 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthVision: Robust Vision-Language Understanding through GAN-Based LiDAR-to-RGB Synthesis
Sep 09, 2025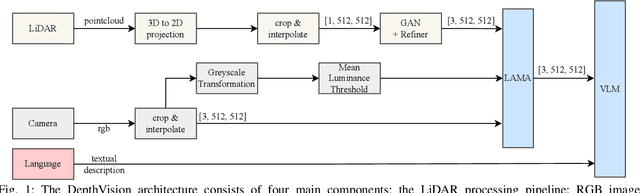
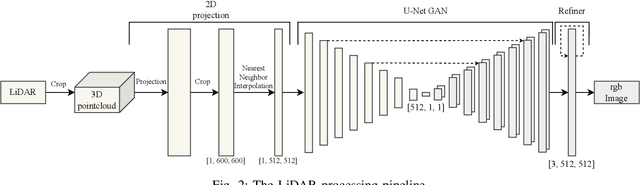
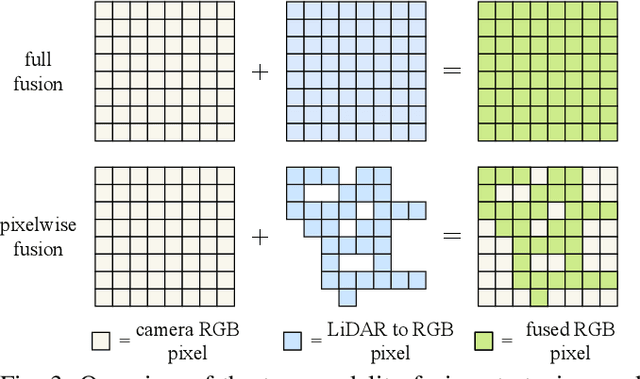
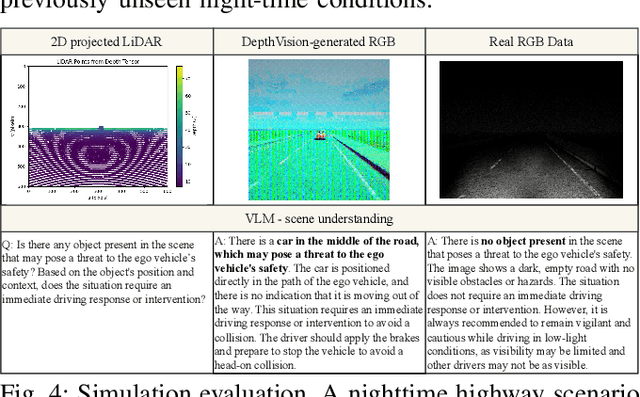
Ensuring reliable robot operation when visual input is degraded or insufficient remains a central challenge in robotics. This letter introduces DepthVision, a framework for multimodal scene understanding designed to address this problem. Unlike existing Vision-Language Models (VLMs), which use only camera-based visual input alongside language, DepthVision synthesizes RGB images from sparse LiDAR point clouds using a conditional generative adversarial network (GAN) with an integrated refiner network. These synthetic views are then combined with real RGB data using a Luminance-Aware Modality Adaptation (LAMA), which blends the two types of data dynamically based on ambient lighting conditions. This approach compensates for sensor degradation, such as darkness or motion blur, without requiring any fine-tuning of downstream vision-language models. We evaluate DepthVision on real and simulated datasets across various models and tasks, with particular attention to safety-critical tasks. The results demonstrate that our approach improves performance in low-light conditions, achieving substantial gains over RGB-only baselines while preserving compatibility with frozen VLMs. This work highlights the potential of LiDAR-guided RGB synthesis for achieving robust robot operation in real-world environments.
Autonomous Vehicle Lateral Control Using Deep Reinforcement Learning with MPC-PID Demonstration
Jun 04, 2025The controller is one of the most important modules in the autonomous driving pipeline, ensuring the vehicle reaches its desired position. In this work, a reinforcement learning based lateral control approach, despite the imperfections in the vehicle models due to measurement errors and simplifications, is presented. Our approach ensures comfortable, efficient, and robust control performance considering the interface between controlling and other modules. The controller consists of the conventional Model Predictive Control (MPC)-PID part as the basis and the demonstrator, and the Deep Reinforcement Learning (DRL) part which leverages the online information from the MPC-PID part. The controller's performance is evaluated in CARLA using the ground truth of the waypoints as inputs. Experimental results demonstrate the effectiveness of the controller when vehicle information is incomplete, and the training of DRL can be stabilized with the demonstration part. These findings highlight the potential to reduce development and integration efforts for autonomous driving pipelines in the future.
Generating Automotive Code: Large Language Models for Software Development and Verification in Safety-Critical Systems
Jun 04, 2025Developing safety-critical automotive software presents significant challenges due to increasing system complexity and strict regulatory demands. This paper proposes a novel framework integrating Generative Artificial Intelligence (GenAI) into the Software Development Lifecycle (SDLC). The framework uses Large Language Models (LLMs) to automate code generation in languages such as C++, incorporating safety-focused practices such as static verification, test-driven development and iterative refinement. A feedback-driven pipeline ensures the integration of test, simulation and verification for compliance with safety standards. The framework is validated through the development of an Adaptive Cruise Control (ACC) system. Comparative benchmarking of LLMs ensures optimal model selection for accuracy and reliability. Results demonstrate that the framework enables automatic code generation while ensuring compliance with safety-critical requirements, systematically integrating GenAI into automotive software engineering. This work advances the use of AI in safety-critical domains, bridging the gap between state-of-the-art generative models and real-world safety requirements.
OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
Mar 30, 2025



