 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReRoPE: Repurposing RoPE for Relative Camera Control
Feb 08, 2026Video generation with controllable camera viewpoints is essential for applications such as interactive content creation, gaming, and simulation. Existing methods typically adapt pre-trained video models using camera poses relative to a fixed reference, e.g., the first frame. However, these encodings lack shift-invariance, often leading to poor generalization and accumulated drift. While relative camera pose embeddings defined between arbitrary view pairs offer a more robust alternative, integrating them into pre-trained video diffusion models without prohibitive training costs or architectural changes remains challenging. We introduce ReRoPE, a plug-and-play framework that incorporates relative camera information into pre-trained video diffusion models without compromising their generation capability. Our approach is based on the insight that Rotary Positional Embeddings (RoPE) in existing models underutilize their full spectral bandwidth, particularly in the low-frequency components. By seamlessly injecting relative camera pose information into these underutilized bands, ReRoPE achieves precise control while preserving strong pre-trained generative priors. We evaluate our method on both image-to-video (I2V) and video-to-video (V2V) tasks in terms of camera control accuracy and visual fidelity. Our results demonstrate that ReRoPE offers a training-efficient path toward controllable, high-fidelity video generation. See project page for more results: https://sisyphe-lee.github.io/ReRoPE/
NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems
Jan 16, 2026Accurately assessing model confidence is essential for deploying large language models (LLMs) in mission-critical factual domains. While retrieval-augmented generation (RAG) is widely adopted to improve grounding, confidence calibration in RAG settings remains poorly understood. We conduct a systematic study across four benchmarks, revealing that LLMs exhibit poor calibration performance due to noisy retrieved contexts. Specifically, contradictory or irrelevant evidence tends to inflate the model's false certainty, leading to severe overconfidence. To address this, we propose NAACL Rules (Noise-AwAre Confidence CaLibration Rules) to provide a principled foundation for resolving overconfidence under noise. We further design NAACL, a noise-aware calibration framework that synthesizes supervision from about 2K HotpotQA examples guided by these rules. By performing supervised fine-tuning (SFT) with this data, NAACL equips models with intrinsic noise awareness without relying on stronger teacher models. Empirical results show that NAACL yields substantial gains, improving ECE scores by 10.9% in-domain and 8.0% out-of-domain. By bridging the gap between retrieval noise and verbal calibration, NAACL paves the way for both accurate and epistemically reliable LLMs.
DeCo-SGD: Joint Optimization of Delay Staleness and Gradient Compression Ratio for Distributed SGD
Jul 23, 2025Distributed machine learning in high end-to-end latency and low, varying bandwidth network environments undergoes severe throughput degradation. Due to its low communication requirements, distributed SGD (D-SGD) remains the mainstream optimizer in such challenging networks, but it still suffers from significant throughput reduction. To mitigate these limitations, existing approaches typically employ gradient compression and delayed aggregation to alleviate low bandwidth and high latency, respectively. To address both challenges simultaneously, these strategies are often combined, introducing a complex three-way trade-off among compression ratio, staleness (delayed synchronization steps), and model convergence rate. To achieve the balance under varying bandwidth conditions, an adaptive policy is required to dynamically adjust these parameters. Unfortunately, existing works rely on static heuristic strategies due to the lack of theoretical guidance, which prevents them from achieving this goal. This study fills in this theoretical gap by introducing a new theoretical tool, decomposing the joint optimization problem into a traditional convergence rate analysis with multiple analyzable noise terms. We are the first to reveal that staleness exponentially amplifies the negative impact of gradient compression on training performance, filling a critical gap in understanding how compressed and delayed gradients affect training. Furthermore, by integrating the convergence rate with a network-aware time minimization condition, we propose DeCo-SGD, which dynamically adjusts the compression ratio and staleness based on the real-time network condition and training task. DeCo-SGD achieves up to 5.07 and 1.37 speed-ups over D-SGD and static strategy in high-latency and low, varying bandwidth networks, respectively.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
