 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncBEV: Cross-modal Flow Alignment in Asynchronous 3D Object Detection
Jan 19, 2026In autonomous driving, multi-modal perception tasks like 3D object detection typically rely on well-synchronized sensors, both at training and inference. However, despite the use of hardware- or software-based synchronization algorithms, perfect synchrony is rarely guaranteed: Sensors may operate at different frequencies, and real-world factors such as network latency, hardware failures, or processing bottlenecks often introduce time offsets between sensors. Such asynchrony degrades perception performance, especially for dynamic objects. To address this challenge, we propose AsyncBEV, a trainable lightweight and generic module to improve the robustness of 3D Birds' Eye View (BEV) object detection models against sensor asynchrony. Inspired by scene flow estimation, AsyncBEV first estimates the 2D flow from the BEV features of two different sensor modalities, taking into account the known time offset between these sensor measurements. The predicted feature flow is then used to warp and spatially align the feature maps, which we show can easily be integrated into different current BEV detector architectures (e.g., BEV grid-based and token-based). Extensive experiments demonstrate AsyncBEV improves robustness against both small and large asynchrony between LiDAR or camera sensors in both the token-based CMT and grid-based UniBEV, especially for dynamic objects. We significantly outperform the ego motion compensated CMT and UniBEV baselines, notably by $16.6$ % and $11.9$ % NDS on dynamic objects in the worst-case scenario of a $0.5 s$ time offset. Code will be released upon acceptance.
A Vehicle System for Navigating Among Vulnerable Road Users Including Remote Operation
May 08, 2025



We present a vehicle system capable of navigating safely and efficiently around Vulnerable Road Users (VRUs), such as pedestrians and cyclists. The system comprises key modules for environment perception, localization and mapping, motion planning, and control, integrated into a prototype vehicle. A key innovation is a motion planner based on Topology-driven Model Predictive Control (T-MPC). The guidance layer generates multiple trajectories in parallel, each representing a distinct strategy for obstacle avoidance or non-passing. The underlying trajectory optimization constrains the joint probability of collision with VRUs under generic uncertainties. To address extraordinary situations ("edge cases") that go beyond the autonomous capabilities - such as construction zones or encounters with emergency responders - the system includes an option for remote human operation, supported by visual and haptic guidance. In simulation, our motion planner outperforms three baseline approaches in terms of safety and efficiency. We also demonstrate the full system in prototype vehicle tests on a closed track, both in autonomous and remotely operated modes.
VoteFlow: Enforcing Local Rigidity in Self-Supervised Scene Flow
Mar 28, 2025Scene flow estimation aims to recover per-point motion from two adjacent LiDAR scans. However, in real-world applications such as autonomous driving, points rarely move independently of others, especially for nearby points belonging to the same object, which often share the same motion. Incorporating this locally rigid motion constraint has been a key challenge in self-supervised scene flow estimation, which is often addressed by post-processing or appending extra regularization. While these approaches are able to improve the rigidity of predicted flows, they lack an architectural inductive bias for local rigidity within the model structure, leading to suboptimal learning efficiency and inferior performance. In contrast, we enforce local rigidity with a lightweight add-on module in neural network design, enabling end-to-end learning. We design a discretized voting space that accommodates all possible translations and then identify the one shared by nearby points by differentiable voting. Additionally, to ensure computational efficiency, we operate on pillars rather than points and learn representative features for voting per pillar. We plug the Voting Module into popular model designs and evaluate its benefit on Argoverse 2 and Waymo datasets. We outperform baseline works with only marginal compute overhead. Code is available at https://github.com/tudelft-iv/VoteFlow.
Crafter: Facial Feature Crafting against Inversion-based Identity Theft on Deep Models
Jan 14, 2024



With the increased capabilities at the edge (e.g., mobile device) and more stringent privacy requirement, it becomes a recent trend for deep learning-enabled applications to pre-process sensitive raw data at the edge and transmit the features to the backend cloud for further processing. A typical application is to run machine learning (ML) services on facial images collected from different individuals. To prevent identity theft, conventional methods commonly rely on an adversarial game-based approach to shed the identity information from the feature. However, such methods can not defend against adaptive attacks, in which an attacker takes a countermove against a known defence strategy. We propose Crafter, a feature crafting mechanism deployed at the edge, to protect the identity information from adaptive model inversion attacks while ensuring the ML tasks are properly carried out in the cloud. The key defence strategy is to mislead the attacker to a non-private prior from which the attacker gains little about the private identity. In this case, the crafted features act like poison training samples for attackers with adaptive model updates. Experimental results indicate that Crafter successfully defends both basic and possible adaptive attacks, which can not be achieved by state-of-the-art adversarial game-based methods.
