 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024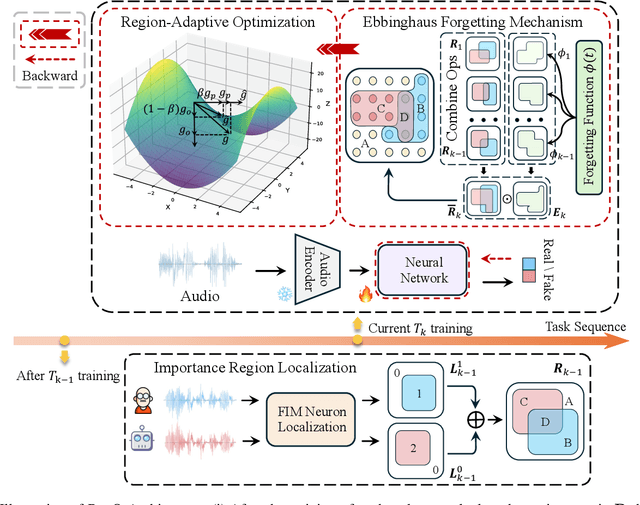
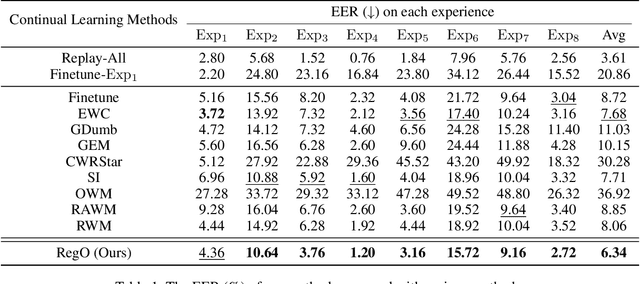
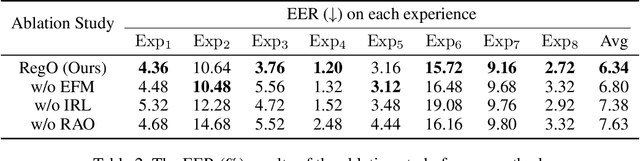
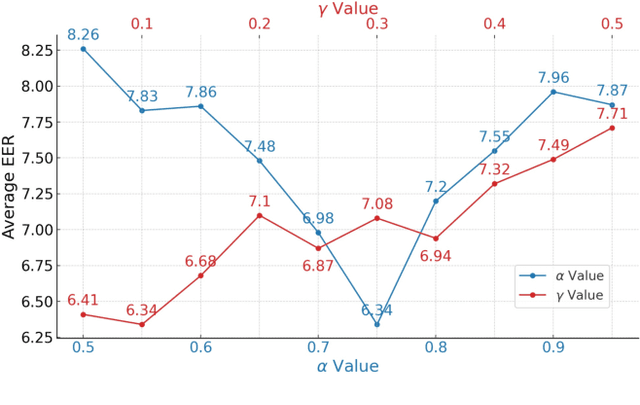
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
Reject Threshold Adaptation for Open-Set Model Attribution of Deepfake Audio
Dec 02, 2024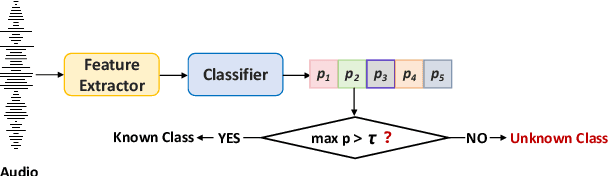


Open environment oriented open set model attribution of deepfake audio is an emerging research topic, aiming to identify the generation models of deepfake audio. Most previous work requires manually setting a rejection threshold for unknown classes to compare with predicted probabilities. However, models often overfit training instances and generate overly confident predictions. Moreover, thresholds that effectively distinguish unknown categories in the current dataset may not be suitable for identifying known and unknown categories in another data distribution. To address the issues, we propose a novel framework for open set model attribution of deepfake audio with rejection threshold adaptation (ReTA). Specifically, the reconstruction error learning module trains by combining the representation of system fingerprints with labels corresponding to either the target class or a randomly chosen other class label. This process generates matching and non-matching reconstructed samples, establishing the reconstruction error distributions for each class and laying the foundation for the reject threshold calculation module. The reject threshold calculation module utilizes gaussian probability estimation to fit the distributions of matching and non-matching reconstruction errors. It then computes adaptive reject thresholds for all classes through probability minimization criteria. The experimental results demonstrate the effectiveness of ReTA in improving the open set model attributes of deepfake audio.
