 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoFake: An Initial Dataset for Emotion Fake Audio Detection
Paper and Code

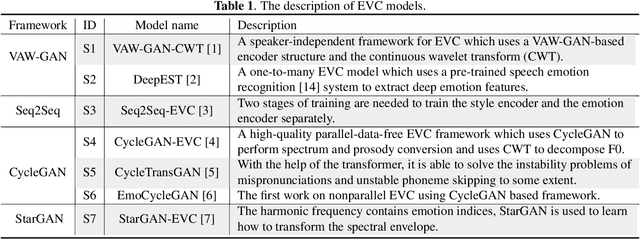

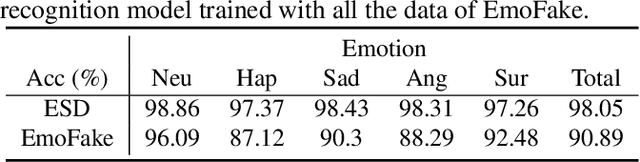
There are already some datasets used for fake audio detection, such as the ASVspoof and ADD datasets. However, these databases do not consider a situation that the emotion of the audio has been changed from one to another, while other information (e.g. speaker identity and content) remains the same. Changing emotions often leads to semantic changes. This may be a great threat to social stability. Therefore, this paper reports our progress in developing such an emotion fake audio detection dataset involving changing emotion state of the original audio. The dataset is named EmoFake. The fake audio in EmoFake is generated using the state-of-the-art emotion voice conversion models. Some benchmark experiments are conducted on this dataset. The results show that our designed dataset poses a challenge to the LCNN and RawNet2 baseline models of ASVspoof 2021.