 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWeaver: Evaluating and Evolving Skills for Agentic Long Video Generation
Jun 06, 2026Recent agent frameworks such as Claude Code, Codex, and OpenClaw are strong at tool use and orchestration, but whether they can handle long video generation, a long-horizon multimodal task, remains underexplored. Unlike earlier video agents whose pipeline is handcrafted, these frameworks can build and refine their own workflows. We introduce VideoWeaver, an agent harness and benchmark that evaluates and evolves skills for long video generation, where an agent turns a single instruction into a long video by composing foundation skills into its own workflow rather than following a predefined pipeline. The benchmark has 16 task categories and 285 cases, with references spanning text, image, audio, video, and their combinations. Because errors can arise at any stage and not just in the final video, we propose an agent-as-judge that inspects both the execution trace and the final video, grounding its scores in evidence such as metadata and intermediate files. Using this feedback, we further design a skill evolution algorithm that refines and merges the agent's skills. Across multiple frameworks and models, we find that an explicit composition skill improves the generation process over using foundation skills alone, that skill evolution further improves output quality, and that performance varies notably across harness and model choices. The proposed agent-as-judge also aligns well with human judgments, especially on process metrics. Code and dataset is available at https://github.com/JianhuiWei7/VideoWeaver
Learning, locomotion, and navigation of soft synthetic snakes in three-dimensional, heterogeneous environments
May 24, 2026Limbless terrestrial animals exhibit exceptional locomotor versatility and control, currently unmatched by engineered counterparts. Here, we introduce a computational framework that enables soft synthetic snakes to navigate unstructured, heterogeneous 3D terrains. Our approach is grounded in bio-inspired actuation and sensing models that reduce the control complexity inherent to high-degree-of-freedom, continuum bodies. These models are integrated into a reinforcement learning architecture to derive environment-traversing policies. Training first occurs in simplified, homogeneous terrains to learn locomotion primitives. These are then composed into adaptive strategies for complex landscapes. We demonstrate robustness by deploying a snake in high-fidelity 3D environments reconstructed from real-world imaging, achieving reliable navigation. Overall, this work provides a physically-realistic simulation platform and practical insights for the control of continuum systems in natural terrains.
How Far Are Video Models from True Multimodal Reasoning?
Apr 21, 2026Despite remarkable progress toward general-purpose video models, a critical question remains unanswered: how far are these models from achieving true multimodal reasoning? Existing benchmarks fail to address this question rigorously, as they remain constrained by straightforward task designs and fragmented evaluation metrics that neglect complex multimodal reasoning. To bridge this gap, we introduce CLVG-Bench, an evaluation framework designed to probe video models' zero-shot reasoning capabilities via Context Learning in Video Generation. CLVG-Bench comprises more than 1,000 high-quality, manually annotated metadata across 6 categories and 47 subcategories, covering complex scenarios including physical simulation, logical reasoning, and interactive contexts. To enable rigorous and scalable assessment, we further propose an Adaptive Video Evaluator (AVE) that aligns with human expert perception using minimal annotations, delivering interpretable textual feedback across diverse video context tasks. Extensive experiments reveal a striking answer to our central question: while state-of-the-art (SOTA) video models, such as Seedance 2.0, demonstrate competence on certain understanding and reasoning subtasks, they fall substantially short with logically grounded and interactive generation tasks (achieving success rates <25% and ~0%, respectively), exposing multimodal reasoning and physical grounding as critical bottlenecks. By systematically quantifying these limitations, the proposed method provides actionable feedbacks and a clear roadmap toward truly robust, general-purpose video models. CLVG-Bench and code are released here.
