 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Road Ahead in Autonomous Driving: The KITScenes Multimodal Dataset
Jun 01, 2026Existing autonomous driving datasets have enabled major progress, but fall short in sensor fidelity, map completeness, or geographic diversity. We present KITScenes Multimodal, a European dataset built around high-fidelity sensors and maps. Our fully synchronized sensor suite combines high-resolution global-shutter cameras, long-range lidar beyond 400m, 4D imaging radar, and redundant GNSS/INS localization. Our HD maps are, to our knowledge, the most complete of any sensor dataset, validated through autonomous driving trials on open-source software. For the first time in a public dataset, all driving-relevant traffic elements, such as traffic lights, are mapped in 3D to a reprojection-accurate level with full topological connectivity. Recorded in cities with irregular street layouts and mixed traffic modes, our dataset complements existing datasets by broadening the available geographic diversity. We also introduce four benchmarks, each advancing spatial learning for embodied AI: online HD map construction, long-range depth estimation, novel view synthesis, and end-to-end driving. Project page: https://kitscenes.com/
TerraSeg: Self-Supervised Ground Segmentation for Any LiDAR
Mar 28, 2026LiDAR perception is fundamental to robotics, enabling machines to understand their environment in 3D. A crucial task for LiDAR-based scene understanding and navigation is ground segmentation. However, existing methods are either handcrafted for specific sensor configurations or rely on costly per-point manual labels, severely limiting their generalization and scalability. To overcome this, we introduce TerraSeg, the first self-supervised, domain-agnostic model for LiDAR ground segmentation. We train TerraSeg on OmniLiDAR, a unified large-scale dataset that aggregates and standardizes data from 12 major public benchmarks. Spanning almost 22 million raw scans across 15 distinct sensor models, OmniLiDAR provides unprecedented diversity for learning a highly generalizable ground model. To supervise training without human annotations, we propose PseudoLabeler, a novel module that generates high-quality ground and non-ground labels through self-supervised per-scan runtime optimization. Extensive evaluations demonstrate that, despite using no manual labels, TerraSeg achieves state-of-the-art results on nuScenes, SemanticKITTI, and Waymo Perception while delivering real-time performance. Our code and model weights are publicly available.
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Mar 24, 2026In real-world domains such as self-driving, generalization to rare scenarios remains a fundamental challenge. To address this, we introduce a new dataset designed for end-to-end driving that focuses on long-tail driving events. We provide multi-view video data, trajectories, high-level instructions, and detailed reasoning traces, facilitating in-context learning and few-shot generalization. The resulting benchmark for multimodal models, such as VLMs and VLAs, goes beyond safety and comfort metrics by evaluating instruction following and semantic coherence between model outputs. The multilingual reasoning traces in English, Spanish, and Chinese are from domain experts with diverse cultural backgrounds. Thus, our dataset is a unique resource for studying how different forms of reasoning affect driving competence. Our dataset is available at: https://hf.co/datasets/kit-mrt/kitscenes-longtail
Probing the Reliability of Driving VLMs: From Inconsistent Responses to Grounded Temporal Reasoning
Mar 10, 2026A reliable driving assistant should provide consistent responses based on temporally grounded reasoning derived from observed information. In this work, we investigate whether Vision-Language Models (VLMs), when applied as driving assistants, can response consistantly and understand how present observations shape future outcomes, or whether their outputs merely reflect patterns memorized during training without temporally grounded reasoning. While recent efforts have integrated VLMs into autonomous driving, prior studies typically emphasize scene understanding and instruction generation, implicitly assuming that strong visual interpretation naturally enables consistant future reasoning and thus ensures reliable decision-making, a claim we critically examine. We focus on two major challenges limiting VLM reliability in this setting: response inconsistency, where minor input perturbations yield different answers or, in some cases, responses degenerate toward near-random guessing, and limited temporal reasoning, in which models fail to reason and align sequential events from current observations, often resulting in incorrect or even contradictory responses. Moreover, we find that models with strong visual understanding do not necessarily perform best on tasks requiring temporal reasoning, indicating a tendency to over-rely on pretrained patterns rather than modeling temporal dynamics. To address these issues, we adopt existing evaluation methods and introduce FutureVQA, a human-annotated benchmark dataset specifically designed to assess future scene reasoning. In addition, we propose a simple yet effective self-supervised tuning approach with chain-of-thought reasoning that improves both consistency and temporal reasoning without requiring temporal labels.
