 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Grad-CAM for Embedding Networks
Paper and Code
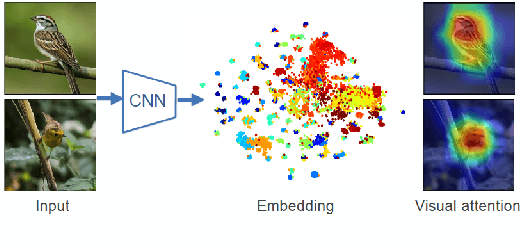

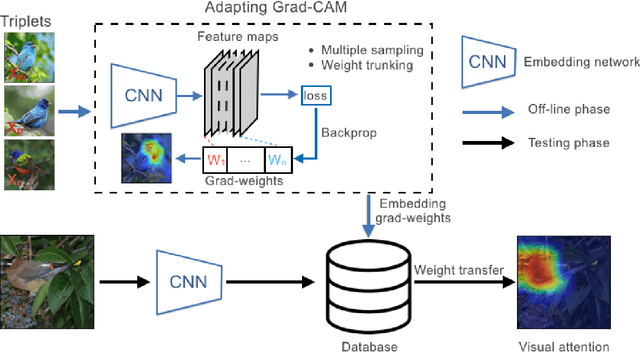
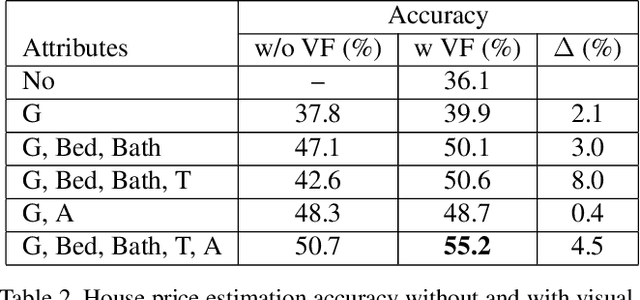
The gradient-weighted class activation mapping (Grad-CAM) method can faithfully highlight important regions in images for deep model prediction in image classification, image captioning and many other tasks. It uses the gradients in back-propagation as weights (grad-weights) to explain network decisions. However, applying Grad-CAM to embedding networks raises significant challenges because embedding networks are trained by millions of dynamically paired examples (e.g. triplets). To overcome these challenges, we propose an adaptation of the Grad-CAM method for embedding networks. First, we aggregate grad-weights from multiple training examples to improve the stability of Grad-CAM. Then, we develop an efficient weight-transfer method to explain decisions for any image without back-propagation. We extensively validate the method on the standard CUB200 dataset in which our method produces more accurate visual attention than the original Grad-CAM method. We also apply the method to a house price estimation application using images. The method produces convincing qualitative results, showcasing the practicality of our approach.