 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation
Mar 27, 2025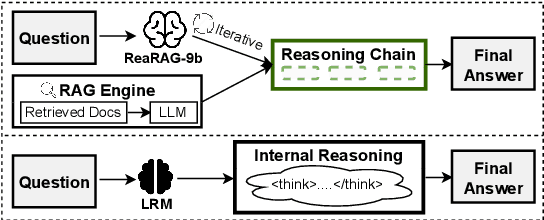
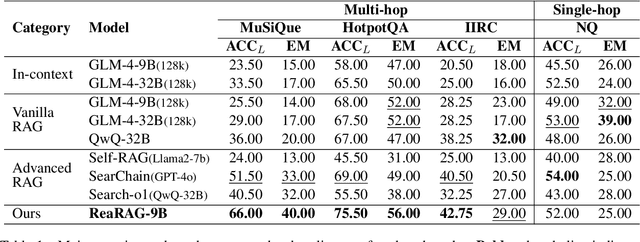
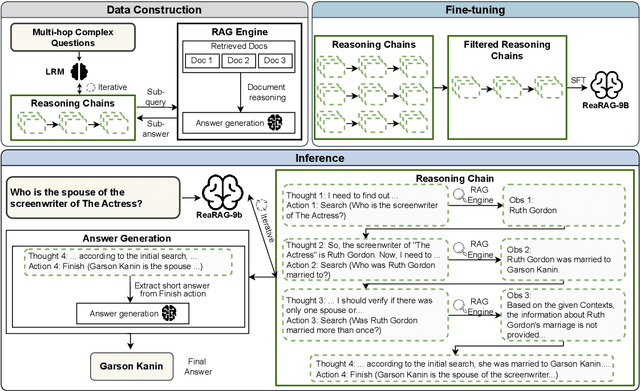

Large Reasoning Models (LRMs) exhibit remarkable reasoning abilities but rely primarily on parametric knowledge, limiting factual accuracy. While recent works equip reinforcement learning (RL)-based LRMs with retrieval capabilities, they suffer from overthinking and lack robustness in reasoning, reducing their effectiveness in question answering (QA) tasks. To address this, we propose ReaRAG, a factuality-enhanced reasoning model that explores diverse queries without excessive iterations. Our solution includes a novel data construction framework with an upper bound on the reasoning chain length. Specifically, we first leverage an LRM to generate deliberate thinking, then select an action from a predefined action space (Search and Finish). For Search action, a query is executed against the RAG engine, where the result is returned as observation to guide reasoning steps later. This process iterates until a Finish action is chosen. Benefiting from ReaRAG's strong reasoning capabilities, our approach outperforms existing baselines on multi-hop QA. Further analysis highlights its strong reflective ability to recognize errors and refine its reasoning trajectory. Our study enhances LRMs' factuality while effectively integrating robust reasoning for Retrieval-Augmented Generation (RAG).
Improving Text Embeddings for Smaller Language Models Using Contrastive Fine-tuning
Aug 02, 2024



While Large Language Models show remarkable performance in natural language understanding, their resource-intensive nature makes them less accessible. In contrast, smaller language models such as MiniCPM offer more sustainable scalability, but often underperform without specialized optimization. In this paper, we explore the enhancement of smaller language models through the improvement of their text embeddings. We select three language models, MiniCPM, Phi-2, and Gemma, to conduct contrastive fine-tuning on the NLI dataset. Our results demonstrate that this fine-tuning method enhances the quality of text embeddings for all three models across various benchmarks, with MiniCPM showing the most significant improvements of an average 56.33% performance gain. The contrastive fine-tuning code is publicly available at https://github.com/trapoom555/Language-Model-STS-CFT.