AgentSwing: Adaptive Parallel Context Management Routing for Long-Horizon Web Agents
Mar 29, 2026As large language models (LLMs) evolve into autonomous agents for long-horizon information-seeking, managing finite context capacity has become a critical bottleneck. Existing context management methods typically commit to a single fixed strategy throughout the entire trajectory. Such static designs may work well in some states, but they cannot adapt as the usefulness and reliability of the accumulated context evolve during long-horizon search. To formalize this challenge, we introduce a probabilistic framework that characterizes long-horizon success through two complementary dimensions: search efficiency and terminal precision. Building on this perspective, we propose AgentSwing, a state-aware adaptive parallel context management routing framework. At each trigger point, AgentSwing expands multiple context-managed branches in parallel and uses lookahead routing to select the most promising continuation. Experiments across diverse benchmarks and agent backbones show that AgentSwing consistently outperforms strong static context management methods, often matching or exceeding their performance with up to $3\times$ fewer interaction turns while also improving the ultimate performance ceiling of long-horizon web agents. Beyond the empirical gains, the proposed probabilistic framework provides a principled lens for analyzing and designing future context management strategies for long-horizon agents.
A Feature Shuffling and Restoration Strategy for Universal Unsupervised Anomaly Detection
Mar 24, 2026Unsupervised anomaly detection is vital in industrial fields, with reconstruction-based methods favored for their simplicity and effectiveness. However, reconstruction methods often encounter an identical shortcut issue, where both normal and anomalous regions can be well reconstructed and fail to identify outliers. The severity of this problem increases with the complexity of the normal data distribution. Consequently, existing methods may exhibit excellent detection performance in a specific scenario, but their performance sharply declines when transferred to another scenario. This paper focuses on establishing a universal model applicable to anomaly detection tasks across different settings, termed as universal anomaly detection. In this work, we introduce a novel, straightforward yet efficient framework for universal anomaly detection: \uline{F}eature \uline{S}huffling and \uline{R}estoration (FSR), which can alleviate the identical shortcut issue across different settings. First and foremost, FSR employs multi-scale features with rich semantic information as reconstruction targets, rather than raw image pixels. Subsequently, these multi-scale features are partitioned into non-overlapping feature blocks, which are randomly shuffled and then restored to their original state using a restoration network. This simple paradigm encourages the model to focus more on global contextual information. Additionally, we introduce a novel concept, the shuffling rate, to regulate the complexity of the FSR task, thereby alleviating the identical shortcut across different settings. Furthermore, we provide theoretical explanations for the effectiveness of FSR framework from two perspectives: network structure and mutual information. Extensive experimental results validate the superiority and efficiency of the FSR framework across different settings.Code is available at https://github.com/luow23/FSR.
UniVBench: Towards Unified Evaluation for Video Foundation Models
Feb 25, 2026Video foundation models aim to integrate video understanding, generation, editing, and instruction following within a single framework, making them a central direction for next-generation multimodal systems. However, existing evaluation benchmarks remain fragmented and limited in scope, as they each target a single task, rely on task-specific metrics, and typically use short or simple video clips. As a result, they do not capture the unified capabilities that these models are designed to deliver. To address this gap, we introduce UniVBench, a benchmark purpose-built for evaluating video foundation models across four core abilities: video understanding, video generation, video editing, and a newly proposed task, video reconstruction, which assesses how faithfully a model can reproduce video content it has encountered. Our benchmark substantially expands the complexity of evaluation by incorporating 200 high-quality, diverse and multi-shot videos, each paired with detailed captions, multi-format editing instructions, and reference images. All videos are human-created and carefully validated, offering richer cinematic information than prior benchmarks. In addition, we develop a unified agentic evaluation system (UniV-Eval) that standardizes prompting, instruction parsing, and scoring across all tasks, enabling fair, scalable, and reproducible comparisons of unified video models. By grounding evaluation in instruction-based multi-shot video tasks, UniVBench provides the first framework for measuring the integrated capabilities that video foundation models aim to achieve. Extensive human annotations ensure our evaluation aligns with human judgment, enabling rigorous assessment and accelerating progress toward robust video intelligence.
