 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing Neural Speech Synthesis Models Through Fingerprints in Speech Waveforms
Paper and Code
Sep 13, 2023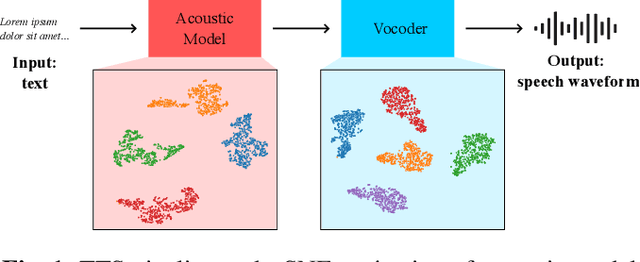


Recent strides in neural speech synthesis technologies, while enjoying widespread applications, have nonetheless introduced a series of challenges, spurring interest in the defence against the threat of misuse and abuse. Notably, source attribution of synthesized speech has value in forensics and intellectual property protection, but prior work in this area has certain limitations in scope. To address the gaps, we present our findings concerning the identification of the sources of synthesized speech in this paper. We investigate the existence of speech synthesis model fingerprints in the generated speech waveforms, with a focus on the acoustic model and the vocoder, and study the influence of each component on the fingerprint in the overall speech waveforms. Our research, conducted using the multi-speaker LibriTTS dataset, demonstrates two key insights: (1) vocoders and acoustic models impart distinct, model-specific fingerprints on the waveforms they generate, and (2) vocoder fingerprints are the more dominant of the two, and may mask the fingerprints from the acoustic model. These findings strongly suggest the existence of model-specific fingerprints for both the acoustic model and the vocoder, highlighting their potential utility in source identification applications.