 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
Jan 21, 2026Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.
STARD: A Chinese Statute Retrieval Dataset with Real Queries Issued by Non-professionals
Jun 21, 2024Statute retrieval aims to find relevant statutory articles for specific queries. This process is the basis of a wide range of legal applications such as legal advice, automated judicial decisions, legal document drafting, etc. Existing statute retrieval benchmarks focus on formal and professional queries from sources like bar exams and legal case documents, thereby neglecting non-professional queries from the general public, which often lack precise legal terminology and references. To address this gap, we introduce the STAtute Retrieval Dataset (STARD), a Chinese dataset comprising 1,543 query cases collected from real-world legal consultations and 55,348 candidate statutory articles. Unlike existing statute retrieval datasets, which primarily focus on professional legal queries, STARD captures the complexity and diversity of real queries from the general public. Through a comprehensive evaluation of various retrieval baselines, we reveal that existing retrieval approaches all fall short of these real queries issued by non-professional users. The best method only achieves a Recall@100 of 0.907, suggesting the necessity for further exploration and additional research in this area. All the codes and datasets are available at: https://github.com/oneal2000/STARD/tree/main
Graph Regularized Nonnegative Tensor Ring Decomposition for Multiway Representation Learning
Oct 12, 2020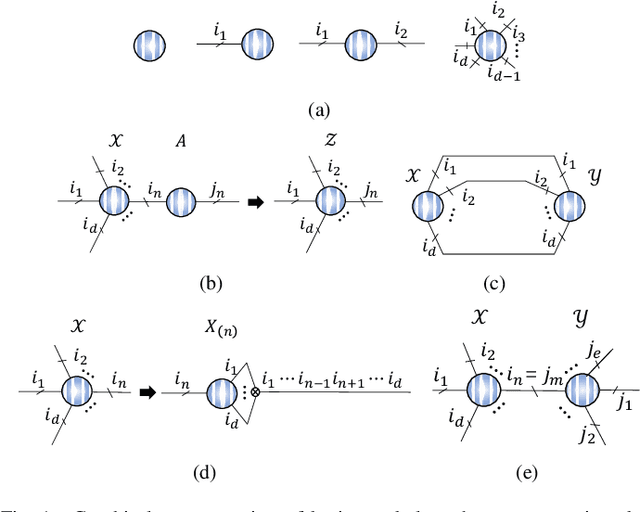
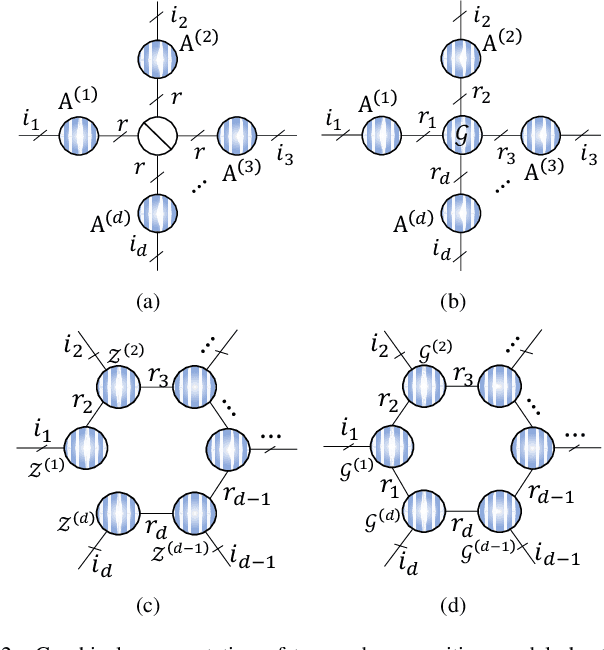
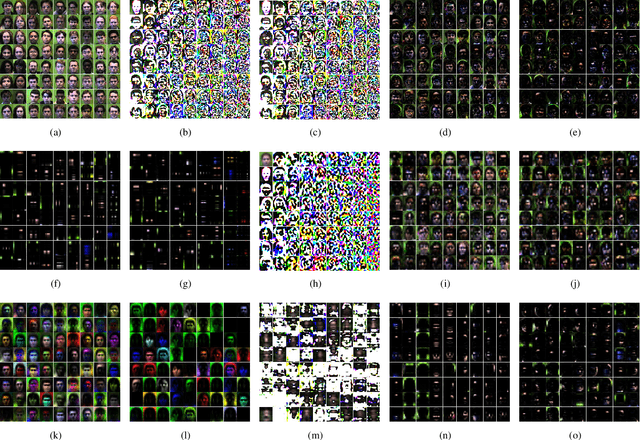
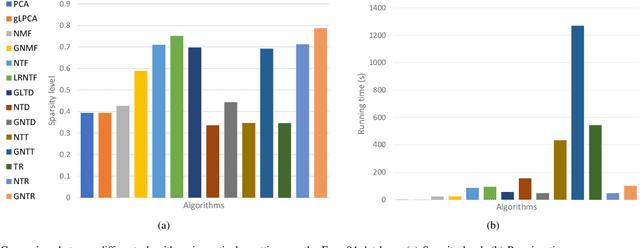
Tensor ring (TR) decomposition is a powerful tool for exploiting the low-rank nature of multiway data and has demonstrated great potential in a variety of important applications. In this paper, nonnegative tensor ring (NTR) decomposition and graph regularized NTR (GNTR) decomposition are proposed, where the former equips TR decomposition with local feature extraction by imposing nonnegativity on the core tensors and the latter is additionally able to capture manifold geometry information of tensor data, both significantly extend the applications of TR decomposition for nonnegative multiway representation learning. Accelerated proximal gradient based methods are derived for NTR and GNTR. The experimental result demonstrate that the proposed algorithms can extract parts-based basis with rich colors and rich lines from tensor objects that provide more interpretable and meaningful representation, and hence yield better performance than the state-of-the-art tensor based methods in clustering and classification tasks.