 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Knowledge Purification in Multi-Teacher Knowledge Distillation for LLMs
Feb 01, 2026Knowledge distillation has emerged as a pivotal technique for transferring knowledge from stronger large language models (LLMs) to smaller, more efficient models. However, traditional distillation approaches face challenges related to knowledge conflicts and high resource demands, particularly when leveraging multiple teacher models. In this paper, we introduce the concept of \textbf{Knowledge Purification}, which consolidates the rationales from multiple teacher LLMs into a single rationale, thereby mitigating conflicts and enhancing efficiency. To investigate the effectiveness of knowledge purification, we further propose five purification methods from various perspectives. Our experiments demonstrate that these methods not only improve the performance of the distilled model but also effectively alleviate knowledge conflicts. Moreover, router-based methods exhibit robust generalization capabilities, underscoring the potential of innovative purification techniques in optimizing multi-teacher distillation and facilitating the practical deployment of powerful yet lightweight models.
Region-Based Optimization in Continual Learning for Audio Deepfake Detection
Dec 16, 2024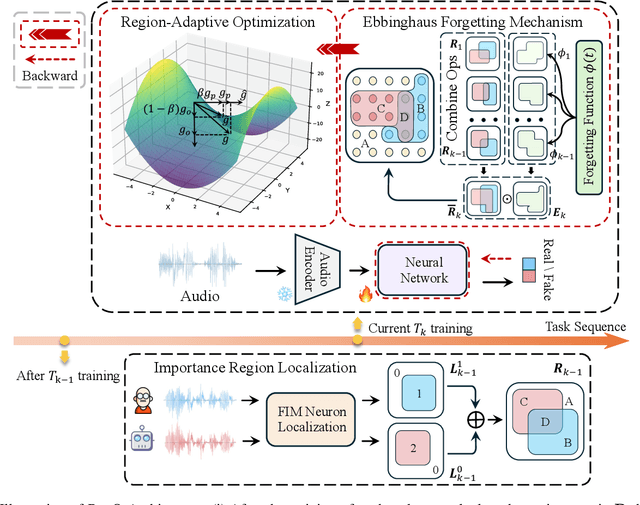
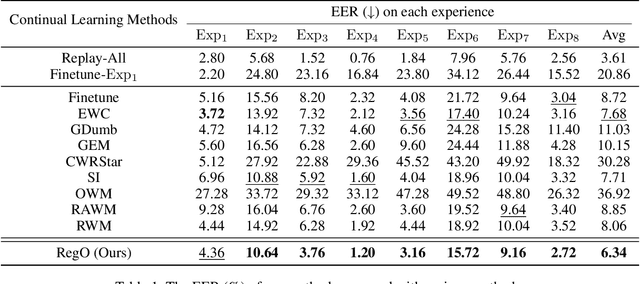
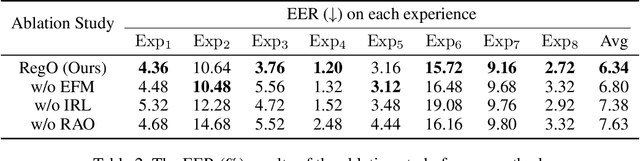
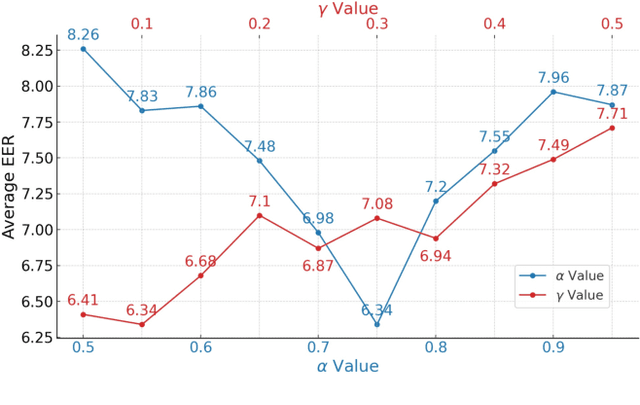
Rapid advancements in speech synthesis and voice conversion bring convenience but also new security risks, creating an urgent need for effective audio deepfake detection. Although current models perform well, their effectiveness diminishes when confronted with the diverse and evolving nature of real-world deepfakes. To address this issue, we propose a continual learning method named Region-Based Optimization (RegO) for audio deepfake detection. Specifically, we use the Fisher information matrix to measure important neuron regions for real and fake audio detection, dividing them into four regions. First, we directly fine-tune the less important regions to quickly adapt to new tasks. Next, we apply gradient optimization in parallel for regions important only to real audio detection, and in orthogonal directions for regions important only to fake audio detection. For regions