 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards
Jan 09, 2026Reinforcement learning (RL) has emerged as a critical technique for enhancing LLM-based deep search agents. However, existing approaches primarily rely on binary outcome rewards, which fail to capture the comprehensiveness and factuality of agents' reasoning process, and often lead to undesirable behaviors such as shortcut exploitation and hallucinations. To address these limitations, we propose \textbf{Citation-aware Rubric Rewards (CaRR)}, a fine-grained reward framework for deep search agents that emphasizes reasoning comprehensiveness, factual grounding, and evidence connectivity. CaRR decomposes complex questions into verifiable single-hop rubrics and requires agents to satisfy these rubrics by explicitly identifying hidden entities, supporting them with correct citations, and constructing complete evidence chains that link to the predicted answer. We further introduce \textbf{Citation-aware Group Relative Policy Optimization (C-GRPO)}, which combines CaRR and outcome rewards for training robust deep search agents. Experiments show that C-GRPO consistently outperforms standard outcome-based RL baselines across multiple deep search benchmarks. Our analysis also validates that C-GRPO effectively discourages shortcut exploitation, promotes comprehensive, evidence-grounded reasoning, and exhibits strong generalization to open-ended deep research tasks. Our code and data are available at https://github.com/THUDM/CaRR.
Cross-Level Sensor Fusion with Object Lists via Transformer for 3D Object Detection
Dec 14, 2025In automotive sensor fusion systems, smart sensors and Vehicle-to-Everything (V2X) modules are commonly utilized. Sensor data from these systems are typically available only as processed object lists rather than raw sensor data from traditional sensors. Instead of processing other raw data separately and then fusing them at the object level, we propose an end-to-end cross-level fusion concept with Transformer, which integrates highly abstract object list information with raw camera images for 3D object detection. Object lists are fed into a Transformer as denoising queries and propagated together with learnable queries through the latter feature aggregation process. Additionally, a deformable Gaussian mask, derived from the positional and size dimensional priors from the object lists, is explicitly integrated into the Transformer decoder. This directs attention toward the target area of interest and accelerates model training convergence. Furthermore, as there is no public dataset containing object lists as a standalone modality, we propose an approach to generate pseudo object lists from ground-truth bounding boxes by simulating state noise and false positives and negatives. As the first work to conduct cross-level fusion, our approach shows substantial performance improvements over the vision-based baseline on the nuScenes dataset. It demonstrates its generalization capability over diverse noise levels of simulated object lists and real detectors.
* 6 pages, 3 figures, accepted at IV2025
WiFi-based Global Localization in Large-Scale Environments Leveraging Structural Priors from osmAG
Aug 13, 2025Global localization is essential for autonomous robotics, especially in indoor environments where the GPS signal is denied. We propose a novel WiFi-based localization framework that leverages ubiquitous wireless infrastructure and the OpenStreetMap Area Graph (osmAG) for large-scale indoor environments. Our approach integrates signal propagation modeling with osmAG's geometric and topological priors. In the offline phase, an iterative optimization algorithm localizes WiFi Access Points (APs) by modeling wall attenuation, achieving a mean localization error of 3.79 m (35.3\% improvement over trilateration). In the online phase, real-time robot localization uses the augmented osmAG map, yielding a mean error of 3.12 m in fingerprinted areas (8.77\% improvement over KNN fingerprinting) and 3.83 m in non-fingerprinted areas (81.05\% improvement). Comparison with a fingerprint-based method shows that our approach is much more space efficient and achieves superior localization accuracy, especially for positions where no fingerprint data are available. Validated across a complex 11,025 &m^2& multi-floor environment, this framework offers a scalable, cost-effective solution for indoor robotic localization, solving the kidnapped robot problem. The code and dataset are available at https://github.com/XuMa369/osmag-wifi-localization.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Hard Negative Contrastive Learning for Fine-Grained Geometric Understanding in Large Multimodal Models
May 26, 2025Benefiting from contrastively trained visual encoders on large-scale natural scene images, Large Multimodal Models (LMMs) have achieved remarkable performance across various visual perception tasks. However, the inherent limitations of contrastive learning upon summarized descriptions fundamentally restrict the capabilities of models in meticulous reasoning, particularly in crucial scenarios of geometric problem-solving. To enhance geometric understanding, we propose a novel hard negative contrastive learning framework for the vision encoder, which combines image-based contrastive learning using generation-based hard negatives created by perturbing diagram generation code, and text-based contrastive learning using rule-based negatives derived from modified geometric descriptions and retrieval-based negatives selected based on caption similarity. We train CLIP using our strong negative learning method, namely MMCLIP (Multimodal Math CLIP), and subsequently train an LMM for geometric problem-solving. Experiments show that our trained model, MMGeoLM, significantly outperforms other open-source models on three geometric reasoning benchmarks. Even with a size of 7B, it can rival powerful closed-source models like GPT-4o. We further study the impact of different negative sample construction methods and the number of negative samples on the geometric reasoning performance of LMM, yielding fruitful conclusions. The code and dataset are available at https://github.com/THU-KEG/MMGeoLM.
