 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
Jan 21, 2026Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.
LexRel: Benchmarking Legal Relation Extraction for Chinese Civil Cases
Dec 14, 2025Legal relations form a highly consequential analytical framework of civil law system, serving as a crucial foundation for resolving disputes and realizing values of the rule of law in judicial practice. However, legal relations in Chinese civil cases remain underexplored in the field of legal artificial intelligence (legal AI), largely due to the absence of comprehensive schemas. In this work, we firstly introduce a comprehensive schema, which contains a hierarchical taxonomy and definitions of arguments, for AI systems to capture legal relations in Chinese civil cases. Based on this schema, we then formulate legal relation extraction task and present LexRel, an expert-annotated benchmark for legal relation extraction in Chinese civil law. We use LexRel to evaluate state-of-the-art large language models (LLMs) on legal relation extractions, showing that current LLMs exhibit significant limitations in accurately identifying civil legal relations. Furthermore, we demonstrate that incorporating legal relations information leads to consistent performance gains on other downstream legal AI tasks.
Legal Rule Induction: Towards Generalizable Principle Discovery from Analogous Judicial Precedents
May 20, 2025Legal rules encompass not only codified statutes but also implicit adjudicatory principles derived from precedents that contain discretionary norms, social morality, and policy. While computational legal research has advanced in applying established rules to cases, inducing legal rules from judicial decisions remains understudied, constrained by limitations in model inference efficacy and symbolic reasoning capability. The advent of Large Language Models (LLMs) offers unprecedented opportunities for automating the extraction of such latent principles, yet progress is stymied by the absence of formal task definitions, benchmark datasets, and methodologies. To address this gap, we formalize Legal Rule Induction (LRI) as the task of deriving concise, generalizable doctrinal rules from sets of analogous precedents, distilling their shared preconditions, normative behaviors, and legal consequences. We introduce the first LRI benchmark, comprising 5,121 case sets (38,088 Chinese cases in total) for model tuning and 216 expert-annotated gold test sets. Experimental results reveal that: 1) State-of-the-art LLMs struggle with over-generalization and hallucination; 2) Training on our dataset markedly enhances LLMs capabilities in capturing nuanced rule patterns across similar cases.
JUREX-4E: Juridical Expert-Annotated Four-Element Knowledge Base for Legal Reasoning
Feb 24, 2025The Four-Element Theory is a fundamental framework in criminal law, defining the constitution of crime through four dimensions: Subject, Object, Subjective aspect, and Objective aspect. This theory is widely referenced in legal reasoning, and many Large Language Models (LLMs) attempt to incorporate it when handling legal tasks. However, current approaches rely on LLMs' internal knowledge to incorporate this theory, often lacking completeness and representativeness. To address this limitation, we introduce JUREX-4E, an expert-annotated knowledge base covering 155 criminal charges. It is structured through a progressive hierarchical annotation framework that prioritizes legal source validity and employs diverse legal interpretation methods to ensure comprehensiveness and authority. We evaluate JUREX-4E on the Similar Charge Distinction task and apply it to Legal Case Retrieval, demonstrating its effectiveness in improving LLM performance. Experimental results validate the high quality of JUREX-4E and its substantial impact on downstream legal tasks, underscoring its potential for advancing legal AI applications. Code: https://github.com/THUlawtech/JUREX
STARD: A Chinese Statute Retrieval Dataset with Real Queries Issued by Non-professionals
Jun 21, 2024Statute retrieval aims to find relevant statutory articles for specific queries. This process is the basis of a wide range of legal applications such as legal advice, automated judicial decisions, legal document drafting, etc. Existing statute retrieval benchmarks focus on formal and professional queries from sources like bar exams and legal case documents, thereby neglecting non-professional queries from the general public, which often lack precise legal terminology and references. To address this gap, we introduce the STAtute Retrieval Dataset (STARD), a Chinese dataset comprising 1,543 query cases collected from real-world legal consultations and 55,348 candidate statutory articles. Unlike existing statute retrieval datasets, which primarily focus on professional legal queries, STARD captures the complexity and diversity of real queries from the general public. Through a comprehensive evaluation of various retrieval baselines, we reveal that existing retrieval approaches all fall short of these real queries issued by non-professional users. The best method only achieves a Recall@100 of 0.907, suggesting the necessity for further exploration and additional research in this area. All the codes and datasets are available at: https://github.com/oneal2000/STARD/tree/main