Utilizing Speaker Profiles for Impersonation Audio Detection
Aug 30, 2024



Fake audio detection is an emerging active topic. A growing number of literatures have aimed to detect fake utterance, which are mostly generated by Text-to-speech (TTS) or voice conversion (VC). However, countermeasures against impersonation remain an underexplored area. Impersonation is a fake type that involves an imitator replicating specific traits and speech style of a target speaker. Unlike TTS and VC, which often leave digital traces or signal artifacts, impersonation involves live human beings producing entirely natural speech, rendering the detection of impersonation audio a challenging task. Thus, we propose a novel method that integrates speaker profiles into the process of impersonation audio detection. Speaker profiles are inherent characteristics that are challenging for impersonators to mimic accurately, such as speaker's age, job. We aim to leverage these features to extract discriminative information for detecting impersonation audio. Moreover, there is no large impersonated speech corpora available for quantitative study of impersonation impacts. To address this gap, we further design the first large-scale, diverse-speaker Chinese impersonation dataset, named ImPersonation Audio Detection (IPAD), to advance the community's research on impersonation audio detection. We evaluate several existing fake audio detection methods on our proposed dataset IPAD, demonstrating its necessity and the challenges. Additionally, our findings reveal that incorporating speaker profiles can significantly enhance the model's performance in detecting impersonation audio.
ADD 2023: Towards Audio Deepfake Detection and Analysis in the Wild
Aug 09, 2024



The growing prominence of the field of audio deepfake detection is driven by its wide range of applications, notably in protecting the public from potential fraud and other malicious activities, prompting the need for greater attention and research in this area. The ADD 2023 challenge goes beyond binary real/fake classification by emulating real-world scenarios, such as the identification of manipulated intervals in partially fake audio and determining the source responsible for generating any fake audio, both with real-life implications, notably in audio forensics, law enforcement, and construction of reliable and trustworthy evidence. To further foster research in this area, in this article, we describe the dataset that was used in the fake game, manipulation region location and deepfake algorithm recognition tracks of the challenge. We also focus on the analysis of the technical methodologies by the top-performing participants in each task and note the commonalities and differences in their approaches. Finally, we discuss the current technical limitations as identified through the technical analysis, and provide a roadmap for future research directions. The dataset is available for download.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


