 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadFM: Foundational Text-Driven Quadruped Motion Dataset for Generation and Control
Mar 25, 2026Despite significant advances in quadrupedal robotics, a critical gap persists in foundational motion resources that holistically integrate diverse locomotion, emotionally expressive behaviors, and rich language semantics-essential for agile, intuitive human-robot interaction. Current quadruped motion datasets are limited to a few mocap primitives (e.g., walk, trot, sit) and lack diverse behaviors with rich language grounding. To bridge this gap, we introduce Quadruped Foundational Motion (QuadFM) , the first large-scale, ultra-high-fidelity dataset designed for text-to-motion generation and general motion control. QuadFM contains 11,784 curated motion clips spanning locomotion, interactive, and emotion-expressive behaviors (e.g., dancing, stretching, peeing), each with three-layer annotation-fine-grained action labels, interaction scenarios, and natural language commands-totaling 35,352 descriptions to support language-conditioned understanding and command execution. We further propose Gen2Control RL, a unified framework that jointly trains a general motion controller and a text-to-motion generator, enabling efficient end-to-end inference on edge hardware. On a real quadruped robot with an NVIDIA Orin, our system achieves real-time motion synthesis (<500 ms latency). Simulation and real-world results show realistic, diverse motions while maintaining robust physical interaction. The dataset will be released at https://github.com/GaoLii/QuadFM.
Mechanistic Data Attribution: Tracing the Training Origins of Interpretable LLM Units
Jan 29, 2026While Mechanistic Interpretability has identified interpretable circuits in LLMs, their causal origins in training data remain elusive. We introduce Mechanistic Data Attribution (MDA), a scalable framework that employs Influence Functions to trace interpretable units back to specific training samples. Through extensive experiments on the Pythia family, we causally validate that targeted intervention--removing or augmenting a small fraction of high-influence samples--significantly modulates the emergence of interpretable heads, whereas random interventions show no effect. Our analysis reveals that repetitive structural data (e.g., LaTeX, XML) acts as a mechanistic catalyst. Furthermore, we observe that interventions targeting induction head formation induce a concurrent change in the model's in-context learning (ICL) capability. This provides direct causal evidence for the long-standing hypothesis regarding the functional link between induction heads and ICL. Finally, we propose a mechanistic data augmentation pipeline that consistently accelerates circuit convergence across model scales, providing a principled methodology for steering the developmental trajectories of LLMs.
Are Reasoning Models More Prone to Hallucination?
May 29, 2025Recently evolved large reasoning models (LRMs) show powerful performance in solving complex tasks with long chain-of-thought (CoT) reasoning capability. As these LRMs are mostly developed by post-training on formal reasoning tasks, whether they generalize the reasoning capability to help reduce hallucination in fact-seeking tasks remains unclear and debated. For instance, DeepSeek-R1 reports increased performance on SimpleQA, a fact-seeking benchmark, while OpenAI-o3 observes even severer hallucination. This discrepancy naturally raises the following research question: Are reasoning models more prone to hallucination? This paper addresses the question from three perspectives. (1) We first conduct a holistic evaluation for the hallucination in LRMs. Our analysis reveals that LRMs undergo a full post-training pipeline with cold start supervised fine-tuning (SFT) and verifiable reward RL generally alleviate their hallucination. In contrast, both distillation alone and RL training without cold start fine-tuning introduce more nuanced hallucinations. (2) To explore why different post-training pipelines alters the impact on hallucination in LRMs, we conduct behavior analysis. We characterize two critical cognitive behaviors that directly affect the factuality of a LRM: Flaw Repetition, where the surface-level reasoning attempts repeatedly follow the same underlying flawed logic, and Think-Answer Mismatch, where the final answer fails to faithfully match the previous CoT process. (3) Further, we investigate the mechanism behind the hallucination of LRMs from the perspective of model uncertainty. We find that increased hallucination of LRMs is usually associated with the misalignment between model uncertainty and factual accuracy. Our work provides an initial understanding of the hallucination in LRMs.