Human-in-the-Loop Interactive Report Generation for Chronic Disease Adherence
Jan 10, 2026Chronic disease management requires regular adherence feedback to prevent avoidable hospitalizations, yet clinicians lack time to produce personalized patient communications. Manual authoring preserves clinical accuracy but does not scale; AI generation scales but can undermine trust in patient-facing contexts. We present a clinician-in-the-loop interface that constrains AI to data organization and preserves physician oversight through recognition-based review. A single-page editor pairs AI-generated section drafts with time-aligned visualizations, enabling inline editing with visual evidence for each claim. This division of labor (AI organizes, clinician decides) targets both efficiency and accountability. In a pilot with three physicians reviewing 24 cases, AI successfully generated clinically personalized drafts matching physicians' manual authoring practice (overall mean 4.86/10 vs. 5.0/10 baseline), requiring minimal physician editing (mean 8.3\% content modification) with zero safety-critical issues, demonstrating effective automation of content generation. However, review time remained comparable to manual practice, revealing an accountability paradox: in high-stakes clinical contexts, professional responsibility requires complete verification regardless of AI accuracy. We contribute three interaction patterns for clinical AI collaboration: bounded generation with recognition-based review via chart-text pairing, automated urgency flagging that analyzes vital trends and adherence patterns with fail-safe escalation for missed critical monitoring tasks, and progressive disclosure controls that reduce cognitive load while maintaining oversight. These patterns indicate that clinical AI efficiency requires not only accurate models, but also mechanisms for selective verification that preserve accountability.
SourceNet: Interpretable Sim-to-Real Inference on Variable-Geometry Sensor Arrays for Earthquake Source Inversion
Jan 09, 2026Inferring high-dimensional physical states from sparse, ad-hoc sensor arrays is a fundamental challenge across AI for Science, as they are complicated by irregular geometries and the profound Sim-to-Real gap in physical modeling. Taking earthquake source characterization as a representative challenge, we address limitations in conventional deep learning: CNNs demand fixed grids, while pooling-based architectures (e.g., DeepSets) struggle to capture the relational wave physics. Here, we propose SourceNet, a Transformer-based framework that treats the sensor array as a flexible set to model arbitrary geometries. To bridge the reality gap, we introduce Physics-Structured Domain Randomization (PSDR). Instead of forcing feature alignment, PSDR randomizes the governing physical dynamics by varying velocity structures, propagation effects, and sensor availability, to force the model to learn robust representations invariant to unmodeled environmental heterogeneity. By pre-training on 100,000 synthetic events and fine-tuning on ~2,000 real world events, SourceNet achieves state-of-the-art precision on held-out real data. This demonstrates exceptional data efficiency, and matches classical solvers while enabling real-time processing. Remarkably, interpretability analysis reveals that the model shows scientific-agent-like features: it autonomously discovers geometric information bottlenecks and learns an attention policy that prioritizes sparse sensor placements, effectively recovering principles of optimal experimental design from data alone.
Towards Proactive Personalization through Profile Customization for Individual Users in Dialogues
Dec 17, 2025The deployment of Large Language Models (LLMs) in interactive systems necessitates a deep alignment with the nuanced and dynamic preferences of individual users. Current alignment techniques predominantly address universal human values or static, single-turn preferences, thereby failing to address the critical needs of long-term personalization and the initial user cold-start problem. To bridge this gap, we propose PersonalAgent, a novel user-centric lifelong agent designed to continuously infer and adapt to user preferences. PersonalAgent constructs and dynamically refines a unified user profile by decomposing dialogues into single-turn interactions, framing preference inference as a sequential decision-making task. Experiments show that PersonalAgent achieves superior performance over strong prompt-based and policy optimization baselines, not only in idealized but also in noisy conversational contexts, while preserving cross-session preference consistency. Furthermore, human evaluation confirms that PersonalAgent excels at capturing user preferences naturally and coherently. Our findings underscore the importance of lifelong personalization for developing more inclusive and adaptive conversational agents. Our code is available here.
