 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Generalization via Structuralizing Concept and Feature Space into Commonality, Specificity and Confounding
Jan 06, 2026Fine-Grained Domain Generalization (FGDG) presents greater challenges than conventional domain generalization due to the subtle inter-class differences and relatively pronounced intra-class variations inherent in fine-grained recognition tasks. Under domain shifts, the model becomes overly sensitive to fine-grained cues, leading to the suppression of critical features and a significant drop in performance. Cognitive studies suggest that humans classify objects by leveraging both common and specific attributes, enabling accurate differentiation between fine-grained categories. However, current deep learning models have yet to incorporate this mechanism effectively. Inspired by this mechanism, we propose Concept-Feature Structuralized Generalization (CFSG). This model explicitly disentangles both the concept and feature spaces into three structured components: common, specific, and confounding segments. To mitigate the adverse effects of varying degrees of distribution shift, we introduce an adaptive mechanism that dynamically adjusts the proportions of common, specific, and confounding components. In the final prediction, explicit weights are assigned to each pair of components. Extensive experiments on three single-source benchmark datasets demonstrate that CFSG achieves an average performance improvement of 9.87% over baseline models and outperforms existing state-of-the-art methods by an average of 3.08%. Additionally, explainability analysis validates that CFSG effectively integrates multi-granularity structured knowledge and confirms that feature structuralization facilitates the emergence of concept structuralization.
Adaptive Decision Boundary for Few-Shot Class-Incremental Learning
Apr 15, 2025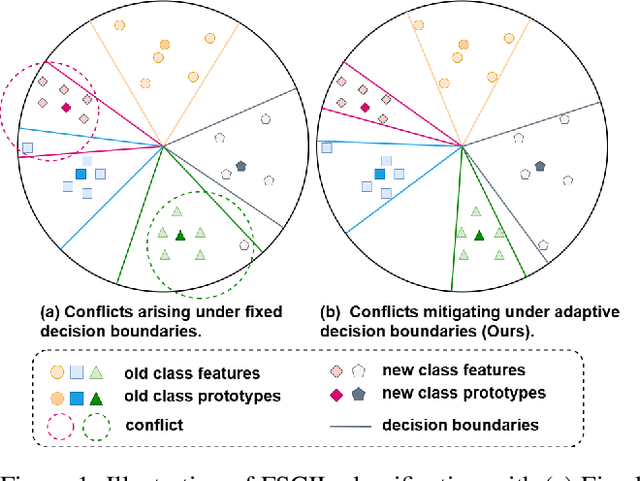
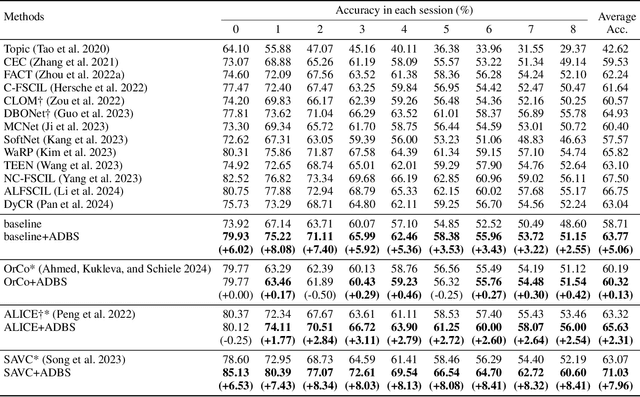
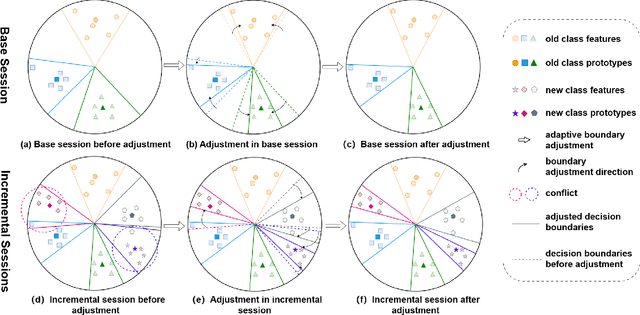
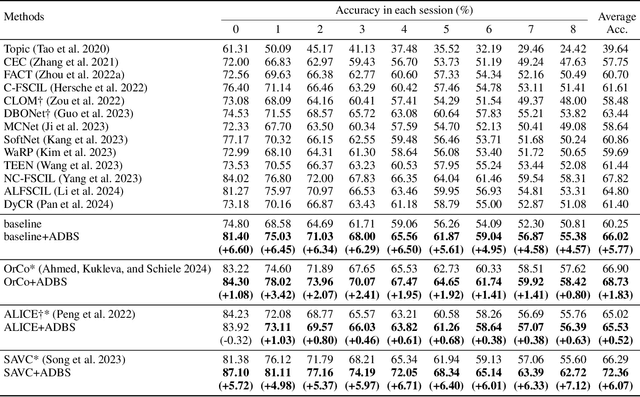
Few-Shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes from a limited set of training samples without forgetting knowledge of previously learned classes. Conventional FSCIL methods typically build a robust feature extractor during the base training session with abundant training samples and subsequently freeze this extractor, only fine-tuning the classifier in subsequent incremental phases. However, current strategies primarily focus on preventing catastrophic forgetting, considering only the relationship between novel and base classes, without paying attention to the specific decision spaces of each class. To address this challenge, we propose a plug-and-play Adaptive Decision Boundary Strategy (ADBS), which is compatible with most FSCIL methods. Specifically, we assign a specific decision boundary to each class and adaptively adjust these boundaries during training to optimally refine the decision spaces for the classes in each session. Furthermore, to amplify the distinctiveness between classes, we employ a novel inter-class constraint loss that optimizes the decision boundaries and prototypes for each class. Extensive experiments on three benchmarks, namely CIFAR100, miniImageNet, and CUB200, demonstrate that incorporating our ADBS method with existing FSCIL techniques significantly improves performance, achieving overall state-of-the-art results.
EmoFake: An Initial Dataset for Emotion Fake Audio Detection
Nov 11, 2022
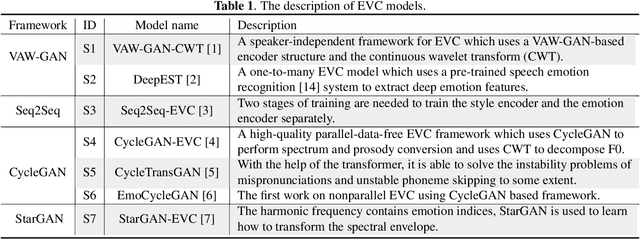