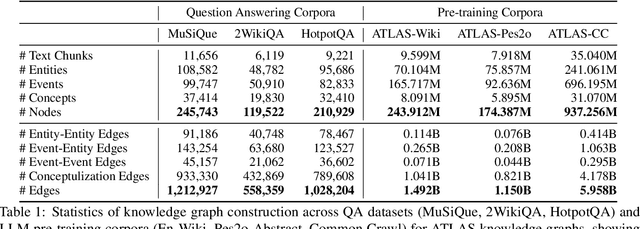
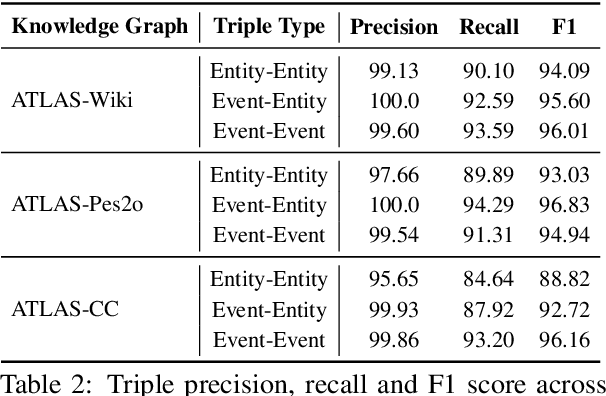

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
INFERENCEDYNAMICS: Efficient Routing Across LLMs through Structured Capability and Knowledge Profiling
May 22, 2025


Large Language Model (LLM) routing is a pivotal technique for navigating a diverse landscape of LLMs, aiming to select the best-performing LLMs tailored to the domains of user queries, while managing computational resources. However, current routing approaches often face limitations in scalability when dealing with a large pool of specialized LLMs, or in their adaptability to extending model scope and evolving capability domains. To overcome those challenges, we propose InferenceDynamics, a flexible and scalable multi-dimensional routing framework by modeling the capability and knowledge of models. We operate it on our comprehensive dataset RouteMix, and demonstrate its effectiveness and generalizability in group-level routing using modern benchmarks including MMLU-Pro, GPQA, BigGenBench, and LiveBench, showcasing its ability to identify and leverage top-performing models for given tasks, leading to superior outcomes with efficient resource utilization. The broader adoption of Inference Dynamics can empower users to harness the full specialized potential of the LLM ecosystem, and our code will be made publicly available to encourage further research.
Legal Rule Induction: Towards Generalizable Principle Discovery from Analogous Judicial Precedents
May 20, 2025Legal rules encompass not only codified statutes but also implicit adjudicatory principles derived from precedents that contain discretionary norms, social morality, and policy. While computational legal research has advanced in applying established rules to cases, inducing legal rules from judicial decisions remains understudied, constrained by limitations in model inference efficacy and symbolic reasoning capability. The advent of Large Language Models (LLMs) offers unprecedented opportunities for automating the extraction of such latent principles, yet progress is stymied by the absence of formal task definitions, benchmark datasets, and methodologies. To address this gap, we formalize Legal Rule Induction (LRI) as the task of deriving concise, generalizable doctrinal rules from sets of analogous precedents, distilling their shared preconditions, normative behaviors, and legal consequences. We introduce the first LRI benchmark, comprising 5,121 case sets (38,088 Chinese cases in total) for model tuning and 216 expert-annotated gold test sets. Experimental results reveal that: 1) State-of-the-art LLMs struggle with over-generalization and hallucination; 2) Training on our dataset markedly enhances LLMs capabilities in capturing nuanced rule patterns across similar cases.
$γ$-FedHT: Stepsize-Aware Hard-Threshold Gradient Compression in Federated Learning
May 18, 2025Gradient compression can effectively alleviate communication bottlenecks in Federated Learning (FL). Contemporary state-of-the-art sparse compressors, such as Top-$k$, exhibit high computational complexity, up to $\mathcal{O}(d\log_2{k})$, where $d$ is the number of model parameters. The hard-threshold compressor, which simply transmits elements with absolute values higher than a fixed threshold, is thus proposed to reduce the complexity to $\mathcal{O}(d)$. However, the hard-threshold compression causes accuracy degradation in FL, where the datasets are non-IID and the stepsize $\gamma$ is decreasing for model convergence. The decaying stepsize reduces the updates and causes the compression ratio of the hard-threshold compression to drop rapidly to an aggressive ratio. At or below this ratio, the model accuracy has been observed to degrade severely. To address this, we propose $\gamma$-FedHT, a stepsize-aware low-cost compressor with Error-Feedback to guarantee convergence. Given that the traditional theoretical framework of FL does not consider Error-Feedback, we introduce the fundamental conversation of Error-Feedback. We prove that $\gamma$-FedHT has the convergence rate of $\mathcal{O}(\frac{1}{T})$ ($T$ representing total training iterations) under $\mu$-strongly convex cases and $\mathcal{O}(\frac{1}{\sqrt{T}})$ under non-convex cases, \textit{same as FedAVG}. Extensive experiments demonstrate that $\gamma$-FedHT improves accuracy by up to $7.42\%$ over Top-$k$ under equal communication traffic on various non-IID image datasets.