We present OpenDriveVLA, a Vision-Language Action (VLA) model designed for end-to-end autonomous driving. OpenDriveVLA builds upon open-source pre-trained large Vision-Language Models (VLMs) to generate reliable driving actions, conditioned on 3D environmental perception, ego vehicle states, and driver commands. To bridge the modality gap between driving visual representations and language embeddings, we propose a hierarchical vision-language alignment process, projecting both 2D and 3D structured visual tokens into a unified semantic space. Besides, OpenDriveVLA models the dynamic relationships between the ego vehicle, surrounding agents, and static road elements through an autoregressive agent-env-ego interaction process, ensuring both spatially and behaviorally informed trajectory planning. Extensive experiments on the nuScenes dataset demonstrate that OpenDriveVLA achieves state-of-the-art results across open-loop trajectory planning and driving-related question-answering tasks. Qualitative analyses further illustrate OpenDriveVLA's superior capability to follow high-level driving commands and robustly generate trajectories under challenging scenarios, highlighting its potential for next-generation end-to-end autonomous driving. We will release our code to facilitate further research in this domain.
Towards Vision Zero: The Accid3nD Dataset
Mar 15, 2025



Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as unavoidable and sporadic outcomes of traffic networks. No public dataset contains 3D annotations of real-world accidents recorded from roadside sensors. We present the Accid3nD dataset, a collection of real-world highway accidents in different weather and lighting conditions. It contains vehicle crashes at high-speed driving with 2,634,233 labeled 2D bounding boxes, instance masks, and 3D bounding boxes with track IDs. In total, the dataset contains 111,945 labeled frames recorded from four roadside cameras and LiDARs at 25 Hz. The dataset contains six object classes and is provided in the OpenLABEL format. We propose an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our website: https://accident-dataset.github.io.
TUMTraffic-VideoQA: A Benchmark for Unified Spatio-Temporal Video Understanding in Traffic Scenes
Feb 04, 2025



We present TUMTraffic-VideoQA, a novel dataset and benchmark designed for spatio-temporal video understanding in complex roadside traffic scenarios. The dataset comprises 1,000 videos, featuring 85,000 multiple-choice QA pairs, 2,300 object captioning, and 5,700 object grounding annotations, encompassing diverse real-world conditions such as adverse weather and traffic anomalies. By incorporating tuple-based spatio-temporal object expressions, TUMTraffic-VideoQA unifies three essential tasks-multiple-choice video question answering, referred object captioning, and spatio-temporal object grounding-within a cohesive evaluation framework. We further introduce the TUMTraffic-Qwen baseline model, enhanced with visual token sampling strategies, providing valuable insights into the challenges of fine-grained spatio-temporal reasoning. Extensive experiments demonstrate the dataset's complexity, highlight the limitations of existing models, and position TUMTraffic-VideoQA as a robust foundation for advancing research in intelligent transportation systems. The dataset and benchmark are publicly available to facilitate further exploration.
WARM-3D: A Weakly-Supervised Sim2Real Domain Adaptation Framework for Roadside Monocular 3D Object Detection
Jul 30, 2024



Existing roadside perception systems are limited by the absence of publicly available, large-scale, high-quality 3D datasets. Exploring the use of cost-effective, extensive synthetic datasets offers a viable solution to tackle this challenge and enhance the performance of roadside monocular 3D detection. In this study, we introduce the TUMTraf Synthetic Dataset, offering a diverse and substantial collection of high-quality 3D data to augment scarce real-world datasets. Besides, we present WARM-3D, a concise yet effective framework to aid the Sim2Real domain transfer for roadside monocular 3D detection. Our method leverages cheap synthetic datasets and 2D labels from an off-the-shelf 2D detector for weak supervision. We show that WARM-3D significantly enhances performance, achieving a +12.40% increase in mAP 3D over the baseline with only pseudo-2D supervision. With 2D GT as weak labels, WARM-3D even reaches performance close to the Oracle baseline. Moreover, WARM-3D improves the ability of 3D detectors to unseen sample recognition across various real-world environments, highlighting its potential for practical applications.
PointCompress3D -- A Point Cloud Compression Framework for Roadside LiDARs in Intelligent Transportation Systems
May 02, 2024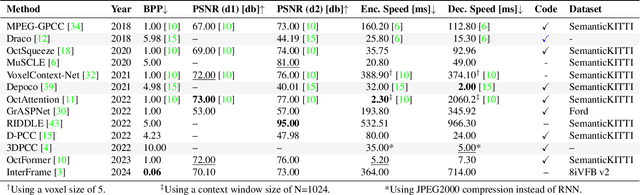