AdaptThink: Reasoning Models Can Learn When to Think
May 19, 2025Recently, large reasoning models have achieved impressive performance on various tasks by employing human-like deep thinking. However, the lengthy thinking process substantially increases inference overhead, making efficiency a critical bottleneck. In this work, we first demonstrate that NoThinking, which prompts the reasoning model to skip thinking and directly generate the final solution, is a better choice for relatively simple tasks in terms of both performance and efficiency. Motivated by this, we propose AdaptThink, a novel RL algorithm to teach reasoning models to choose the optimal thinking mode adaptively based on problem difficulty. Specifically, AdaptThink features two core components: (1) a constrained optimization objective that encourages the model to choose NoThinking while maintaining the overall performance; (2) an importance sampling strategy that balances Thinking and NoThinking samples during on-policy training, thereby enabling cold start and allowing the model to explore and exploit both thinking modes throughout the training process. Our experiments indicate that AdaptThink significantly reduces the inference costs while further enhancing performance. Notably, on three math datasets, AdaptThink reduces the average response length of DeepSeek-R1-Distill-Qwen-1.5B by 53% and improves its accuracy by 2.4%, highlighting the promise of adaptive thinking-mode selection for optimizing the balance between reasoning quality and efficiency. Our codes and models are available at https://github.com/THU-KEG/AdaptThink.
ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation
Mar 27, 2025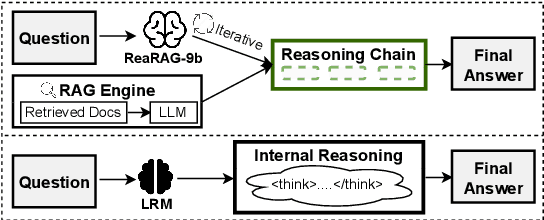
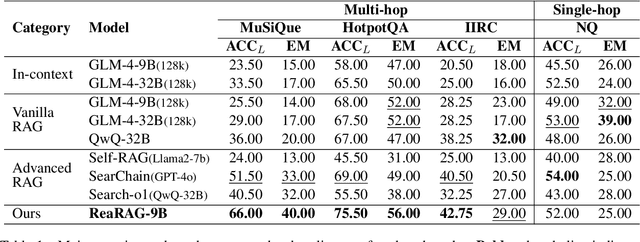
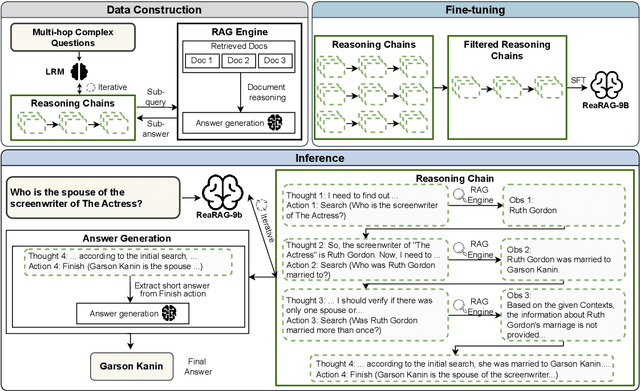

Large Reasoning Models (LRMs) exhibit remarkable reasoning abilities but rely primarily on parametric knowledge, limiting factual accuracy. While recent works equip reinforcement learning (RL)-based LRMs with retrieval capabilities, they suffer from overthinking and lack robustness in reasoning, reducing their effectiveness in question answering (QA) tasks. To address this, we propose ReaRAG, a factuality-enhanced reasoning model that explores diverse queries without excessive iterations. Our solution includes a novel data construction framework with an upper bound on the reasoning chain length. Specifically, we first leverage an LRM to generate deliberate thinking, then select an action from a predefined action space (Search and Finish). For Search action, a query is executed against the RAG engine, where the result is returned as observation to guide reasoning steps later. This process iterates until a Finish action is chosen. Benefiting from ReaRAG's strong reasoning capabilities, our approach outperforms existing baselines on multi-hop QA. Further analysis highlights its strong reflective ability to recognize errors and refine its reasoning trajectory. Our study enhances LRMs' factuality while effectively integrating robust reasoning for Retrieval-Augmented Generation (RAG).