that are important to both, we use sample proportion-based adaptive gradient optimization. This region-adaptive optimization ensures an appropriate trade-off between memory stability and learning plasticity. Additionally, to address the increase of redundant neurons from old tasks, we further introduce the Ebbinghaus forgetting mechanism to release them, thereby promoting the capability of the model to learn more generalized discriminative features. Experimental results show our method achieves a 21.3% improvement in EER over the state-of-the-art continual learning approach RWM for audio deepfake detection. Moreover, the effectiveness of RegO extends beyond the audio deepfake detection domain, showing potential significance in other tasks, such as image recognition. The code is available at https://github.com/cyjie429/RegO
WMCodec: End-to-End Neural Speech Codec with Deep Watermarking for Authenticity Verification
Sep 18, 2024
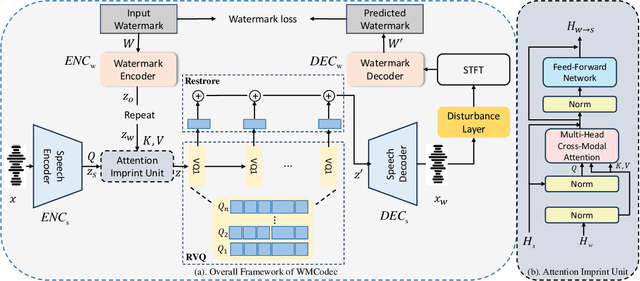
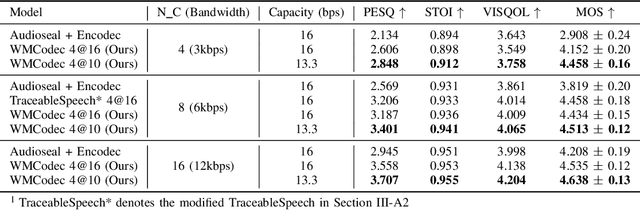
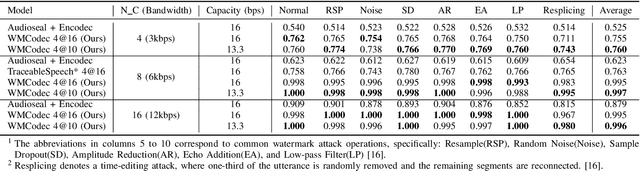
Recent advances in speech spoofing necessitate stronger verification mechanisms in neural speech codecs to ensure authenticity. Current methods embed numerical watermarks before compression and extract them from reconstructed speech for verification, but face limitations such as separate training processes for the watermark and codec, and insufficient cross-modal information integration, leading to reduced watermark imperceptibility, extraction accuracy, and capacity. To address these issues, we propose WMCodec, the first neural speech codec to jointly train compression-reconstruction and watermark embedding-extraction in an end-to-end manner, optimizing both imperceptibility and extractability of the watermark. Furthermore, We design an iterative Attention Imprint Unit (AIU) for deeper feature integration of watermark and speech, reducing the impact of quantization noise on the watermark. Experimental results show WMCodec outperforms AudioSeal with Encodec in most quality metrics for watermark imperceptibility and consistently exceeds both AudioSeal with Encodec and reinforced TraceableSpeech in extraction accuracy of watermark. At bandwidth of 6 kbps with a watermark capacity of 16 bps, WMCodec maintains over 99% extraction accuracy under common attacks, demonstrating strong robustness.