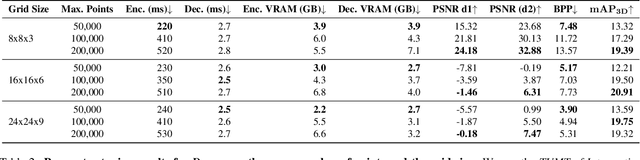
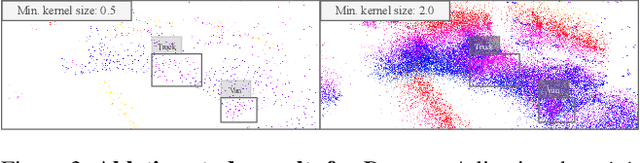
In the context of Intelligent Transportation Systems (ITS), efficient data compression is crucial for managing large-scale point cloud data acquired by roadside LiDAR sensors. The demand for efficient storage, streaming, and real-time object detection capabilities for point cloud data is substantial. This work introduces PointCompress3D, a novel point cloud compression framework tailored specifically for roadside LiDARs. Our framework addresses the challenges of compressing high-resolution point clouds while maintaining accuracy and compatibility with roadside LiDAR sensors. We adapt, extend, integrate, and evaluate three cutting-edge compression methods using our real-world-based TUMTraf dataset family. We achieve a frame rate of 10 FPS while keeping compression sizes below 105 Kb, a reduction of 50 times, and maintaining object detection performance on par with the original data. In extensive experiments and ablation studies, we finally achieved a PSNR d2 of 94.46 and a BPP of 6.54 on our dataset. Future work includes the deployment on the live system. The code is available on our project website: https://pointcompress3d.github.io.
TUMTraf V2X Cooperative Perception Dataset
Mar 02, 2024
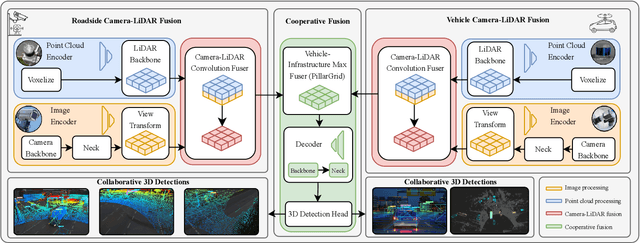

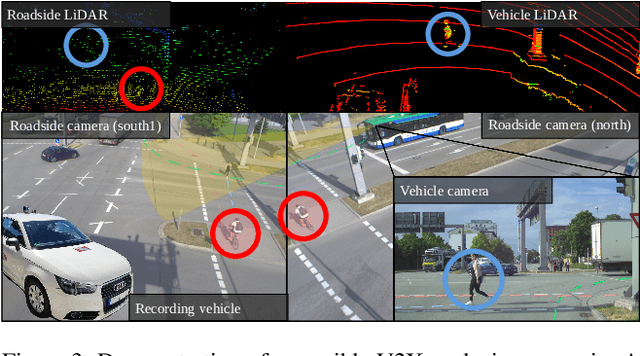
Cooperative perception offers several benefits for enhancing the capabilities of autonomous vehicles and improving road safety. Using roadside sensors in addition to onboard sensors increases reliability and extends the sensor range. External sensors offer higher situational awareness for automated vehicles and prevent occlusions. We propose CoopDet3D, a cooperative multi-modal fusion model, and TUMTraf-V2X, a perception dataset, for the cooperative 3D object detection and tracking task. Our dataset contains 2,000 labeled point clouds and 5,000 labeled images from five roadside and four onboard sensors. It includes 30k 3D boxes with track IDs and precise GPS and IMU data. We labeled eight categories and covered occlusion scenarios with challenging driving maneuvers, like traffic violations, near-miss events, overtaking, and U-turns. Through multiple experiments, we show that our CoopDet3D camera-LiDAR fusion model achieves an increase of +14.36 3D mAP compared to a vehicle camera-LiDAR fusion model. Finally, we make our dataset, model, labeling tool, and dev-kit publicly available on our website: https://tum-traffic-dataset.github.io/tumtraf-v2x.
GPT-4V as Traffic Assistant: An In-depth Look at Vision Language Model on Complex Traffic Events
Feb 07, 2024The recognition and understanding of traffic incidents, particularly traffic accidents, is a topic of paramount importance in the realm of intelligent transportation systems and intelligent vehicles. This area has continually captured the extensive focus of both the academic and industrial sectors. Identifying and comprehending complex traffic events is highly challenging, primarily due to the intricate nature of traffic environments, diverse observational perspectives, and the multifaceted causes of accidents. These factors have persistently impeded the development of effective solutions. The advent of large vision-language models (VLMs) such as GPT-4V, has introduced innovative approaches to addressing this issue. In this paper, we explore the ability of GPT-4V with a set of representative traffic incident videos and delve into the model's capacity of understanding these complex traffic situations. We observe that GPT-4V demonstrates remarkable cognitive, reasoning, and decision-making ability in certain classic traffic events. Concurrently, we also identify certain limitations of GPT-4V, which constrain its understanding in more intricate scenarios. These limitations merit further exploration and resolution.