TUMTraffic-VideoQA: A Benchmark for Unified Spatio-Temporal Video Understanding in Traffic Scenes
Feb 04, 2025



We present TUMTraffic-VideoQA, a novel dataset and benchmark designed for spatio-temporal video understanding in complex roadside traffic scenarios. The dataset comprises 1,000 videos, featuring 85,000 multiple-choice QA pairs, 2,300 object captioning, and 5,700 object grounding annotations, encompassing diverse real-world conditions such as adverse weather and traffic anomalies. By incorporating tuple-based spatio-temporal object expressions, TUMTraffic-VideoQA unifies three essential tasks-multiple-choice video question answering, referred object captioning, and spatio-temporal object grounding-within a cohesive evaluation framework. We further introduce the TUMTraffic-Qwen baseline model, enhanced with visual token sampling strategies, providing valuable insights into the challenges of fine-grained spatio-temporal reasoning. Extensive experiments demonstrate the dataset's complexity, highlight the limitations of existing models, and position TUMTraffic-VideoQA as a robust foundation for advancing research in intelligent transportation systems. The dataset and benchmark are publicly available to facilitate further exploration.
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
Jan 20, 2025



Large language models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks. However, existing approaches mainly rely on imitation learning and struggle to achieve effective test-time scaling. While reinforcement learning (RL) holds promise for enabling self-exploration and learning from feedback, recent attempts yield only modest improvements in complex reasoning. In this paper, we present T1 to scale RL by encouraging exploration and understand inference scaling. We first initialize the LLM using synthesized chain-of-thought data that integrates trial-and-error and self-verification. To scale RL training, we promote increased sampling diversity through oversampling. We further employ an entropy bonus as an auxiliary loss, alongside a dynamic anchor for regularization to facilitate reward optimization. We demonstrate that T1 with open LLMs as its base exhibits inference scaling behavior and achieves superior performance on challenging math reasoning benchmarks. For example, T1 with Qwen2.5-32B as the base model outperforms the recent Qwen QwQ-32B-Preview model on MATH500, AIME2024, and Omni-math-500. More importantly, we present a simple strategy to examine inference scaling, where increased inference budgets directly lead to T1's better performance without any additional verification. We will open-source the T1 models and the data used to train them at \url{https://github.com/THUDM/T1}.
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Dec 19, 2024



This paper introduces LongBench v2, a benchmark designed to assess the ability of LLMs to handle long-context problems requiring deep understanding and reasoning across real-world multitasks. LongBench v2 consists of 503 challenging multiple-choice questions, with contexts ranging from 8k to 2M words, across six major task categories: single-document QA, multi-document QA, long in-context learning, long-dialogue history understanding, code repository understanding, and long structured data understanding. To ensure the breadth and the practicality, we collect data from nearly 100 highly educated individuals with diverse professional backgrounds. We employ both automated and manual review processes to maintain high quality and difficulty, resulting in human experts achieving only 53.7% accuracy under a 15-minute time constraint. Our evaluation reveals that the best-performing model, when directly answers the questions, achieves only 50.1% accuracy. In contrast, the o1-preview model, which includes longer reasoning, achieves 57.7%, surpassing the human baseline by 4%. These results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2. The project is available at https://longbench2.github.io.