception with Synthetic Images
Apr 10, 2026Vision-language models (VLMs) still struggle with visual perception tasks such as spatial understanding and viewpoint recognition. One plausible contributing factor is that natural image datasets provide limited supervision for low-level visual skills. This motivates a practical question: can targeted synthetic supervision, generated from only a task keyword such as Depth Order, address these weaknesses? To investigate this question, we introduce VisionFoundry, a task-aware synthetic data generation pipeline that takes only the task name as input and uses large language models (LLMs) to generate questions, answers, and text-to-image (T2I) prompts, then synthesizes images with T2I models and verifies consistency with a proprietary VLM, requiring no reference images or human annotation. Using VisionFoundry, we construct VisionFoundry-10K, a synthetic visual question answering (VQA) dataset containing 10k image-question-answer triples spanning 10 tasks. Models trained on VisionFoundry-10K achieve substantial improvements on visual perception benchmarks: +7% on MMVP and +10% on CV-Bench-3D, while preserving broader capabilities and showing favorable scaling behavior as data size increases. Our results suggest that limited task-targeted supervision is an important contributor to this bottleneck and that synthetic supervision is a promising path toward more systematic training for VLMs.
Agent Banana: High-Fidelity Image Editing with Agentic Thinking and Tooling
Feb 09, 2026We study instruction-based image editing under professional workflows and identify three persistent challenges: (i) editors often over-edit, modifying content beyond the user's intent; (ii) existing models are largely single-turn, while multi-turn edits can alter object faithfulness; and (iii) evaluation at around 1K resolution is misaligned with real workflows that often operate on ultra high-definition images (e.g., 4K). We propose Agent Banana, a hierarchical agentic planner-executor framework for high-fidelity, object-aware, deliberative editing. Agent Banana introduces two key mechanisms: (1) Context Folding, which compresses long interaction histories into structured memory for stable long-horizon control; and (2) Image Layer Decomposition, which performs localized layer-based edits to preserve non-target regions while enabling native-resolution outputs. To support rigorous evaluation, we build HDD-Bench, a high-definition, dialogue-based benchmark featuring verifiable stepwise targets and native 4K images (11.8M pixels) for diagnosing long-horizon failures. On HDD-Bench, Agent Banana achieves the best multi-turn consistency and background fidelity (e.g., IC 0.871, SSIM-OM 0.84, LPIPS-OM 0.12) while remaining competitive on instruction following, and also attains strong performance on standard single-turn editing benchmarks. We hope this work advances reliable, professional-grade agentic image editing and its integration into real workflows.
UEval: A Benchmark for Unified Multimodal Generation
