 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Paradoxical Interference between Instruction-Following and Task Solving
Jan 29, 2026Instruction following aims to align Large Language Models (LLMs) with human intent by specifying explicit constraints on how tasks should be performed. However, we reveal a counterintuitive phenomenon: instruction following can paradoxically interfere with LLMs' task-solving capability. We propose a metric, SUSTAINSCORE, to quantify the interference of instruction following with task solving. It measures task performance drop after inserting into the instruction a self-evident constraint, which is naturally met by the original successful model output and extracted from it. Experiments on current LLMs in mathematics, multi-hop QA, and code generation show that adding the self-evident constraints leads to substantial performance drops, even for advanced models such as Claude-Sonnet-4.5. We validate the generality of the interference across constraint types and scales. Furthermore, we identify common failure patterns, and by investigating the mechanisms of interference, we observe that failed cases allocate significantly more attention to constraints compared to successful ones. Finally, we use SUSTAINSCORE to conduct an initial investigation into how distinct post-training paradigms affect the interference, presenting empirical observations on current alignment strategies. We will release our code and data to facilitate further research
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Jun 11, 2025Reinforcement learning with verifiable rewards (RLVR) has become a key technique for enhancing large language models (LLMs), with verification engineering playing a central role. However, best practices for RL in instruction following remain underexplored. In this work, we explore the verification challenge in RL for instruction following and propose VerIF, a verification method that combines rule-based code verification with LLM-based verification from a large reasoning model (e.g., QwQ-32B). To support this approach, we construct a high-quality instruction-following dataset, VerInstruct, containing approximately 22,000 instances with associated verification signals. We apply RL training with VerIF to two models, achieving significant improvements across several representative instruction-following benchmarks. The trained models reach state-of-the-art performance among models of comparable size and generalize well to unseen constraints. We further observe that their general capabilities remain unaffected, suggesting that RL with VerIF can be integrated into existing RL recipes to enhance overall model performance. We have released our datasets, codes, and models to facilitate future research at https://github.com/THU-KEG/VerIF.
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
May 22, 2025Large Language Models (LLMs) have demonstrated advanced capabilities in real-world agentic applications. Growing research efforts aim to develop LLM-based agents to address practical demands, introducing a new challenge: agentic scenarios often involve lengthy instructions with complex constraints, such as extended system prompts and detailed tool specifications. While adherence to such instructions is crucial for agentic applications, whether LLMs can reliably follow them remains underexplored. In this paper, we introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. To construct AgentIF, we collect 707 human-annotated instructions across 50 agentic tasks from industrial application agents and open-source agentic systems. For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation. We use AgentIF to systematically evaluate existing advanced LLMs. We observe that current models generally perform poorly, especially in handling complex constraint structures and tool specifications. We further conduct error analysis and analytical experiments on instruction length and meta constraints, providing some findings about the failure modes of existing LLMs. We have released the code and data to facilitate future research.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025



Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Precise Localization of Memories: A Fine-grained Neuron-level Knowledge Editing Technique for LLMs
Mar 03, 2025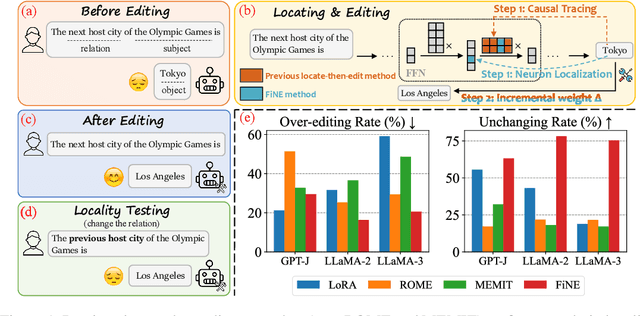
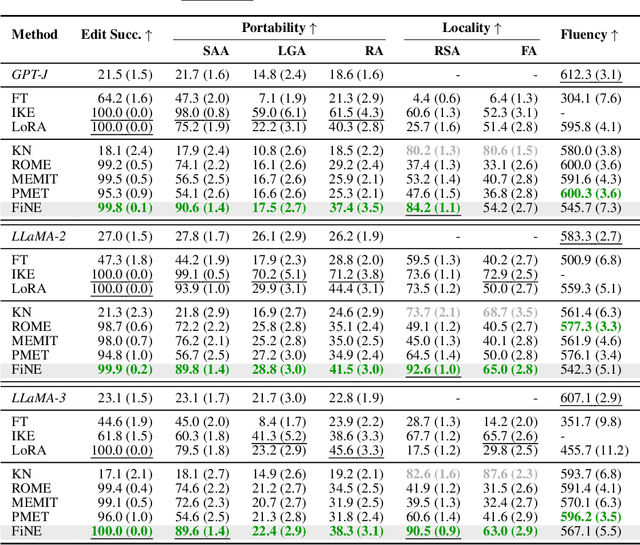
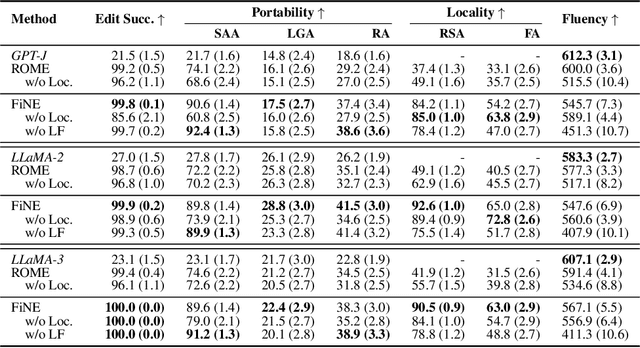
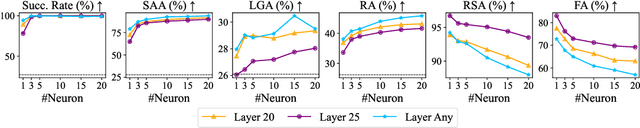
Knowledge editing aims to update outdated information in Large Language Models (LLMs). A representative line of study is locate-then-edit methods, which typically employ causal tracing to identify the modules responsible for recalling factual knowledge about entities. However, we find these methods are often sensitive only to changes in the subject entity, leaving them less effective at adapting to changes in relations. This limitation results in poor editing locality, which can lead to the persistence of irrelevant or inaccurate facts, ultimately compromising the reliability of LLMs. We believe this issue arises from the insufficient precision of knowledge localization. To address this, we propose a Fine-grained Neuron-level Knowledge Editing (FiNE) method that enhances editing locality without affecting overall success rates. By precisely identifying and modifying specific neurons within feed-forward networks, FiNE significantly improves knowledge localization and editing. Quantitative experiments demonstrate that FiNE efficiently achieves better overall performance compared to existing techniques, providing new insights into the localization and modification of knowledge within LLMs.
Sparse Auto-Encoder Interprets Linguistic Features in Large Language Models
Feb 27, 2025Large language models (LLMs) excel in tasks that require complex linguistic abilities, such as reference disambiguation and metaphor recognition/generation. Although LLMs possess impressive capabilities, their internal mechanisms for processing and representing linguistic knowledge remain largely opaque. Previous work on linguistic mechanisms has been limited by coarse granularity, insufficient causal analysis, and a narrow focus. In this study, we present a systematic and comprehensive causal investigation using sparse auto-encoders (SAEs). We extract a wide range of linguistic features from six dimensions: phonetics, phonology, morphology, syntax, semantics, and pragmatics. We extract, evaluate, and intervene on these features by constructing minimal contrast datasets and counterfactual sentence datasets. We introduce two indices-Feature Representation Confidence (FRC) and Feature Intervention Confidence (FIC)-to measure the ability of linguistic features to capture and control linguistic phenomena. Our results reveal inherent representations of linguistic knowledge in LLMs and demonstrate the potential for controlling model outputs. This work provides strong evidence that LLMs possess genuine linguistic knowledge and lays the foundation for more interpretable and controllable language modeling in future research.
Agentic Reward Modeling: Integrating Human Preferences with Verifiable Correctness Signals for Reliable Reward Systems
Feb 26, 2025Reward models (RMs) are crucial for the training and inference-time scaling up of large language models (LLMs). However, existing reward models primarily focus on human preferences, neglecting verifiable correctness signals which have shown strong potential in training LLMs. In this paper, we propose agentic reward modeling, a reward system that combines reward models with verifiable correctness signals from different aspects to provide reliable rewards. We empirically implement a reward agent, named RewardAgent, that combines human preference rewards with two verifiable signals: factuality and instruction following, to provide more reliable rewards. We conduct comprehensive experiments on existing reward model benchmarks and inference time best-of-n searches on real-world downstream tasks. RewardAgent significantly outperforms vanilla reward models, demonstrating its effectiveness. We further construct training preference pairs using RewardAgent and train an LLM with the DPO objective, achieving superior performance on various NLP benchmarks compared to conventional reward models. Our codes are publicly released to facilitate further research (https://github.com/THU-KEG/Agentic-Reward-Modeling).
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Dec 19, 2024



This paper introduces LongBench v2, a benchmark designed to assess the ability of LLMs to handle long-context problems requiring deep understanding and reasoning across real-world multitasks. LongBench v2 consists of 503 challenging multiple-choice questions, with contexts ranging from 8k to 2M words, across six major task categories: single-document QA, multi-document QA, long in-context learning, long-dialogue history understanding, code repository understanding, and long structured data understanding. To ensure the breadth and the practicality, we collect data from nearly 100 highly educated individuals with diverse professional backgrounds. We employ both automated and manual review processes to maintain high quality and difficulty, resulting in human experts achieving only 53.7% accuracy under a 15-minute time constraint. Our evaluation reveals that the best-performing model, when directly answers the questions, achieves only 50.1% accuracy. In contrast, the o1-preview model, which includes longer reasoning, achieves 57.7%, surpassing the human baseline by 4%. These results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2. The project is available at https://longbench2.github.io.
Constraint Back-translation Improves Complex Instruction Following of Large Language Models
Oct 31, 2024



Large language models (LLMs) struggle to follow instructions with complex constraints in format, length, etc. Following the conventional instruction-tuning practice, previous works conduct post-training on complex instruction-response pairs generated by feeding complex instructions to advanced LLMs. However, even advanced LLMs cannot follow complex instructions well, thus limiting the quality of generated data. In this work, we find that existing datasets inherently contain implicit complex constraints and propose a novel data generation technique, constraint back-translation. Specifically, we take the high-quality instruction-response pairs in existing datasets and only adopt advanced LLMs to add complex constraints already met by the responses to the instructions, which naturally reduces costs and data noise. In the experiments, we adopt Llama3-70B-Instruct to back-translate constraints and create a high-quality complex instruction-response dataset, named CRAB. We present that post-training on CRAB improves multiple backbone LLMs' complex instruction-following ability, evaluated on extensive instruction-following benchmarks. We further find that constraint back-translation also serves as a useful auxiliary training objective in post-training. Our code, data, and models will be released to facilitate future research.
Configurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.