4DRC-OCC: Robust Semantic Occupancy Prediction Through Fusion of 4D Radar and Camera
Mar 08, 2026Autonomous driving requires robust perception across diverse environmental conditions, yet 3D semantic occupancy prediction remains challenging under adverse weather and lighting. In this work, we present the first study combining 4D radar and camera data for 3D semantic occupancy prediction. Our fusion leverages the complementary strengths of both modalities: 4D radar provides reliable range, velocity, and angle measurements in challenging conditions, while cameras contribute rich semantic and texture information. We further show that integrating depth cues from camera pixels enables lifting 2D images to 3D, improving scene reconstruction accuracy. Additionally, we introduce a fully automatically labeled dataset for training semantic occupancy models, substantially reducing reliance on costly manual annotation. Experiments demonstrate the robustness of 4D radar across diverse scenarios, highlighting its potential to advance autonomous vehicle perception.
GaussianCaR: Gaussian Splatting for Efficient Camera-Radar Fusion
Feb 09, 2026Robust and accurate perception of dynamic objects and map elements is crucial for autonomous vehicles performing safe navigation in complex traffic scenarios. While vision-only methods have become the de facto standard due to their technical advances, they can benefit from effective and cost-efficient fusion with radar measurements. In this work, we advance fusion methods by repurposing Gaussian Splatting as an efficient universal view transformer that bridges the view disparity gap, mapping both image pixels and radar points into a common Bird's-Eye View (BEV) representation. Our main contribution is GaussianCaR, an end-to-end network for BEV segmentation that, unlike prior BEV fusion methods, leverages Gaussian Splatting to map raw sensor information into latent features for efficient camera-radar fusion. Our architecture combines multi-scale fusion with a transformer decoder to efficiently extract BEV features. Experimental results demonstrate that our approach achieves performance on par with, or even surpassing, the state of the art on BEV segmentation tasks (57.3%, 82.9%, and 50.1% IoU for vehicles, roads, and lane dividers) on the nuScenes dataset, while maintaining a 3.2x faster inference runtime. Code and project page are available online.
AsyncBEV: Cross-modal Flow Alignment in Asynchronous 3D Object Detection
Jan 19, 2026In autonomous driving, multi-modal perception tasks like 3D object detection typically rely on well-synchronized sensors, both at training and inference. However, despite the use of hardware- or software-based synchronization algorithms, perfect synchrony is rarely guaranteed: Sensors may operate at different frequencies, and real-world factors such as network latency, hardware failures, or processing bottlenecks often introduce time offsets between sensors. Such asynchrony degrades perception performance, especially for dynamic objects. To address this challenge, we propose AsyncBEV, a trainable lightweight and generic module to improve the robustness of 3D Birds' Eye View (BEV) object detection models against sensor asynchrony. Inspired by scene flow estimation, AsyncBEV first estimates the 2D flow from the BEV features of two different sensor modalities, taking into account the known time offset between these sensor measurements. The predicted feature flow is then used to warp and spatially align the feature maps, which we show can easily be integrated into different current BEV detector architectures (e.g., BEV grid-based and token-based). Extensive experiments demonstrate AsyncBEV improves robustness against both small and large asynchrony between LiDAR or camera sensors in both the token-based CMT and grid-based UniBEV, especially for dynamic objects. We significantly outperform the ego motion compensated CMT and UniBEV baselines, notably by $16.6$ % and $11.9$ % NDS on dynamic objects in the worst-case scenario of a $0.5 s$ time offset. Code will be released upon acceptance.