Finding Safety Neurons in Large Language Models
Jun 20, 2024



Large language models (LLMs) excel in various capabilities but also pose safety risks such as generating harmful content and misinformation, even after safety alignment. In this paper, we explore the inner mechanisms of safety alignment from the perspective of mechanistic interpretability, focusing on identifying and analyzing safety neurons within LLMs that are responsible for safety behaviors. We propose generation-time activation contrasting to locate these neurons and dynamic activation patching to evaluate their causal effects. Experiments on multiple recent LLMs show that: (1) Safety neurons are sparse and effective. We can restore $90$% safety performance with intervention only on about $5$% of all the neurons. (2) Safety neurons encode transferrable mechanisms. They exhibit consistent effectiveness on different red-teaming datasets. The finding of safety neurons also interprets "alignment tax". We observe that the identified key neurons for safety and helpfulness significantly overlap, but they require different activation patterns of the shared neurons. Furthermore, we demonstrate an application of safety neurons in detecting unsafe outputs before generation. Our findings may promote further research on understanding LLM alignment. The source codes will be publicly released to facilitate future research.
Root Causing Prediction Anomalies Using Explainable AI
Mar 04, 2024


This paper presents a novel application of explainable AI (XAI) for root-causing performance degradation in machine learning models that learn continuously from user engagement data. In such systems a single feature corruption can cause cascading feature, label and concept drifts. We have successfully applied this technique to improve the reliability of models used in personalized advertising. Performance degradation in such systems manifest as prediction anomalies in the models. These models are typically trained continuously using features that are produced by hundreds of real time data processing pipelines or derived from other upstream models. A failure in any of these pipelines or an instability in any of the upstream models can cause feature corruption, causing the model's predicted output to deviate from the actual output and the training data to become corrupted. The causal relationship between the features and the predicted output is complex, and root-causing is challenging due to the scale and dynamism of the system. We demonstrate how temporal shifts in the global feature importance distribution can effectively isolate the cause of a prediction anomaly, with better recall than model-to-feature correlation methods. The technique appears to be effective even when approximating the local feature importance using a simple perturbation-based method, and aggregating over a few thousand examples. We have found this technique to be a model-agnostic, cheap and effective way to monitor complex data pipelines in production and have deployed a system for continuously analyzing the global feature importance distribution of continuously trained models.
When does In-context Learning Fall Short and Why? A Study on Specification-Heavy Tasks
Nov 15, 2023In-context learning (ICL) has become the default method for using large language models (LLMs), making the exploration of its limitations and understanding the underlying causes crucial. In this paper, we find that ICL falls short of handling specification-heavy tasks, which are tasks with complicated and extensive task specifications, requiring several hours for ordinary humans to master, such as traditional information extraction tasks. The performance of ICL on these tasks mostly cannot reach half of the state-of-the-art results. To explore the reasons behind this failure, we conduct comprehensive experiments on 18 specification-heavy tasks with various LLMs and identify three primary reasons: inability to specifically understand context, misalignment in task schema comprehension with humans, and inadequate long-text understanding ability. Furthermore, we demonstrate that through fine-tuning, LLMs can achieve decent performance on these tasks, indicating that the failure of ICL is not an inherent flaw of LLMs, but rather a drawback of existing alignment methods that renders LLMs incapable of handling complicated specification-heavy tasks via ICL. To substantiate this, we perform dedicated instruction tuning on LLMs for these tasks and observe a notable improvement. We hope the analyses in this paper could facilitate advancements in alignment methods enabling LLMs to meet more sophisticated human demands.