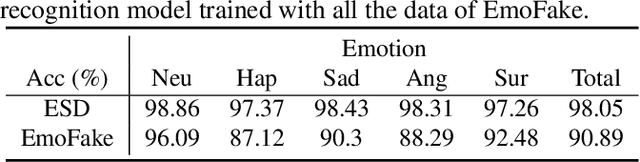
There are already some datasets used for fake audio detection, such as the ASVspoof and ADD datasets. However, these databases do not consider a situation that the emotion of the audio has been changed from one to another, while other information (e.g. speaker identity and content) remains the same. Changing emotions often leads to semantic changes. This may be a great threat to social stability. Therefore, this paper reports our progress in developing such an emotion fake audio detection dataset involving changing emotion state of the original audio. The dataset is named EmoFake. The fake audio in EmoFake is generated using the state-of-the-art emotion voice conversion models. Some benchmark experiments are conducted on this dataset. The results show that our designed dataset poses a challenge to the LCNN and RawNet2 baseline models of ASVspoof 2021.
Interactive Model with Structural Loss for Language-based Abductive Reasoning
Dec 01, 2021

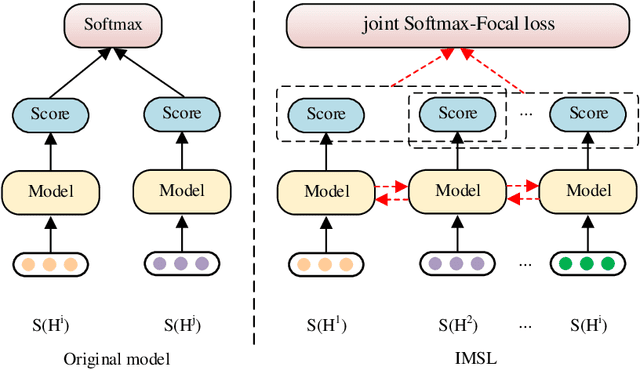

The abductive natural language inference task ($\alpha$NLI) is proposed to infer the most plausible explanation between the cause and the event. In the $\alpha$NLI task, two observations are given, and the most plausible hypothesis is asked to pick out from the candidates. Existing methods model the relation between each candidate hypothesis separately and penalize the inference network uniformly. In this paper, we argue that it is unnecessary to distinguish the reasoning abilities among correct hypotheses; and similarly, all wrong hypotheses contribute the same when explaining the reasons of the observations. Therefore, we propose to group instead of ranking the hypotheses and design a structural loss called ``joint softmax focal loss'' in this paper. Based on the observation that the hypotheses are generally semantically related, we have designed a novel interactive language model aiming at exploiting the rich interaction among competing hypotheses. We name this new model for $\alpha$NLI: Interactive Model with Structural Loss (IMSL). The experimental results show that our IMSL has achieved the highest performance on the RoBERTa-large pretrained model, with ACC and AUC results increased by about 1\% and 5\% respectively.