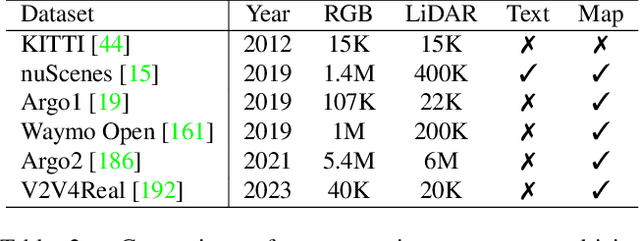
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
Distinguishing Neural Speech Synthesis Models Through Fingerprints in Speech Waveforms
Sep 13, 2023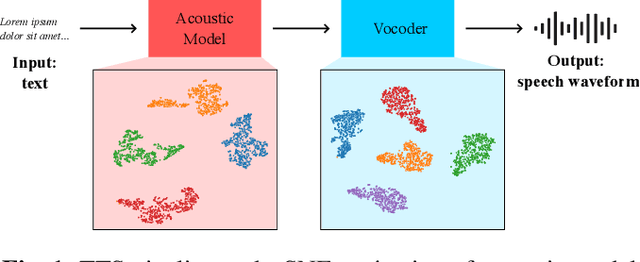
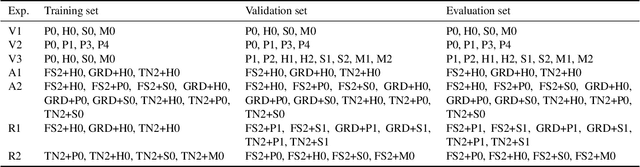


Recent strides in neural speech synthesis technologies, while enjoying widespread applications, have nonetheless introduced a series of challenges, spurring interest in the defence against the threat of misuse and abuse. Notably, source attribution of synthesized speech has value in forensics and intellectual property protection, but prior work in this area has certain limitations in scope. To address the gaps, we present our findings concerning the identification of the sources of synthesized speech in this paper. We investigate the existence of speech synthesis model fingerprints in the generated speech waveforms, with a focus on the acoustic model and the vocoder, and study the influence of each component on the fingerprint in the overall speech waveforms. Our research, conducted using the multi-speaker LibriTTS dataset, demonstrates two key insights: (1) vocoders and acoustic models impart distinct, model-specific fingerprints on the waveforms they generate, and (2) vocoder fingerprints are the more dominant of the two, and may mask the fingerprints from the acoustic model. These findings strongly suggest the existence of model-specific fingerprints for both the acoustic model and the vocoder, highlighting their potential utility in source identification applications.
ADD 2023: the Second Audio Deepfake Detection Challenge
May 23, 2023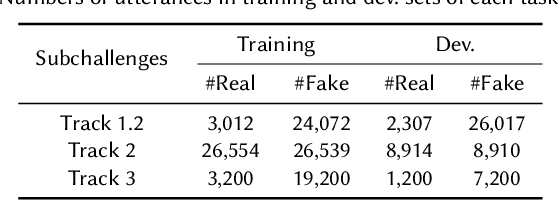
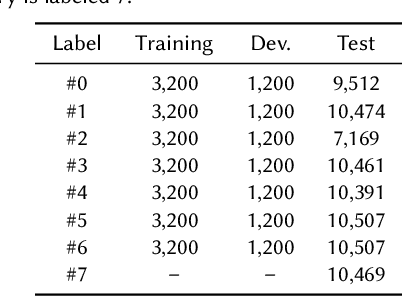
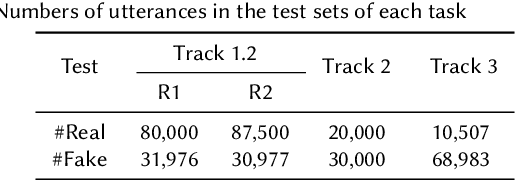

Audio deepfake detection is an emerging topic in the artificial intelligence community. The second Audio Deepfake Detection Challenge (ADD 2023) aims to spur researchers around the world to build new innovative technologies that can further accelerate and foster research on detecting and analyzing deepfake speech utterances. Different from previous challenges (e.g. ADD 2022), ADD 2023 focuses on surpassing the constraints of binary real/fake classification, and actually localizing the manipulated intervals in a partially fake speech as well as pinpointing the source responsible for generating any fake audio. Furthermore, ADD 2023 includes more rounds of evaluation for the fake audio game sub-challenge. The ADD 2023 challenge includes three subchallenges: audio fake game (FG), manipulation region location (RL) and deepfake algorithm recognition (AR). This paper describes the datasets, evaluation metrics, and protocols. Some findings are also reported in audio deepfake detection tasks.