Jan 29, 2026We introduce UEval, a benchmark to evaluate unified models, i.e., models capable of generating both images and text. UEval comprises 1,000 expert-curated questions that require both images and text in the model output, sourced from 8 real-world tasks. Our curated questions cover a wide range of reasoning types, from step-by-step guides to textbook explanations. Evaluating open-ended multimodal generation is non-trivial, as simple LLM-as-a-judge methods can miss the subtleties. Different from previous works that rely on multimodal Large Language Models (MLLMs) to rate image quality or text accuracy, we design a rubric-based scoring system in UEval. For each question, reference images and text answers are provided to a MLLM to generate an initial rubric, consisting of multiple evaluation criteria, and human experts then refine and validate these rubrics. In total, UEval contains 10,417 validated rubric criteria, enabling scalable and fine-grained automatic scoring. UEval is challenging for current unified models: GPT-5-Thinking scores only 66.4 out of 100, while the best open-source model reaches merely 49.1. We observe that reasoning models often outperform non-reasoning ones, and transferring reasoning traces from a reasoning model to a non-reasoning model significantly narrows the gap. This suggests that reasoning may be important for tasks requiring complex multimodal understanding and generation.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Reasoning Matters for 3D Visual Grounding
Jan 13, 2026The recent development of Large Language Models (LLMs) with strong reasoning ability has driven research in various domains such as mathematics, coding, and scientific discovery. Meanwhile, 3D visual grounding, as a fundamental task in 3D understanding, still remains challenging due to the limited reasoning ability of recent 3D visual grounding models. Most of the current methods incorporate a text encoder and visual feature encoder to generate cross-modal fuse features and predict the referring object. These models often require supervised training on extensive 3D annotation data. On the other hand, recent research also focus on scaling synthetic data to train stronger 3D visual grounding LLM, however, the performance gain remains limited and non-proportional to the data collection cost. In this work, we propose a 3D visual grounding data pipeline, which is capable of automatically synthesizing 3D visual grounding data along with corresponding reasoning process. Additionally, we leverage the generated data for LLM fine-tuning and introduce Reason3DVG-8B, a strong 3D visual grounding LLM that outperforms previous LLM-based method 3D-GRAND using only 1.6% of their training data, demonstrating the effectiveness of our data and the importance of reasoning in 3D visual grounding.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Next-Embedding Prediction Makes Strong Vision Learners
Dec 23, 2025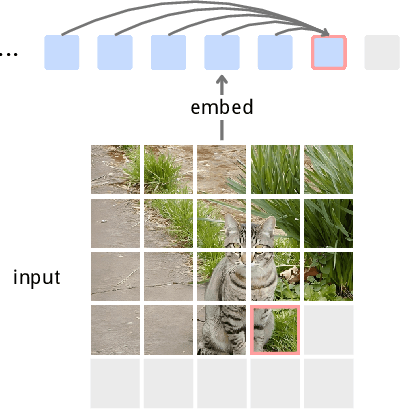
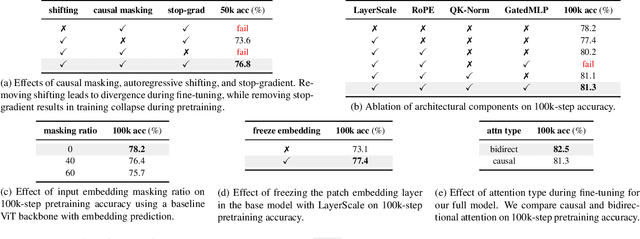
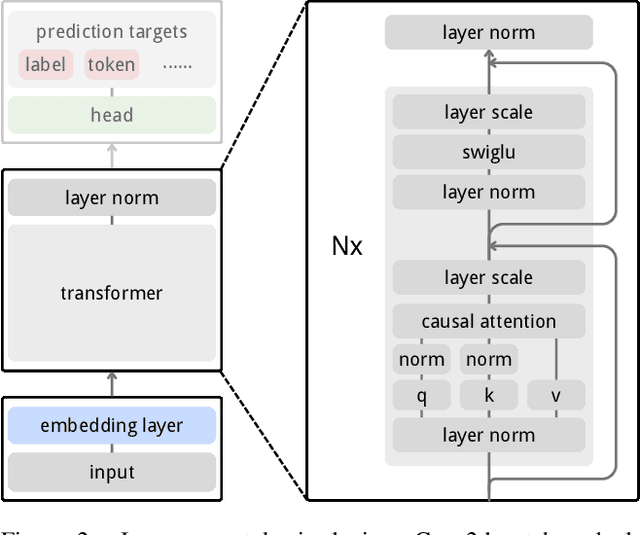
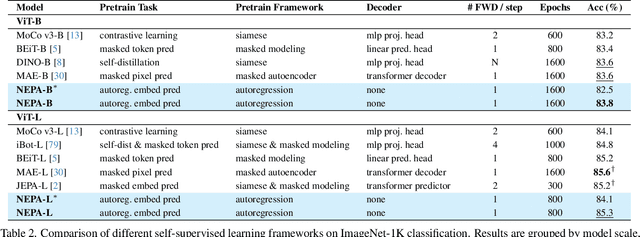
Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.