MAVEN-Arg: Completing the Puzzle of All-in-One Event Understanding Dataset with Event Argument Annotation
Nov 15, 2023



Understanding events in texts is a core objective of natural language understanding, which requires detecting event occurrences, extracting event arguments, and analyzing inter-event relationships. However, due to the annotation challenges brought by task complexity, a large-scale dataset covering the full process of event understanding has long been absent. In this paper, we introduce MAVEN-Arg, which augments MAVEN datasets with event argument annotations, making the first all-in-one dataset supporting event detection, event argument extraction (EAE), and event relation extraction. As an EAE benchmark, MAVEN-Arg offers three main advantages: (1) a comprehensive schema covering 162 event types and 612 argument roles, all with expert-written definitions and examples; (2) a large data scale, containing 98,591 events and 290,613 arguments obtained with laborious human annotation; (3) the exhaustive annotation supporting all task variants of EAE, which annotates both entity and non-entity event arguments in document level. Experiments indicate that MAVEN-Arg is quite challenging for both fine-tuned EAE models and proprietary large language models (LLMs). Furthermore, to demonstrate the benefits of an all-in-one dataset, we preliminarily explore a potential application, future event prediction, with LLMs. MAVEN-Arg and our code can be obtained from https://github.com/THU-KEG/MAVEN-Argument.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023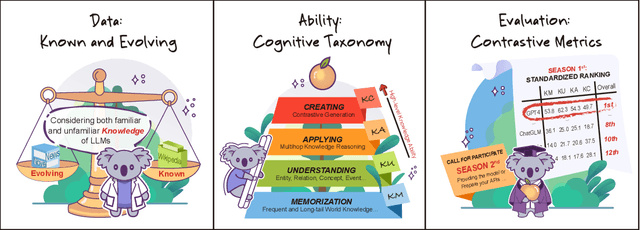
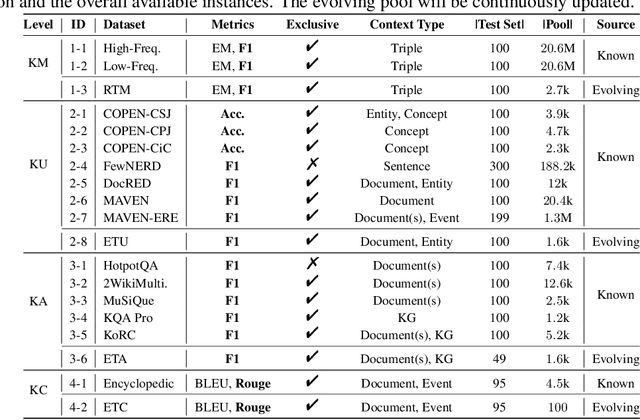
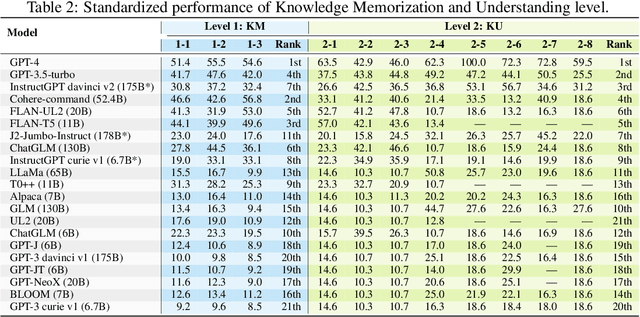

The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
BabelCalib: A Universal Approach to Calibrating Central Cameras
Sep 20, 2021

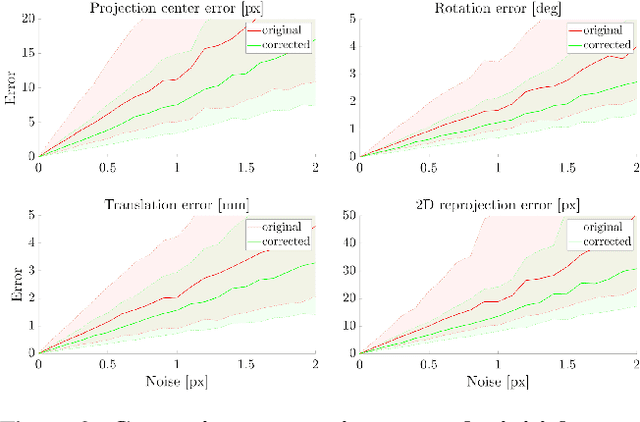
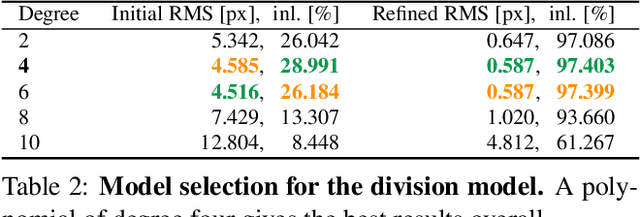