Med-U1: Incentivizing Unified Medical Reasoning in LLMs via Large-scale Reinforcement Learning
Jun 14, 2025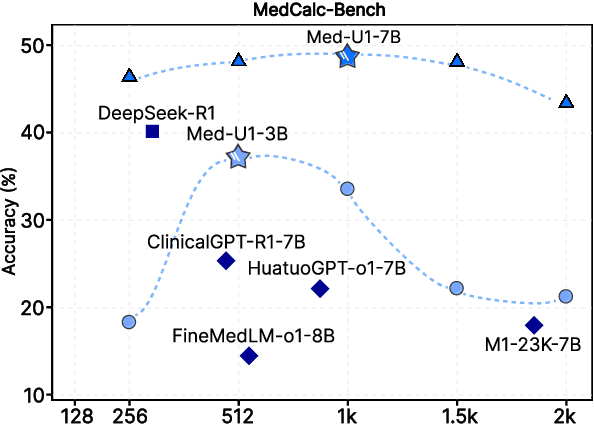
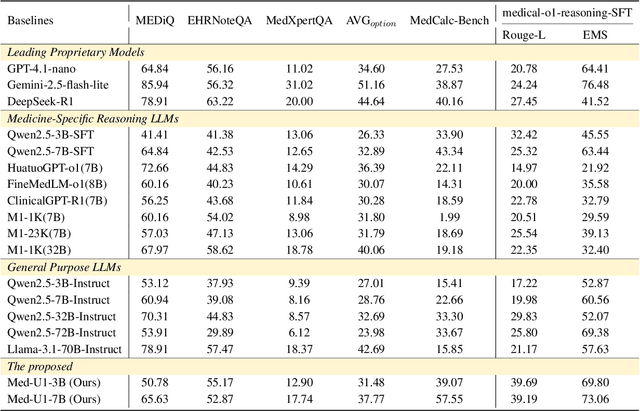
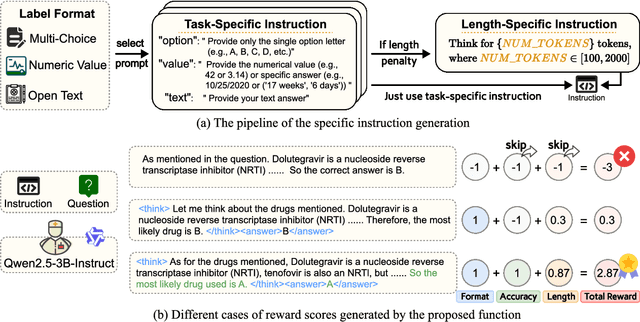
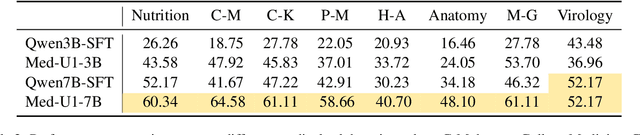
Medical Question-Answering (QA) encompasses a broad spectrum of tasks, including multiple choice questions (MCQ), open-ended text generation, and complex computational reasoning. Despite this variety, a unified framework for delivering high-quality medical QA has yet to emerge. Although recent progress in reasoning-augmented large language models (LLMs) has shown promise, their ability to achieve comprehensive medical understanding is still largely unexplored. In this paper, we present Med-U1, a unified framework for robust reasoning across medical QA tasks with diverse output formats, ranging from MCQs to complex generation and computation tasks. Med-U1 employs pure large-scale reinforcement learning with mixed rule-based binary reward functions, incorporating a length penalty to manage output verbosity. With multi-objective reward optimization, Med-U1 directs LLMs to produce concise and verifiable reasoning chains. Empirical results reveal that Med-U1 significantly improves performance across multiple challenging Med-QA benchmarks, surpassing even larger specialized and proprietary models. Furthermore, Med-U1 demonstrates robust generalization to out-of-distribution (OOD) tasks. Extensive analysis presents insights into training strategies, reasoning chain length control, and reward design for medical LLMs. The code will be released.