Towards Multi-Agent Reasoning Systems for Collaborative Expertise Delegation: An Exploratory Design Study
May 12, 2025Designing effective collaboration structure for multi-agent LLM systems to enhance collective reasoning is crucial yet remains under-explored. In this paper, we systematically investigate how collaborative reasoning performance is affected by three key design dimensions: (1) Expertise-Domain Alignment, (2) Collaboration Paradigm (structured workflow vs. diversity-driven integration), and (3) System Scale. Our findings reveal that expertise alignment benefits are highly domain-contingent, proving most effective for contextual reasoning tasks. Furthermore, collaboration focused on integrating diverse knowledge consistently outperforms rigid task decomposition. Finally, we empirically explore the impact of scaling the multi-agent system with expertise specialization and study the computational trade off, highlighting the need for more efficient communication protocol design. This work provides concrete guidelines for configuring specialized multi-agent system and identifies critical architectural trade-offs and bottlenecks for scalable multi-agent reasoning. The code will be made available upon acceptance.
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning
Apr 07, 2025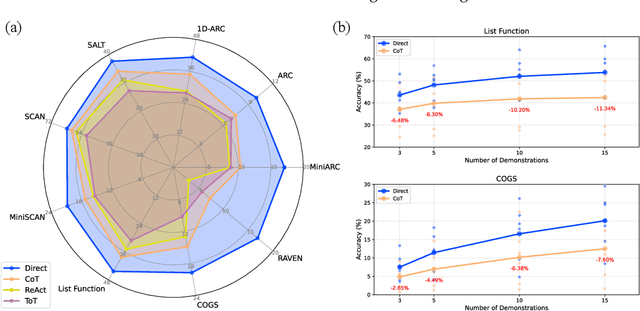
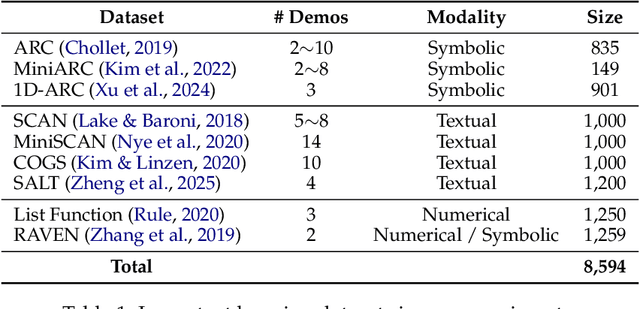
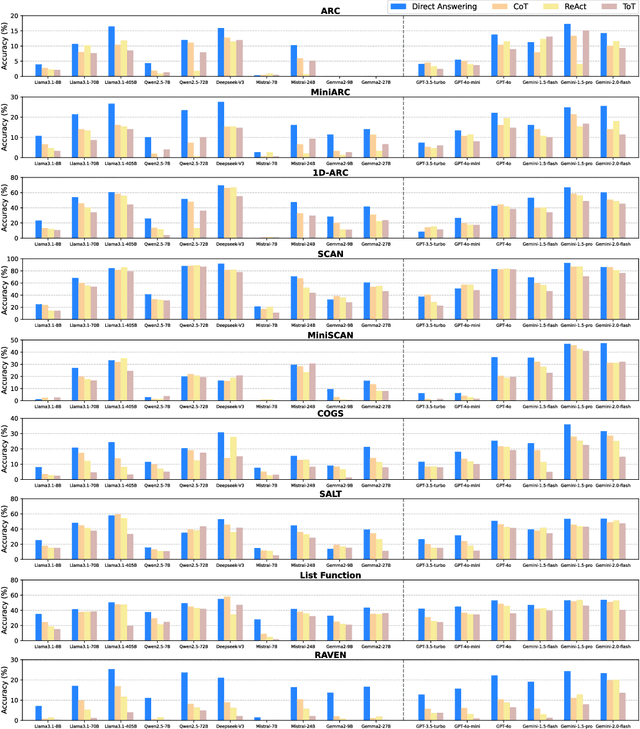
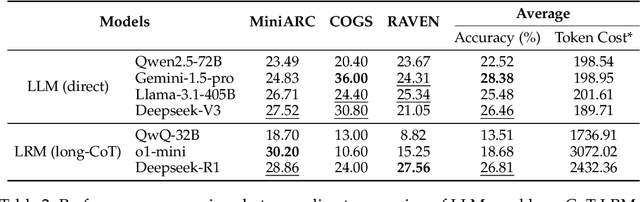
Chain-of-Thought (CoT) prompting has been widely recognized for its ability to enhance reasoning capabilities in large language models (LLMs) through the generation of explicit explanatory rationales. However, our study reveals a surprising contradiction to this prevailing perspective. Through extensive experiments involving 16 state-of-the-art LLMs and nine diverse pattern-based in-context learning (ICL) datasets, we demonstrate that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. To systematically investigate this unexpected phenomenon, we designed extensive experiments to validate several hypothetical explanations. Our analysis uncovers a fundamental explicit-implicit duality driving CoT's performance in pattern-based ICL: while explicit reasoning falters due to LLMs' struggles to infer underlying patterns from demonstrations, implicit reasoning-disrupted by the increased contextual distance of CoT rationales-often compensates, delivering correct answers despite flawed rationales. This duality explains CoT's relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes. Notably, even long-CoT reasoning models, which excel in abstract and symbolic reasoning, fail to fully overcome these limitations despite higher computational costs. Our findings challenge existing assumptions regarding the universal efficacy of CoT, yielding novel insights into its limitations and guiding future research toward more nuanced and effective reasoning methodologies for LLMs.