MUSER: A Multi-View Similar Case Retrieval Dataset
Oct 24, 2023
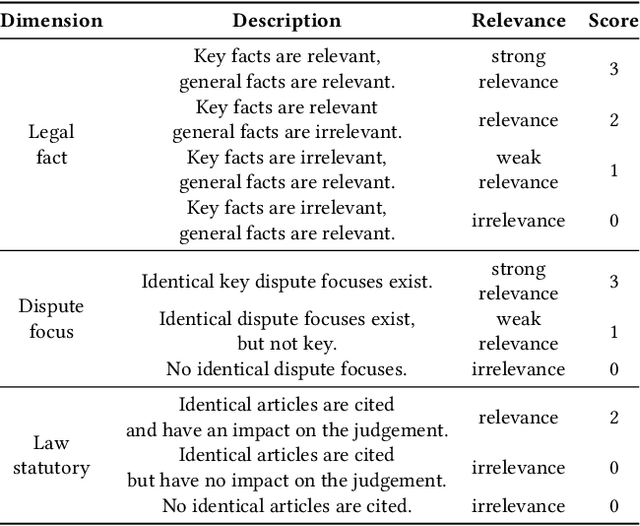

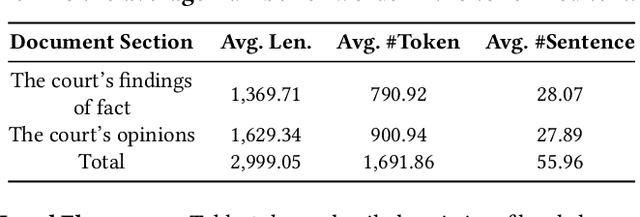
Similar case retrieval (SCR) is a representative legal AI application that plays a pivotal role in promoting judicial fairness. However, existing SCR datasets only focus on the fact description section when judging the similarity between cases, ignoring other valuable sections (e.g., the court's opinion) that can provide insightful reasoning process behind. Furthermore, the case similarities are typically measured solely by the textual semantics of the fact descriptions, which may fail to capture the full complexity of legal cases from the perspective of legal knowledge. In this work, we present MUSER, a similar case retrieval dataset based on multi-view similarity measurement and comprehensive legal element with sentence-level legal element annotations. Specifically, we select three perspectives (legal fact, dispute focus, and law statutory) and build a comprehensive and structured label schema of legal elements for each of them, to enable accurate and knowledgeable evaluation of case similarities. The constructed dataset originates from Chinese civil cases and contains 100 query cases and 4,024 candidate cases. We implement several text classification algorithms for legal element prediction and various retrieval methods for retrieving similar cases on MUSER. The experimental results indicate that incorporating legal elements can benefit the performance of SCR models, but further efforts are still required to address the remaining challenges posed by MUSER. The source code and dataset are released at https://github.com/THUlawtech/MUSER.
* Accepted by CIKM 2023 Resource Track
The Devil is in the Details: On the Pitfalls of Event Extraction Evaluation
Jun 15, 2023Event extraction (EE) is a crucial task aiming at extracting events from texts, which includes two subtasks: event detection (ED) and event argument extraction (EAE). In this paper, we check the reliability of EE evaluations and identify three major pitfalls: (1) The data preprocessing discrepancy makes the evaluation results on the same dataset not directly comparable, but the data preprocessing details are not widely noted and specified in papers. (2) The output space discrepancy of different model paradigms makes different-paradigm EE models lack grounds for comparison and also leads to unclear mapping issues between predictions and annotations. (3) The absence of pipeline evaluation of many EAE-only works makes them hard to be directly compared with EE works and may not well reflect the model performance in real-world pipeline scenarios. We demonstrate the significant influence of these pitfalls through comprehensive meta-analyses of recent papers and empirical experiments. To avoid these pitfalls, we suggest a series of remedies, including specifying data preprocessing, standardizing outputs, and providing pipeline evaluation results. To help implement these remedies, we develop a consistent evaluation framework OMNIEVENT, which can be obtained from https://github.com/THU-KEG/OmniEvent.
LEVEN: A Large-Scale Chinese Legal Event Detection Dataset
Mar 16, 2022Recognizing facts is the most fundamental step in making judgments, hence detecting events in the legal documents is important to legal case analysis tasks. However, existing Legal Event Detection (LED) datasets only concern incomprehensive event types and have limited annotated data, which restricts the development of LED methods and their downstream applications. To alleviate these issues, we present LEVEN a large-scale Chinese LEgal eVENt detection dataset, with 8,116 legal documents and 150,977 human-annotated event mentions in 108 event types. Not only charge-related events, LEVEN also covers general events, which are critical for legal case understanding but neglected in existing LED datasets. To our knowledge, LEVEN is the largest LED dataset and has dozens of times the data scale of others, which shall significantly promote the training and evaluation of LED methods. The results of extensive experiments indicate that LED is challenging and needs further effort. Moreover, we simply utilize legal events as side information to promote downstream applications. The method achieves improvements of average 2.2 points precision in low-resource judgment prediction, and 1.5 points mean average precision in unsupervised case retrieval, which suggests the fundamentality of LED. The source code and dataset can be obtained from https://github.com/thunlp/LEVEN.