UniBEV: Multi-modal 3D Object Detection with Uniform BEV Encoders for Robustness against Missing Sensor Modalities
Sep 25, 2023



Multi-sensor object detection is an active research topic in automated driving, but the robustness of such detection models against missing sensor input (modality missing), e.g., due to a sudden sensor failure, is a critical problem which remains under-studied. In this work, we propose UniBEV, an end-to-end multi-modal 3D object detection framework designed for robustness against missing modalities: UniBEV can operate on LiDAR plus camera input, but also on LiDAR-only or camera-only input without retraining. To facilitate its detector head to handle different input combinations, UniBEV aims to create well-aligned Bird's Eye View (BEV) feature maps from each available modality. Unlike prior BEV-based multi-modal detection methods, all sensor modalities follow a uniform approach to resample features from the native sensor coordinate systems to the BEV features. We furthermore investigate the robustness of various fusion strategies w.r.t. missing modalities: the commonly used feature concatenation, but also channel-wise averaging, and a generalization to weighted averaging termed Channel Normalized Weights. To validate its effectiveness, we compare UniBEV to state-of-the-art BEVFusion and MetaBEV on nuScenes over all sensor input combinations. In this setting, UniBEV achieves $52.5 \%$ mAP on average over all input combinations, significantly improving over the baselines ($43.5 \%$ mAP on average for BEVFusion, $48.7 \%$ mAP on average for MetaBEV). An ablation study shows the robustness benefits of fusing by weighted averaging over regular concatenation, and of sharing queries between the BEV encoders of each modality. Our code will be released upon paper acceptance.
Text Enhancement for Paragraph Processing in End-to-End Code-switching TTS
Oct 20, 2022Current end-to-end code-switching Text-to-Speech (TTS) can already generate high quality two languages speech in the same utterance with single speaker bilingual corpora. When the speakers of the bilingual corpora are different, the naturalness and consistency of the code-switching TTS will be poor. The cross-lingual embedding layers structure we proposed makes similar syllables in different languages relevant, thus improving the naturalness and consistency of generated speech. In the end-to-end code-switching TTS, there exists problem of prosody instability when synthesizing paragraph text. The text enhancement method we proposed makes the input contain prosodic information and sentence-level context information, thus improving the prosody stability of paragraph text. Experimental results demonstrate the effectiveness of the proposed methods in the naturalness, consistency, and prosody stability. In addition to Mandarin and English, we also apply these methods to Shanghaiese and Cantonese corpora, proving that the methods we proposed can be extended to other languages to build end-to-end code-switching TTS system.
An Initial Investigation for Detecting Vocoder Fingerprints of Fake Audio
Aug 20, 2022

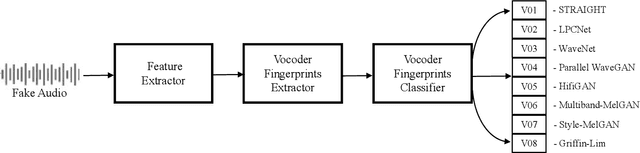
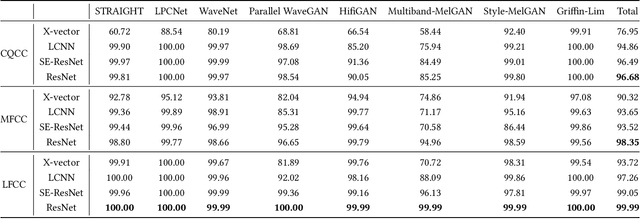
Many effective attempts have been made for fake audio detection. However, they can only provide detection results but no countermeasures to curb this harm. For many related practical applications, what model or algorithm generated the fake audio also is needed. Therefore, We propose a new problem for detecting vocoder fingerprints of fake audio. Experiments are conducted on the datasets synthesized by eight state-of-the-art vocoders. We have preliminarily explored the features and model architectures. The t-SNE visualization shows that different vocoders generate distinct vocoder fingerprints.