Patterns Over Principles: The Fragility of Inductive Reasoning in LLMs under Noisy Observations
Feb 22, 2025
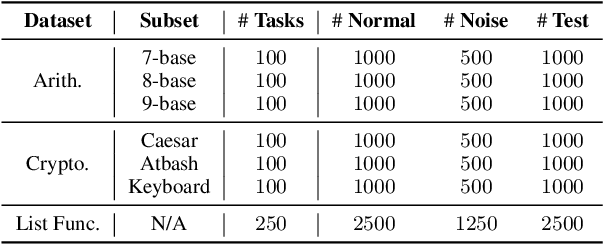
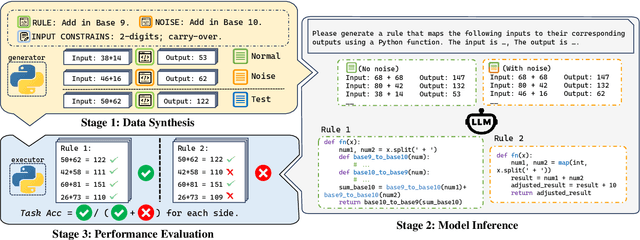
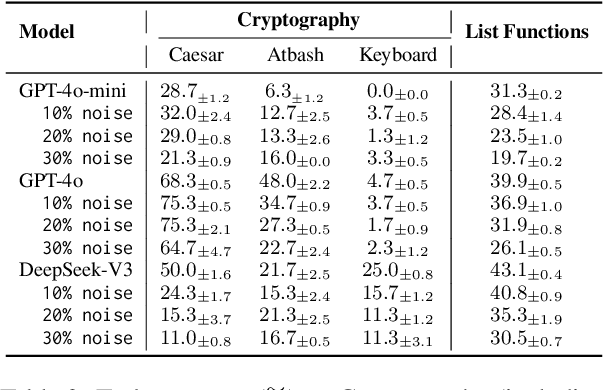
Inductive reasoning, a cornerstone of human cognition, enables generalization from limited data but hasn't yet been fully achieved by large language models (LLMs). While modern LLMs excel at reasoning tasks, their ability to maintain stable and consistent rule abstraction under imperfect observations remains underexplored. To fill this gap, in this work, we introduce Robust Rule Induction, a task that evaluates LLMs' capability in inferring rules from data that are fused with noisy examples. To address this task, we further propose Sample-steered Rule Refinement (SRR), a method enhancing reasoning stability via observation diversification and execution-guided feedback. Experiments across arithmetic, cryptography, and list functions reveal: (1) SRR outperforms other methods with minimal performance degradation under noise; (2) Despite slight accuracy variation, LLMs exhibit instability under noise (e.g., 0% accuracy change with only 70% consistent score); (3) Counterfactual task gaps highlight LLMs' reliance on memorized patterns over genuine abstraction. Our findings challenge LLMs' reasoning robustness, revealing susceptibility to hypothesis drift and pattern overfitting, while providing empirical evidence critical for developing human-like inductive systems. Code and data are available at \href{https://github.com/lcy2723/Robust-Rule-Induction}{https://github.com/lcy2723/Robust-Rule-Induction}.