 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons
Feb 05, 2025The rapid advancement of large language models (LLMs) has opened new possibilities for their adoption as evaluative judges. This paper introduces Themis, a fine-tuned LLM judge that delivers sophisticated context-aware evaluations. We provide a comprehensive overview of the development pipeline for Themis, highlighting its scenario-dependent evaluation prompts and two novel methods for controlled instruction generation. These designs enable Themis to effectively distill evaluative skills from teacher models, while retaining flexibility for continuous development. We introduce two human-labeled benchmarks for meta-evaluation, demonstrating that Themis can achieve high alignment with human preferences in an economical manner. Additionally, we explore insights into the LLM-as-a-judge paradigm, revealing nuances in performance and the varied effects of reference answers. Notably, we observe that pure knowledge distillation from strong LLMs, though common, does not guarantee performance improvement through scaling. We propose a mitigation strategy based on instruction-following difficulty. Furthermore, we provide practical guidelines covering data balancing, prompt customization, multi-objective training, and metric aggregation. We aim for our method and findings, along with the fine-tuning data, benchmarks, and model checkpoints, to support future research and development in this area.
GAOKAO-MM: A Chinese Human-Level Benchmark for Multimodal Models Evaluation
Feb 24, 2024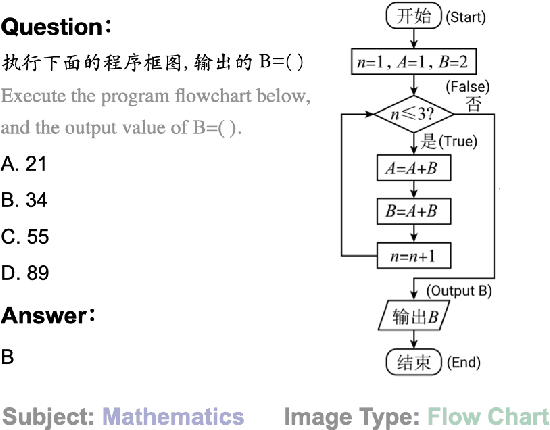
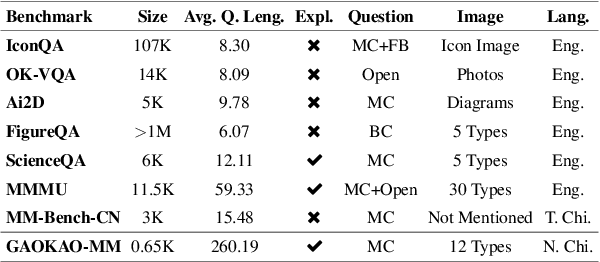
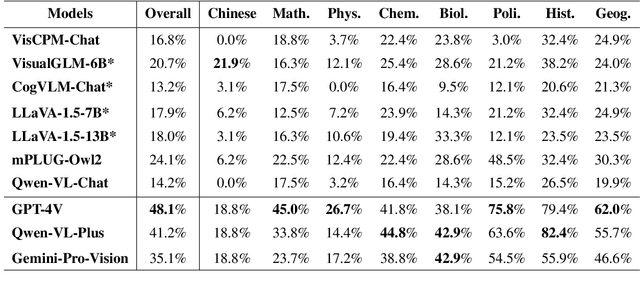
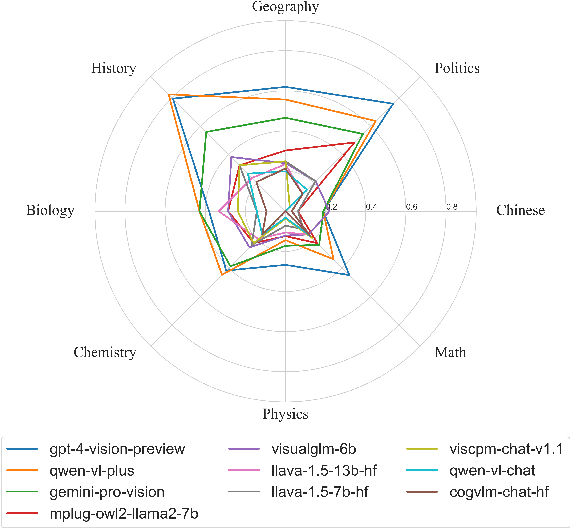
The Large Vision-Language Models (LVLMs) have demonstrated great abilities in image perception and language understanding. However, existing multimodal benchmarks focus on primary perception abilities and commonsense knowledge which are insufficient to reflect the comprehensive capabilities of LVLMs. We propose GAOKAO-MM, a multimodal benchmark based on the Chinese College Entrance Examination (GAOKAO), comprising of 8 subjects and 12 types of images, such as diagrams, function graphs, maps and photos. GAOKAO-MM derives from native Chinese context and sets human-level requirements for the model's abilities, including perception, understanding, knowledge and reasoning. We evaluate 10 LVLMs and find that the accuracies of all of them are lower than 50%, with GPT-4-Vison (48.1%), Qwen-VL-Plus (41.2%) and Gemini-Pro-Vision (35.1%) ranking in the top three positions. The results of our multi-dimension analysis indicate that LVLMs have moderate distance towards Artificial General Intelligence (AGI) and provide insights facilitating the development of multilingual LVLMs.
Evaluating the Performance of Large Language Models on GAOKAO Benchmark
May 23, 2023Large language models have demonstrated remarkable performance across various natural language processing tasks; however, their efficacy in more challenging and domain-specific tasks remains less explored. This paper introduces the GAOKAO-Benchmark (GAOKAO-Bench), an intuitive benchmark that employs questions from the Chinese Gaokao examination as test samples for evaluating large language models.In order to align the evaluation results with humans as much as possible, we designed a method based on zero-shot prompts to analyze the accuracy and scoring rate of the model by dividing the questions into subjective and objective types. We evaluated the ChatGPT model on GAOKAO-Benchmark performance.Our findings reveal that the ChatGPT model excels in tackling objective questions, while also shedding light on its shortcomings and areas for improvement. To further scrutinize the model's responses, we incorporate human evaluations.In conclusion, this research contributes a robust evaluation benchmark for future large-scale language models and offers valuable insights into the limitations of such models.