System Fingerprints Detection for DeepFake Audio: An Initial Dataset and Investigation
Aug 21, 2022
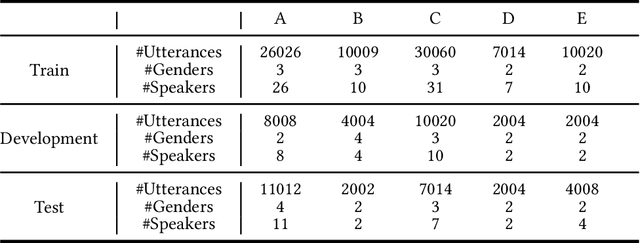
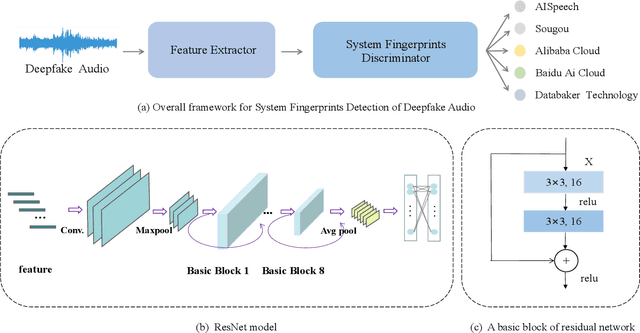
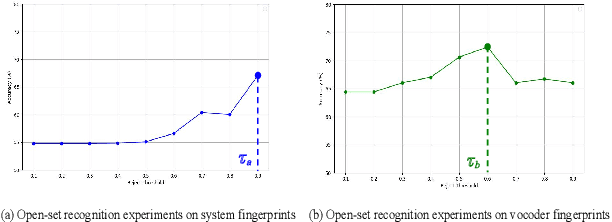
Many effective attempts have been made for deepfake audio detection. However, they can only distinguish between real and fake. For many practical application scenarios, what tool or algorithm generated the deepfake audio also is needed. This raises a question: Can we detect the system fingerprints of deepfake audio? Therefore, this paper conducts a preliminary investigation to detect system fingerprints of deepfake audio. Experiments are conducted on deepfake audio datasets from five latest deep-learning speech synthesis systems. The results show that LFCC features are relatively more suitable for system fingerprints detection. Moreover, the ResNet achieves the best detection results among LCNN and x-vector based models. The t-SNE visualization shows that different speech synthesis systems generate distinct system fingerprints.
An Initial Investigation for Detecting Vocoder Fingerprints of Fake Audio
Aug 20, 2022

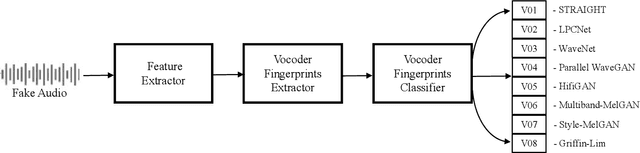
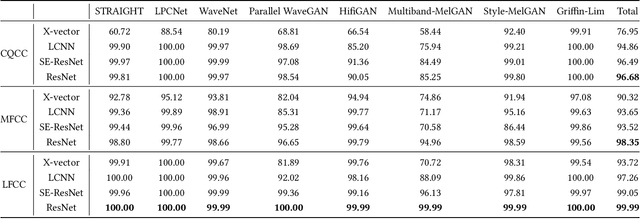
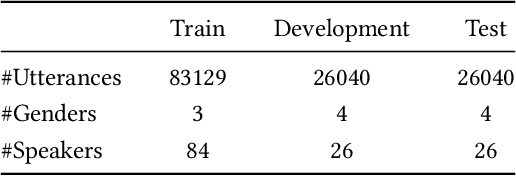
Many effective attempts have been made for fake audio detection. However, they can only provide detection results but no countermeasures to curb this harm. For many related practical applications, what model or algorithm generated the fake audio also is needed. Therefore, We propose a new problem for detecting vocoder fingerprints of fake audio. Experiments are conducted on the datasets synthesized by eight state-of-the-art vocoders. We have preliminarily explored the features and model architectures. The t-SNE visualization shows that different vocoders generate distinct vocoder fingerprints.