4D-RaDiff: Latent Diffusion for 4D Radar Point Cloud Generation
Dec 16, 2025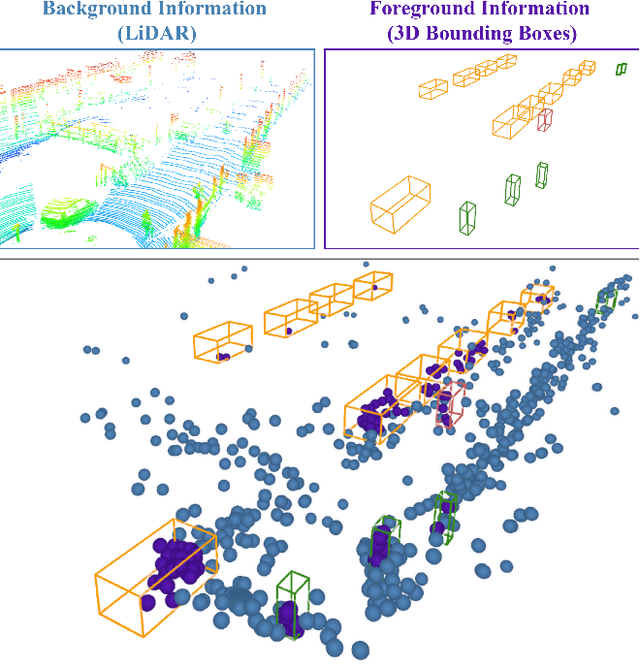

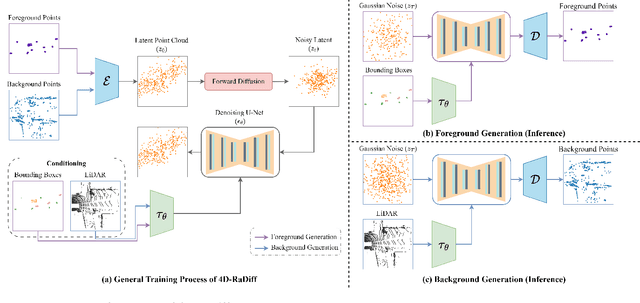
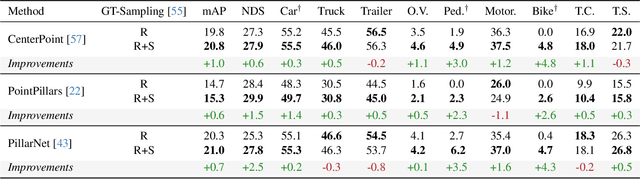
Automotive radar has shown promising developments in environment perception due to its cost-effectiveness and robustness in adverse weather conditions. However, the limited availability of annotated radar data poses a significant challenge for advancing radar-based perception systems. To address this limitation, we propose a novel framework to generate 4D radar point clouds for training and evaluating object detectors. Unlike image-based diffusion, our method is designed to consider the sparsity and unique characteristics of radar point clouds by applying diffusion to a latent point cloud representation. Within this latent space, generation is controlled via conditioning at either the object or scene level. The proposed 4D-RaDiff converts unlabeled bounding boxes into high-quality radar annotations and transforms existing LiDAR point cloud data into realistic radar scenes. Experiments demonstrate that incorporating synthetic radar data of 4D-RaDiff as data augmentation method during training consistently improves object detection performance compared to training on real data only. In addition, pre-training on our synthetic data reduces the amount of required annotated radar data by up to 90% while achieving comparable object detection performance.
ShelfOcc: Native 3D Supervision beyond LiDAR for Vision-Based Occupancy Estimation
Nov 19, 2025Recent progress in self- and weakly supervised occupancy estimation has largely relied on 2D projection or rendering-based supervision, which suffers from geometric inconsistencies and severe depth bleeding. We thus introduce ShelfOcc, a vision-only method that overcomes these limitations without relying on LiDAR. ShelfOcc brings supervision into native 3D space by generating metrically consistent semantic voxel labels from video, enabling true 3D supervision without any additional sensors or manual 3D annotations. While recent vision-based 3D geometry foundation models provide a promising source of prior knowledge, they do not work out of the box as a prediction due to sparse or noisy and inconsistent geometry, especially in dynamic driving scenes. Our method introduces a dedicated framework that mitigates these issues by filtering and accumulating static geometry consistently across frames, handling dynamic content and propagating semantic information into a stable voxel representation. This data-centric shift in supervision for weakly/shelf-supervised occupancy estimation allows the use of essentially any SOTA occupancy model architecture without relying on LiDAR data. We argue that such high-quality supervision is essential for robust occupancy learning and constitutes an important complementary avenue to architectural innovation. On the Occ3D-nuScenes benchmark, ShelfOcc substantially outperforms all previous weakly/shelf-supervised methods (up to a 34% relative improvement), establishing a new data-driven direction for LiDAR-free 3D scene understanding.
BikeScenes: Online LiDAR Semantic Segmentation for Bicycles
Oct 29, 2025The vulnerability of cyclists, exacerbated by the rising popularity of faster e-bikes, motivates adapting automotive perception technologies for bicycle safety. We use our multi-sensor 'SenseBike' research platform to develop and evaluate a 3D LiDAR segmentation approach tailored to bicycles. To bridge the automotive-to-bicycle domain gap, we introduce the novel BikeScenes-lidarseg Dataset, comprising 3021 consecutive LiDAR scans around the university campus of the TU Delft, semantically annotated for 29 dynamic and static classes. By evaluating model performance, we demonstrate that fine-tuning on our BikeScenes dataset achieves a mean Intersection-over-Union (mIoU) of 63.6%, significantly outperforming the 13.8% obtained with SemanticKITTI pre-training alone. This result underscores the necessity and effectiveness of domain-specific training. We highlight key challenges specific to bicycle-mounted, hardware-constrained perception systems and contribute the BikeScenes dataset as a resource for advancing research in cyclist-centric LiDAR segmentation.