ADD 2023: Towards Audio Deepfake Detection and Analysis in the Wild
Aug 09, 2024



The growing prominence of the field of audio deepfake detection is driven by its wide range of applications, notably in protecting the public from potential fraud and other malicious activities, prompting the need for greater attention and research in this area. The ADD 2023 challenge goes beyond binary real/fake classification by emulating real-world scenarios, such as the identification of manipulated intervals in partially fake audio and determining the source responsible for generating any fake audio, both with real-life implications, notably in audio forensics, law enforcement, and construction of reliable and trustworthy evidence. To further foster research in this area, in this article, we describe the dataset that was used in the fake game, manipulation region location and deepfake algorithm recognition tracks of the challenge. We also focus on the analysis of the technical methodologies by the top-performing participants in each task and note the commonalities and differences in their approaches. Finally, we discuss the current technical limitations as identified through the technical analysis, and provide a roadmap for future research directions. The dataset is available for download.
TraceableSpeech: Towards Proactively Traceable Text-to-Speech with Watermarking
Jun 07, 2024



Various threats posed by the progress in text-to-speech (TTS) have prompted the need to reliably trace synthesized speech. However, contemporary approaches to this task involve adding watermarks to the audio separately after generation, a process that hurts both speech quality and watermark imperceptibility. In addition, these approaches are limited in robustness and flexibility. To address these problems, we propose TraceableSpeech, a novel TTS model that directly generates watermarked speech, improving watermark imperceptibility and speech quality. Furthermore, We design the frame-wise imprinting and extraction of watermarks, achieving higher robustness against resplicing attacks and temporal flexibility in operation. Experimental results show that TraceableSpeech outperforms the strong baseline where VALL-E or HiFicodec individually uses WavMark in watermark imperceptibility, speech quality and resilience against resplicing attacks. It also can apply to speech of various durations.
Distinguishing Neural Speech Synthesis Models Through Fingerprints in Speech Waveforms
Sep 13, 2023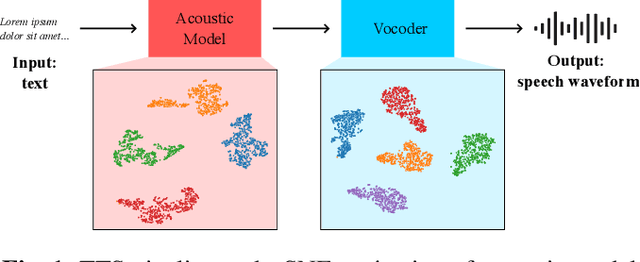


Recent strides in neural speech synthesis technologies, while enjoying widespread applications, have nonetheless introduced a series of challenges, spurring interest in the defence against the threat of misuse and abuse. Notably, source attribution of synthesized speech has value in forensics and intellectual property protection, but prior work in this area has certain limitations in scope. To address the gaps, we present our findings concerning the identification of the sources of synthesized speech in this paper. We investigate the existence of speech synthesis model fingerprints in the generated speech waveforms, with a focus on the acoustic model and the vocoder, and study the influence of each component on the fingerprint in the overall speech waveforms. Our research, conducted using the multi-speaker LibriTTS dataset, demonstrates two key insights: (1) vocoders and acoustic models impart distinct, model-specific fingerprints on the waveforms they generate, and (2) vocoder fingerprints are the more dominant of the two, and may mask the fingerprints from the acoustic model. These findings strongly suggest the existence of model-specific fingerprints for both the acoustic model and the vocoder, highlighting their potential utility in source identification applications.
