 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation
Mar 27, 2025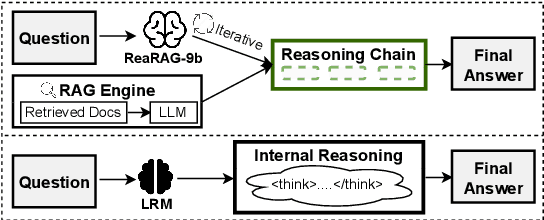
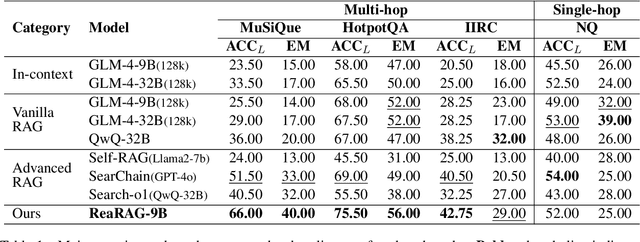
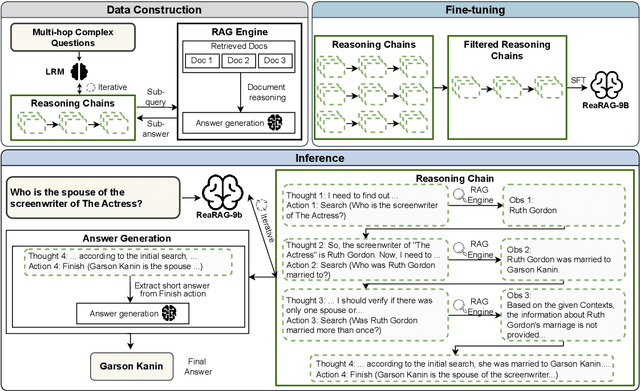

Large Reasoning Models (LRMs) exhibit remarkable reasoning abilities but rely primarily on parametric knowledge, limiting factual accuracy. While recent works equip reinforcement learning (RL)-based LRMs with retrieval capabilities, they suffer from overthinking and lack robustness in reasoning, reducing their effectiveness in question answering (QA) tasks. To address this, we propose ReaRAG, a factuality-enhanced reasoning model that explores diverse queries without excessive iterations. Our solution includes a novel data construction framework with an upper bound on the reasoning chain length. Specifically, we first leverage an LRM to generate deliberate thinking, then select an action from a predefined action space (Search and Finish). For Search action, a query is executed against the RAG engine, where the result is returned as observation to guide reasoning steps later. This process iterates until a Finish action is chosen. Benefiting from ReaRAG's strong reasoning capabilities, our approach outperforms existing baselines on multi-hop QA. Further analysis highlights its strong reflective ability to recognize errors and refine its reasoning trajectory. Our study enhances LRMs' factuality while effectively integrating robust reasoning for Retrieval-Augmented Generation (RAG).
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Dec 19, 2024



This paper introduces LongBench v2, a benchmark designed to assess the ability of LLMs to handle long-context problems requiring deep understanding and reasoning across real-world multitasks. LongBench v2 consists of 503 challenging multiple-choice questions, with contexts ranging from 8k to 2M words, across six major task categories: single-document QA, multi-document QA, long in-context learning, long-dialogue history understanding, code repository understanding, and long structured data understanding. To ensure the breadth and the practicality, we collect data from nearly 100 highly educated individuals with diverse professional backgrounds. We employ both automated and manual review processes to maintain high quality and difficulty, resulting in human experts achieving only 53.7% accuracy under a 15-minute time constraint. Our evaluation reveals that the best-performing model, when directly answers the questions, achieves only 50.1% accuracy. In contrast, the o1-preview model, which includes longer reasoning, achieves 57.7%, surpassing the human baseline by 4%. These results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2. The project is available at https://longbench2.github.io.
AtomR: Atomic Operator-Empowered Large Language Models for Heterogeneous Knowledge Reasoning
Nov 25, 2024