Existing calibration methods occasionally fail for large field-of-view cameras due to the non-linearity of the underlying problem and the lack of good initial values for all parameters of the used camera model. This might occur because a simpler projection model is assumed in an initial step, or a poor initial guess for the internal parameters is pre-defined. A lot of the difficulties of general camera calibration lie in the use of a forward projection model. We side-step these challenges by first proposing a solver to calibrate the parameters in terms of a back-projection model and then regress the parameters for a target forward model. These steps are incorporated in a robust estimation framework to cope with outlying detections. Extensive experiments demonstrate that our approach is very reliable and returns the most accurate calibration parameters as measured on the downstream task of absolute pose estimation on test sets. The code is released at https://github.com/ylochman/babelcalib.
Adapting Grad-CAM for Embedding Networks
Jan 17, 2020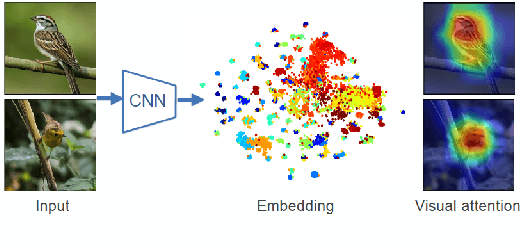

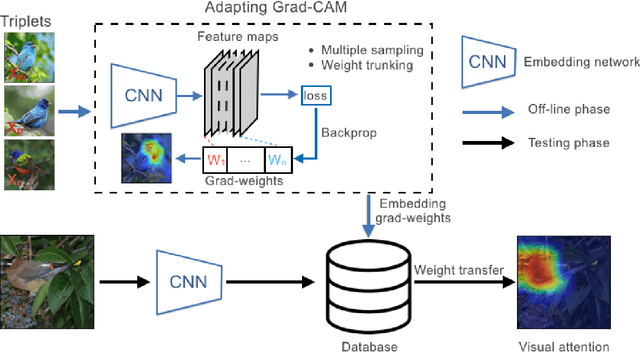
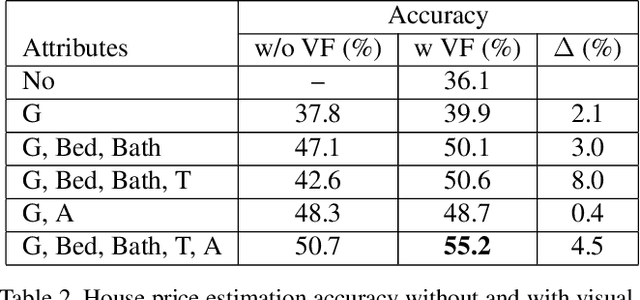
The gradient-weighted class activation mapping (Grad-CAM) method can faithfully highlight important regions in images for deep model prediction in image classification, image captioning and many other tasks. It uses the gradients in back-propagation as weights (grad-weights) to explain network decisions. However, applying Grad-CAM to embedding networks raises significant challenges because embedding networks are trained by millions of dynamically paired examples (e.g. triplets). To overcome these challenges, we propose an adaptation of the Grad-CAM method for embedding networks. First, we aggregate grad-weights from multiple training examples to improve the stability of Grad-CAM. Then, we develop an efficient weight-transfer method to explain decisions for any image without back-propagation. We extensively validate the method on the standard CUB200 dataset in which our method produces more accurate visual attention than the original Grad-CAM method. We also apply the method to a house price estimation application using images. The method produces convincing qualitative results, showcasing the practicality of our approach.