Audio Deepfake Detection: A Survey
Aug 29, 2023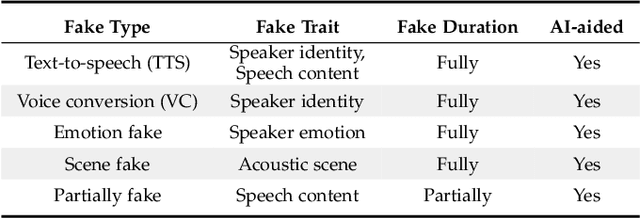
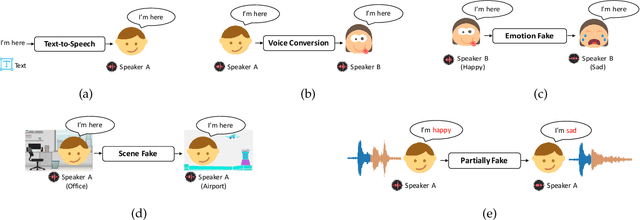
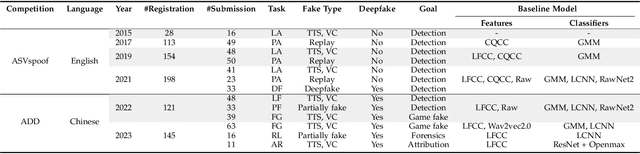
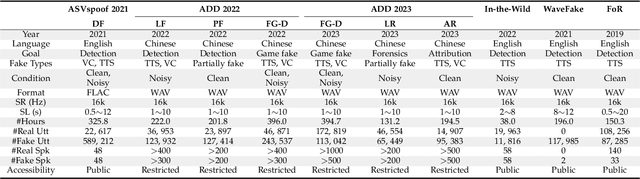
Audio deepfake detection is an emerging active topic. A growing number of literatures have aimed to study deepfake detection algorithms and achieved effective performance, the problem of which is far from being solved. Although there are some review literatures, there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences across various types of deepfake audio, then outline and analyse competitions, datasets, features, classifications, and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are discussed. In addition, we perform a unified comparison of representative features and classifiers on ASVspoof 2021, ADD 2023 and In-the-Wild datasets for audio deepfake detection, respectively. The survey shows that future research should address the lack of large scale datasets in the wild, poor generalization of existing detection methods to unknown fake attacks, as well as interpretability of detection results.
ADD 2023: the Second Audio Deepfake Detection Challenge
May 23, 2023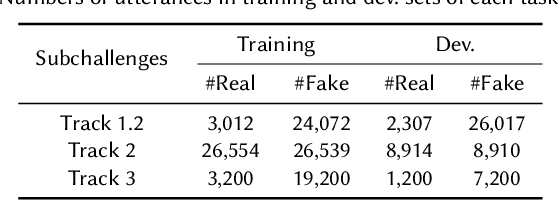
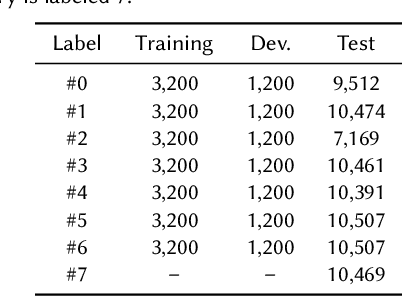
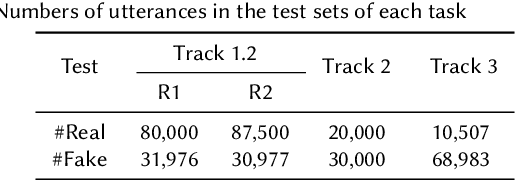

Audio deepfake detection is an emerging topic in the artificial intelligence community. The second Audio Deepfake Detection Challenge (ADD 2023) aims to spur researchers around the world to build new innovative technologies that can further accelerate and foster research on detecting and analyzing deepfake speech utterances. Different from previous challenges (e.g. ADD 2022), ADD 2023 focuses on surpassing the constraints of binary real/fake classification, and actually localizing the manipulated intervals in a partially fake speech as well as pinpointing the source responsible for generating any fake audio. Furthermore, ADD 2023 includes more rounds of evaluation for the fake audio game sub-challenge. The ADD 2023 challenge includes three subchallenges: audio fake game (FG), manipulation region location (RL) and deepfake algorithm recognition (AR). This paper describes the datasets, evaluation metrics, and protocols. Some findings are also reported in audio deepfake detection tasks.