Recent advancements in large language models (LLMs) have led to significant improvements in various natural language processing tasks, but it is still challenging for LLMs to perform knowledge-intensive complex question answering due to LLMs' inefficacy in reasoning planning and the hallucination problem. A typical solution is to employ retrieval-augmented generation (RAG) coupled with chain-of-thought (CoT) reasoning, which decomposes complex questions into chain-like sub-questions and applies iterative RAG at each sub-question. However, prior works exhibit sub-optimal reasoning planning and overlook dynamic knowledge retrieval from heterogeneous sources. In this paper, we propose AtomR, a novel heterogeneous knowledge reasoning framework that conducts multi-source reasoning at the atomic level. Drawing inspiration from the graph modeling of knowledge, AtomR leverages large language models (LLMs) to decompose complex questions into combinations of three atomic knowledge operators, significantly enhancing the reasoning process at both the planning and execution stages. We also introduce BlendQA, a novel evaluation benchmark tailored to assess complex heterogeneous knowledge reasoning. Experiments show that AtomR significantly outperforms state-of-the-art baselines across three single-source and two multi-source reasoning benchmarks, with notable performance gains of 9.4% on 2WikiMultihop and 9.5% on BlendQA.
LongReward: Improving Long-context Large Language Models with AI Feedback
Oct 28, 2024Though significant advancements have been achieved in developing long-context large language models (LLMs), the compromised quality of LLM-synthesized data for supervised fine-tuning (SFT) often affects the long-context performance of SFT models and leads to inherent limitations. In principle, reinforcement learning (RL) with appropriate reward signals can further enhance models' capacities. However, how to obtain reliable rewards in long-context scenarios remains unexplored. To this end, we propose LongReward, a novel method that utilizes an off-the-shelf LLM to provide rewards for long-context model responses from four human-valued dimensions: helpfulness, logicality, faithfulness, and completeness, each with a carefully designed assessment pipeline. By combining LongReward and offline RL algorithm DPO, we are able to effectively improve long-context SFT models. Our experiments indicate that LongReward not only significantly improves models' long-context performance but also enhances their ability to follow short instructions. We also find that long-context DPO with LongReward and conventional short-context DPO can be used together without hurting either one's performance.
LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA
Sep 04, 2024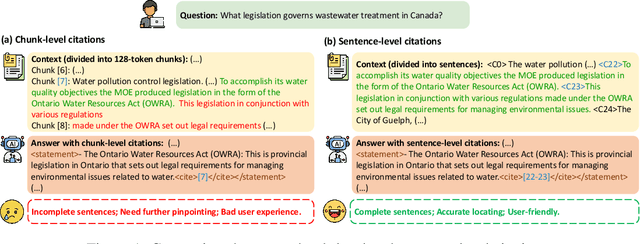


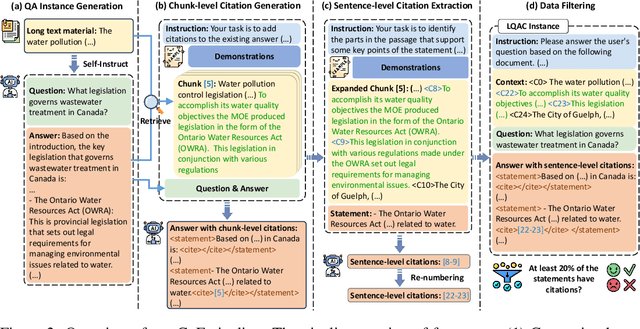
Though current long-context large language models (LLMs) have demonstrated impressive capacities in answering user questions based on extensive text, the lack of citations in their responses makes user verification difficult, leading to concerns about their trustworthiness due to their potential hallucinations. In this work, we aim to enable long-context LLMs to generate responses with fine-grained sentence-level citations, improving their faithfulness and verifiability. We first introduce LongBench-Cite, an automated benchmark for assessing current LLMs' performance in Long-Context Question Answering with Citations (LQAC), revealing considerable room for improvement. To this end, we propose CoF (Coarse to Fine), a novel pipeline that utilizes off-the-shelf LLMs to automatically generate long-context QA instances with precise sentence-level citations, and leverage this pipeline to construct LongCite-45k, a large-scale SFT dataset for LQAC. Finally, we train LongCite-8B and LongCite-9B using the LongCite-45k dataset, successfully enabling their generation of accurate responses and fine-grained sentence-level citations in a single output. The evaluation results on LongBench-Cite show that our trained models achieve state-of-the-art citation quality, surpassing advanced proprietary models including GPT-4o.
SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation
Jun 27, 2024



This paper introduces Self-aware Knowledge Retrieval (SeaKR), a novel adaptive RAG model that extracts self-aware uncertainty of LLMs from their internal states. SeaKR activates retrieval when the LLMs present high self-aware uncertainty for generation. To effectively integrate retrieved knowledge snippets, SeaKR re-ranks them based on LLM's self-aware uncertainty to preserve the snippet that reduces their uncertainty to the utmost. To facilitate solving complex tasks that require multiple retrievals, SeaKR utilizes their self-aware uncertainty to choose among different reasoning strategies. Our experiments on both complex and simple Question Answering datasets show that SeaKR outperforms existing adaptive RAG methods. We release our code at https://github.com/THU-KEG/SeaKR.
Aligning Teacher with Student Preferences for Tailored Training Data Generation
Jun 27, 2024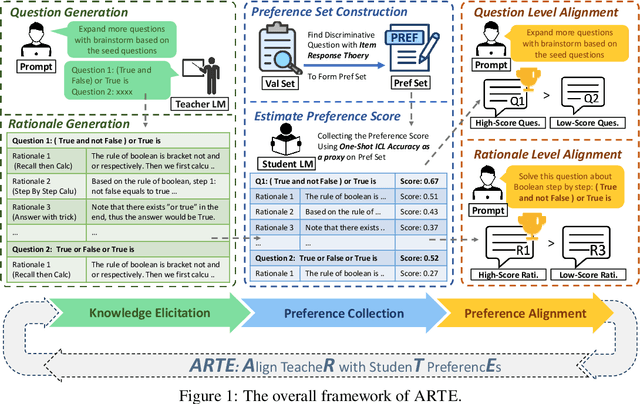



Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to "responsive teaching" in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024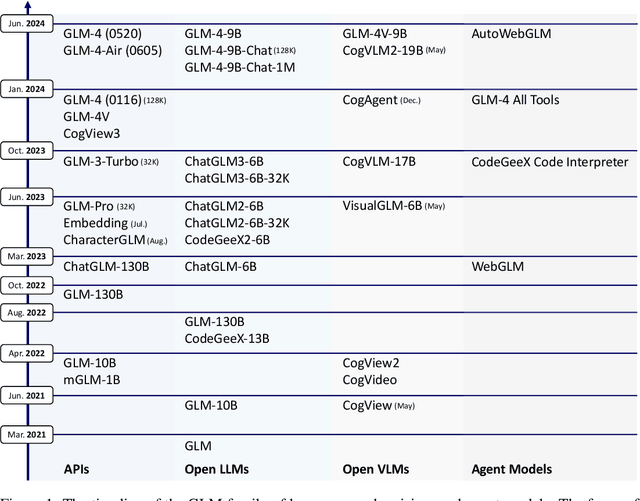
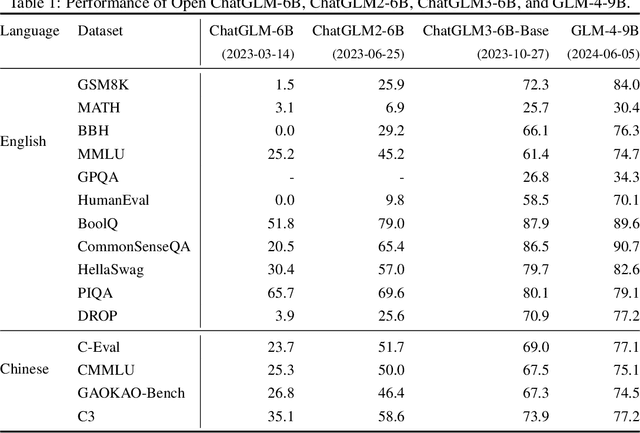
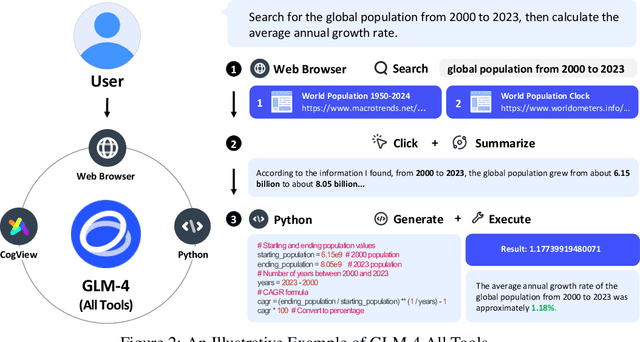
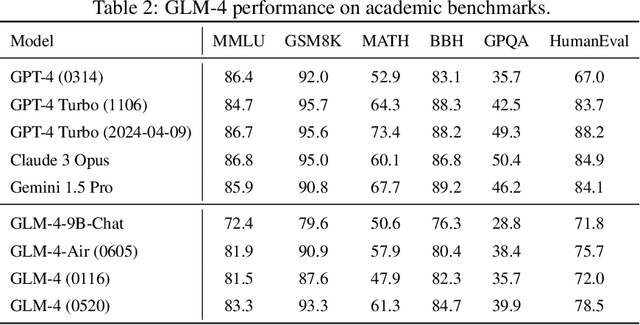
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
Untangle the KNOT: Interweaving Conflicting Knowledge and Reasoning Skills in Large Language Models
Apr 04, 2024Providing knowledge documents for large language models (LLMs) has emerged as a promising solution to update the static knowledge inherent in their parameters. However, knowledge in the document may conflict with the memory of LLMs due to outdated or incorrect knowledge in the LLMs' parameters. This leads to the necessity of examining the capability of LLMs to assimilate supplemental external knowledge that conflicts with their memory. While previous studies have explained to what extent LLMs extract conflicting knowledge from the provided text, they neglect the necessity to reason with conflicting knowledge. Furthermore, there lack a detailed analysis on strategies to enable LLMs to resolve conflicting knowledge via prompting, decoding strategy, and supervised fine-tuning. To address these limitations, we construct a new dataset, dubbed KNOT, for knowledge conflict resolution examination in the form of question answering. KNOT facilitates in-depth analysis by dividing reasoning with conflicting knowledge into three levels: (1) Direct Extraction, which directly extracts conflicting knowledge to answer questions. (2) Explicit Reasoning, which reasons with conflicting knowledge when the reasoning path is explicitly provided in the question. (3) Implicit Reasoning, where reasoning with conflicting knowledge requires LLMs to infer the reasoning path independently to answer questions. We also conduct extensive experiments on KNOT to establish empirical guidelines for LLMs to utilize conflicting knowledge in complex circumstances. Dataset and associated codes can be accessed at https://github.com/THU-KEG/KNOT .