ADD 2022: the First Audio Deep Synthesis Detection Challenge
Feb 26, 2022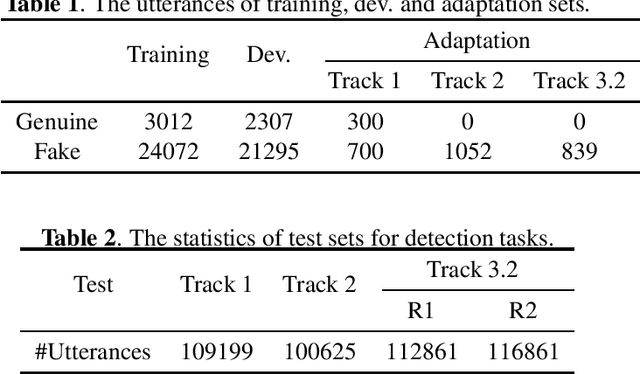
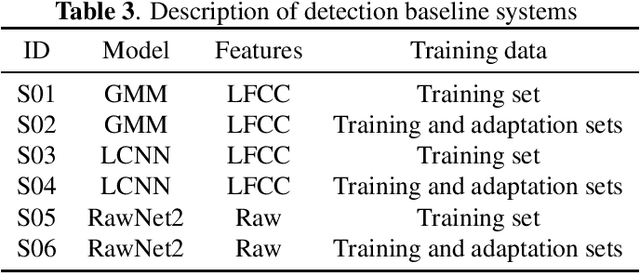
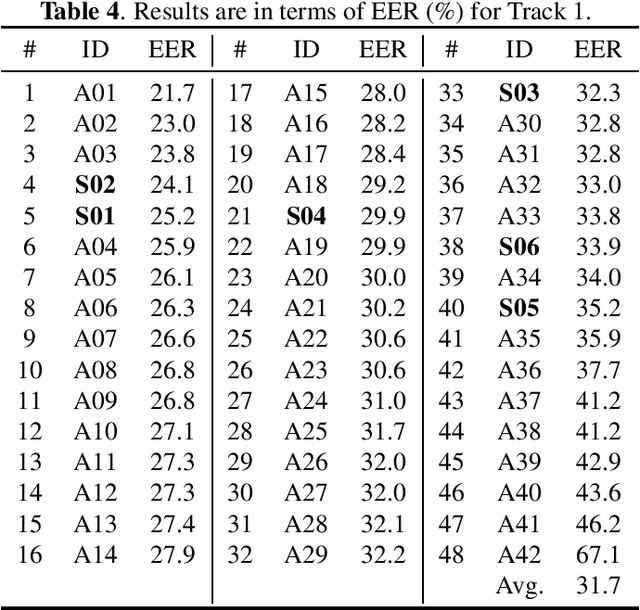
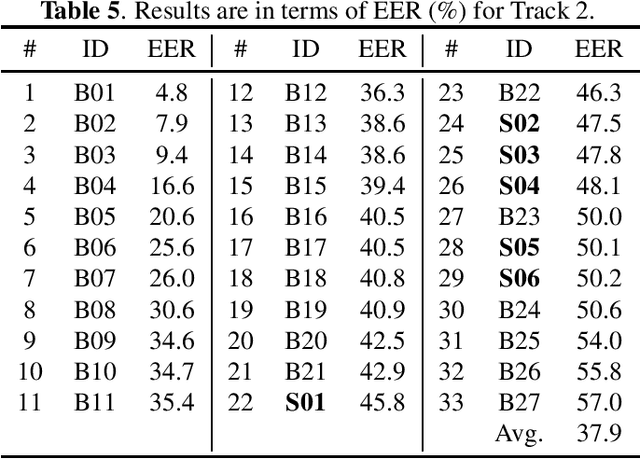
Audio deepfake detection is an emerging topic, which was included in the ASVspoof 2021. However, the recent shared tasks have not covered many real-life and challenging scenarios. The first Audio Deep synthesis Detection challenge (ADD) was motivated to fill in the gap. The ADD 2022 includes three tracks: low-quality fake audio detection (LF), partially fake audio detection (PF) and audio fake game (FG). The LF track focuses on dealing with bona fide and fully fake utterances with various real-world noises etc. The PF track aims to distinguish the partially fake audio from the real. The FG track is a rivalry game, which includes two tasks: an audio generation task and an audio fake detection task. In this paper, we describe the datasets, evaluation metrics, and protocols. We also report major findings that reflect the recent advances in audio deepfake detection tasks.