Emotion Selectable End-to-End Text-based Speech Editing
Dec 20, 2022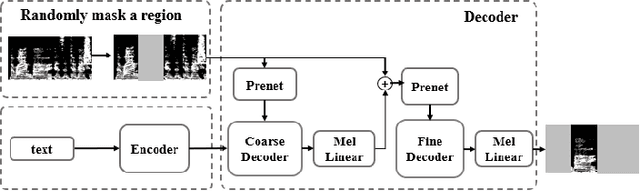
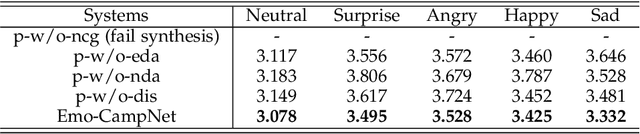
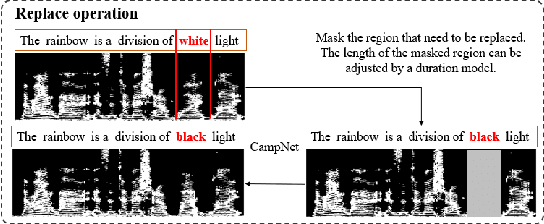
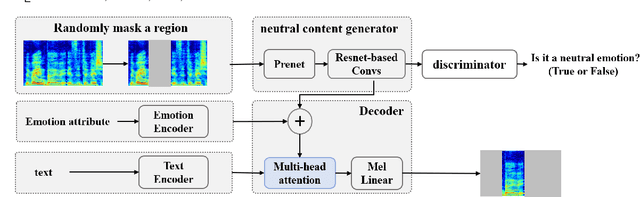
Text-based speech editing allows users to edit speech by intuitively cutting, copying, and pasting text to speed up the process of editing speech. In the previous work, CampNet (context-aware mask prediction network) is proposed to realize text-based speech editing, significantly improving the quality of edited speech. This paper aims at a new task: adding emotional effect to the editing speech during the text-based speech editing to make the generated speech more expressive. To achieve this task, we propose Emo-CampNet (emotion CampNet), which can provide the option of emotional attributes for the generated speech in text-based speech editing and has the one-shot ability to edit unseen speakers' speech. Firstly, we propose an end-to-end emotion-selectable text-based speech editing model. The key idea of the model is to control the emotion of generated speech by introducing additional emotion attributes based on the context-aware mask prediction network. Secondly, to prevent the emotion of the generated speech from being interfered by the emotional components in the original speech, a neutral content generator is proposed to remove the emotion from the original speech, which is optimized by the generative adversarial framework. Thirdly, two data augmentation methods are proposed to enrich the emotional and pronunciation information in the training set, which can enable the model to edit the unseen speaker's speech. The experimental results that 1) Emo-CampNet can effectively control the emotion of the generated speech in the process of text-based speech editing; And can edit unseen speakers' speech. 2) Detailed ablation experiments further prove the effectiveness of emotional selectivity and data augmentation methods. The demo page is available at https://hairuo55.github.io/Emo-CampNet/
EmoFake: An Initial Dataset for Emotion Fake Audio Detection
Nov 11, 2022
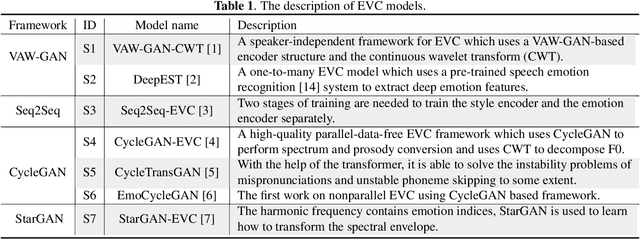

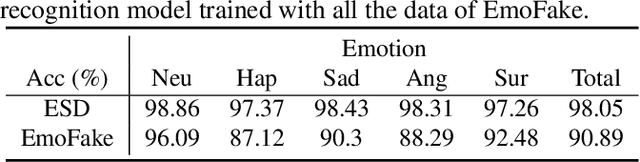
There are already some datasets used for fake audio detection, such as the ASVspoof and ADD datasets. However, these databases do not consider a situation that the emotion of the audio has been changed from one to another, while other information (e.g. speaker identity and content) remains the same. Changing emotions often leads to semantic changes. This may be a great threat to social stability. Therefore, this paper reports our progress in developing such an emotion fake audio detection dataset involving changing emotion state of the original audio. The dataset is named EmoFake. The fake audio in EmoFake is generated using the state-of-the-art emotion voice conversion models. Some benchmark experiments are conducted on this dataset. The results show that our designed dataset poses a challenge to the LCNN and RawNet2 baseline models of ASVspoof 2021.