ADD 2022: the First Audio Deep Synthesis Detection Challenge
Feb 26, 2022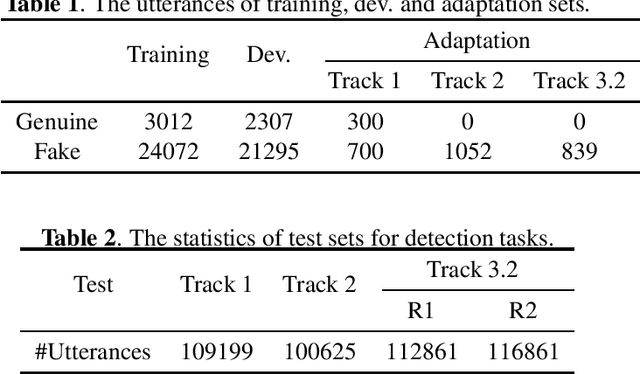
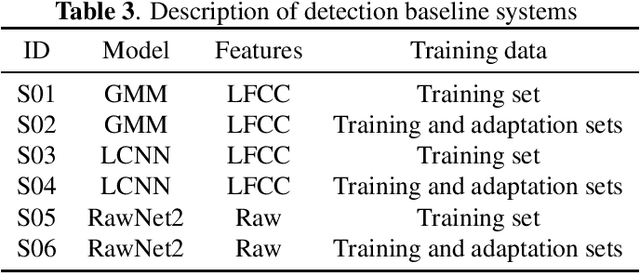
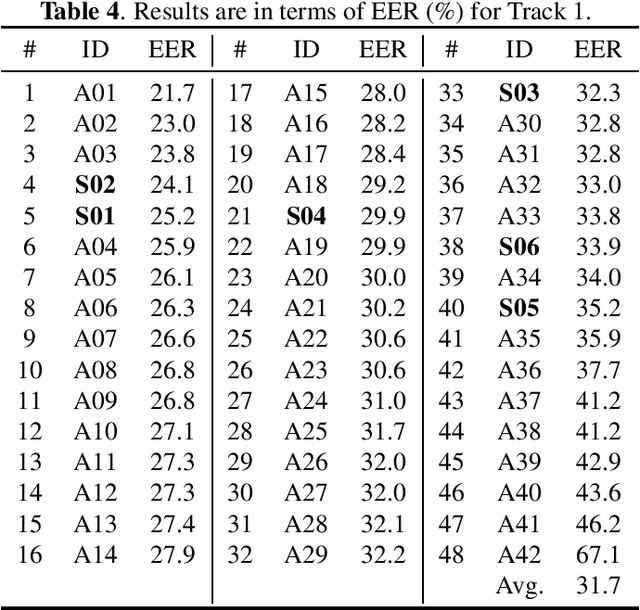
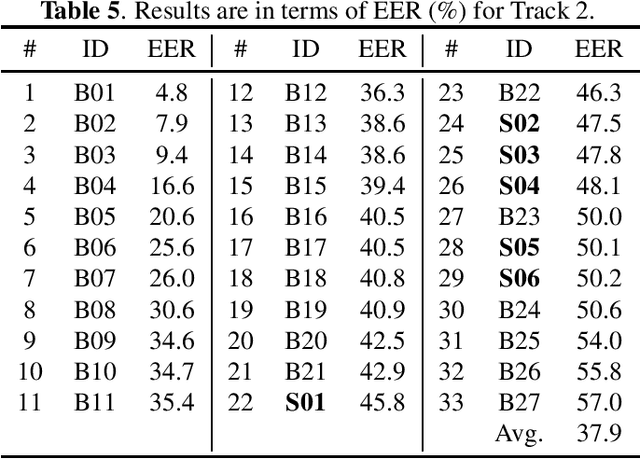
Audio deepfake detection is an emerging topic, which was included in the ASVspoof 2021. However, the recent shared tasks have not covered many real-life and challenging scenarios. The first Audio Deep synthesis Detection challenge (ADD) was motivated to fill in the gap. The ADD 2022 includes three tracks: low-quality fake audio detection (LF), partially fake audio detection (PF) and audio fake game (FG). The LF track focuses on dealing with bona fide and fully fake utterances with various real-world noises etc. The PF track aims to distinguish the partially fake audio from the real. The FG track is a rivalry game, which includes two tasks: an audio generation task and an audio fake detection task. In this paper, we describe the datasets, evaluation metrics, and protocols. We also report major findings that reflect the recent advances in audio deepfake detection tasks.